llm es una utilidad imprescindible en tu arsenal de comandos. Permite acceder desde la terminal a cualquier LLM, integrándose como un comando Unix más.
groq es una empresa que ofrece acceso a llama3 a través de su API, ejecutándose en sus veloces LPUs, de forma gratuita. Uno de los modelos más potentes que ofrece es llama-3-3-70b
Para poder usar llama3.3-70b desde el comando llm a través de groq, es necesario instalar el plugin llm-groq, por el momento a través del HEAD en su repo GitHub
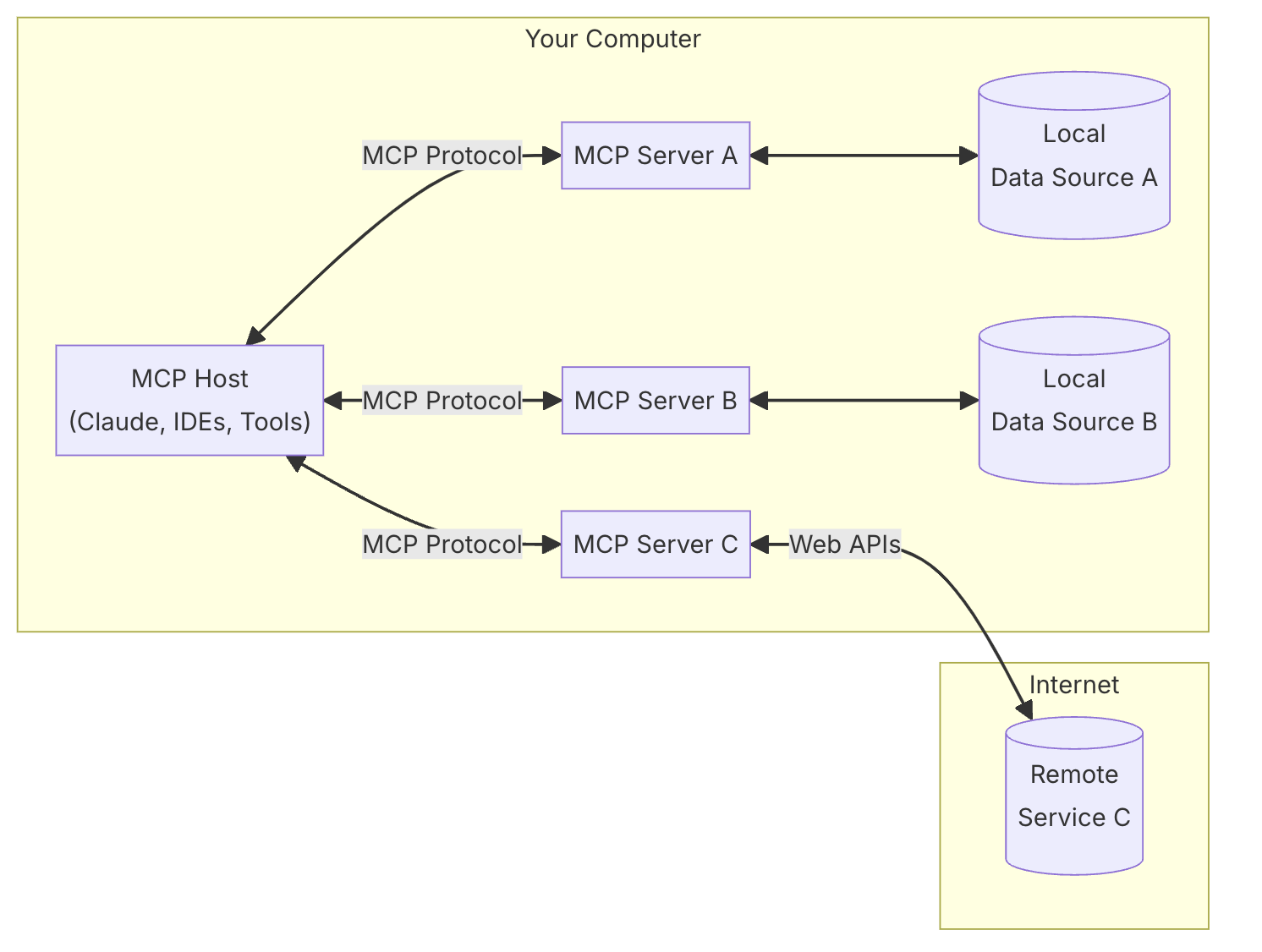
El Model Context Protocol (MCP) es un estándar abierto, ideado por Anthropic, que busca hacer más sencillo y práctico conectar tus aplicaciones con los LLM. Imagina que tienes un asistente inteligente y quieres que pueda hablar con todas las herramientas y bases de datos que usas sin volverte loco configurando cada cosa; eso es lo que MCP hace por ti.
En la siguiente figura vemos que podemos tener distintos servicios MCP (ofreciendo por ejemplo conexión con una base de datos sqlite, con el sistema de archivos, con GitHub, etc.) y un cliente (host) que hace uso de dichos servicios (por ejemplo, Claude, a través de Claude Desktop, por ahora uno de los pocos clientes compatibles). Durante la preview, los servicios MCP deben estar ejecutándose en local, aunque Anthropic está trabajando para que en breve podamos usar servicios MCP remotos.
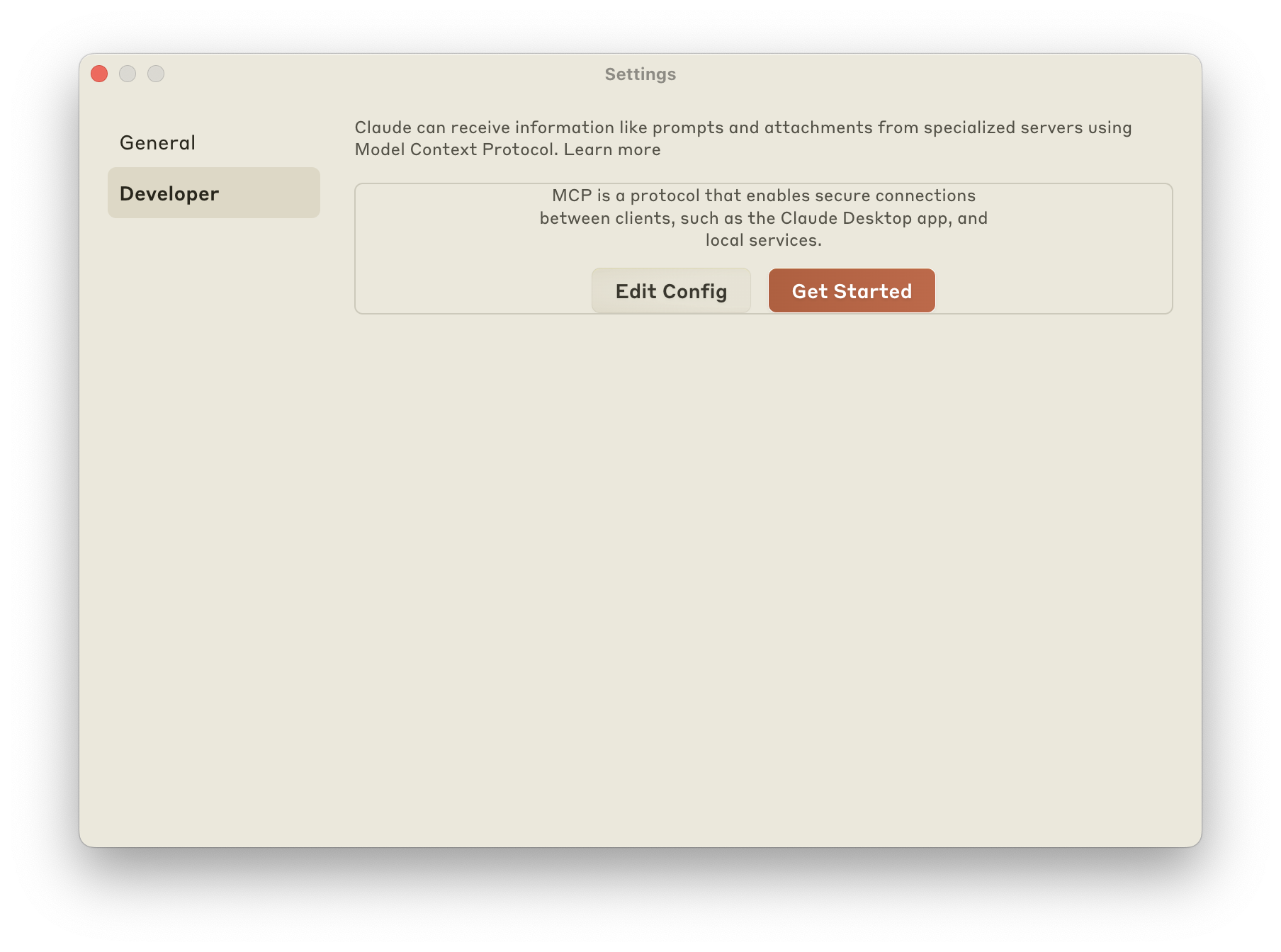
Veamos cómo configurar Claude Desktop (un cliente MCP) para que sepa hablar con una base de datos Sqlite.
Lo primero, desde Claude / Settings / Developer, pulsa en «Edit Config»
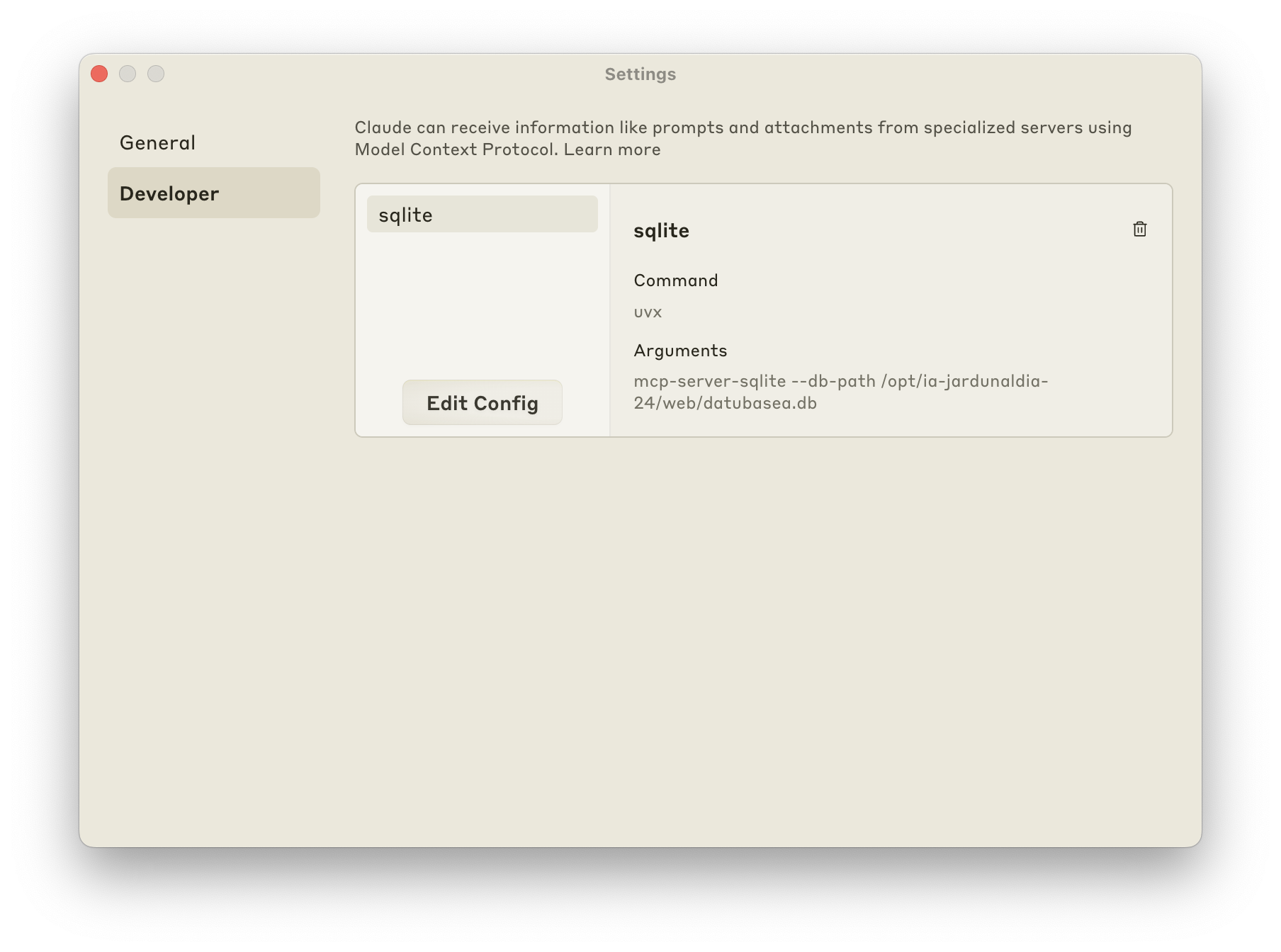
Cierra Claude Desktop y vuélvelo a abrir. Entra de nuevo en Settings / Developer. Deberías ver lo siguiente:
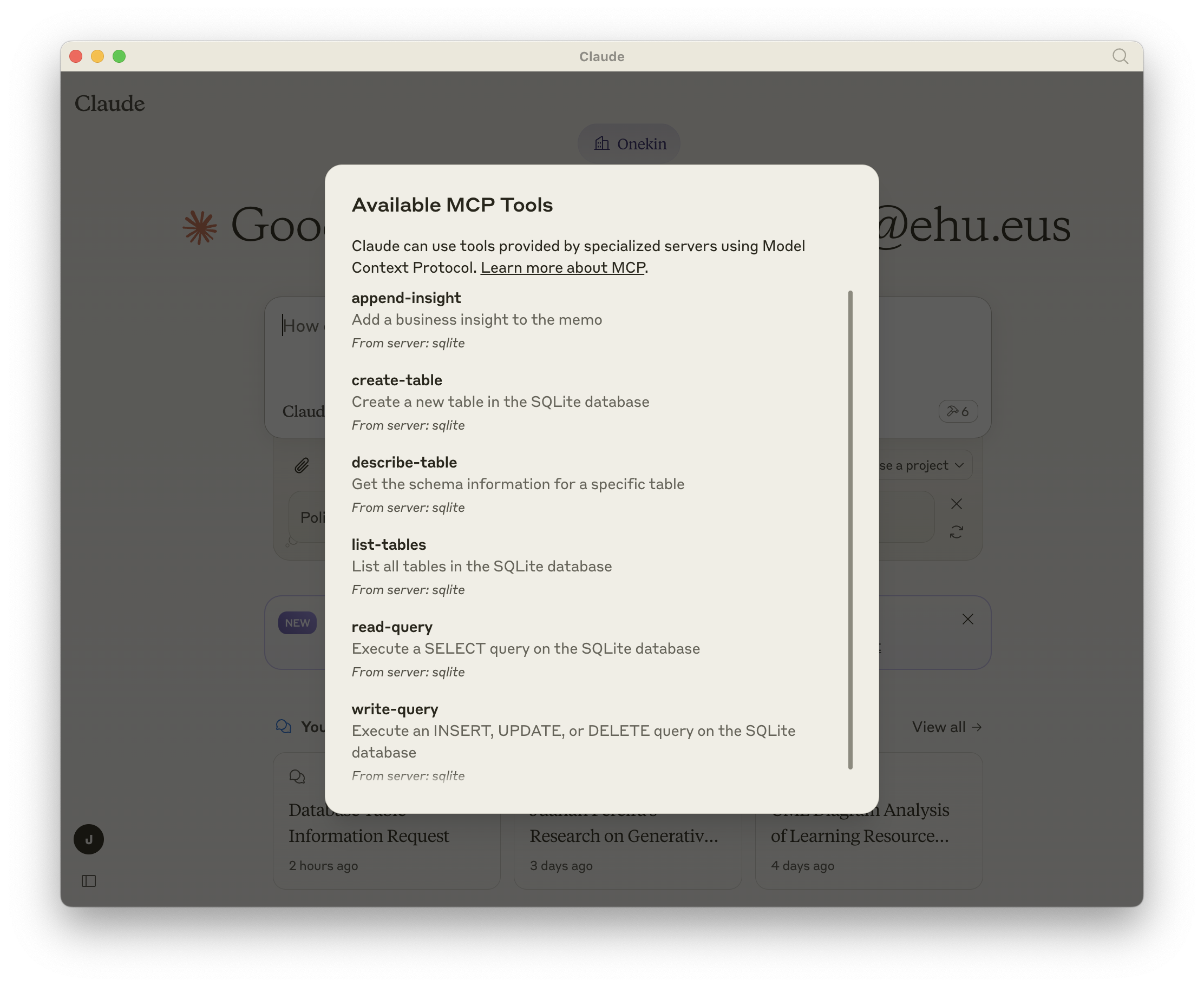
Y si abres un nuevo chat, tendrías que ver 6 tools disponibles:
Ahora podemos hacerle preguntas a Claude al respecto de la BBDD sqlite, por ejemplo:
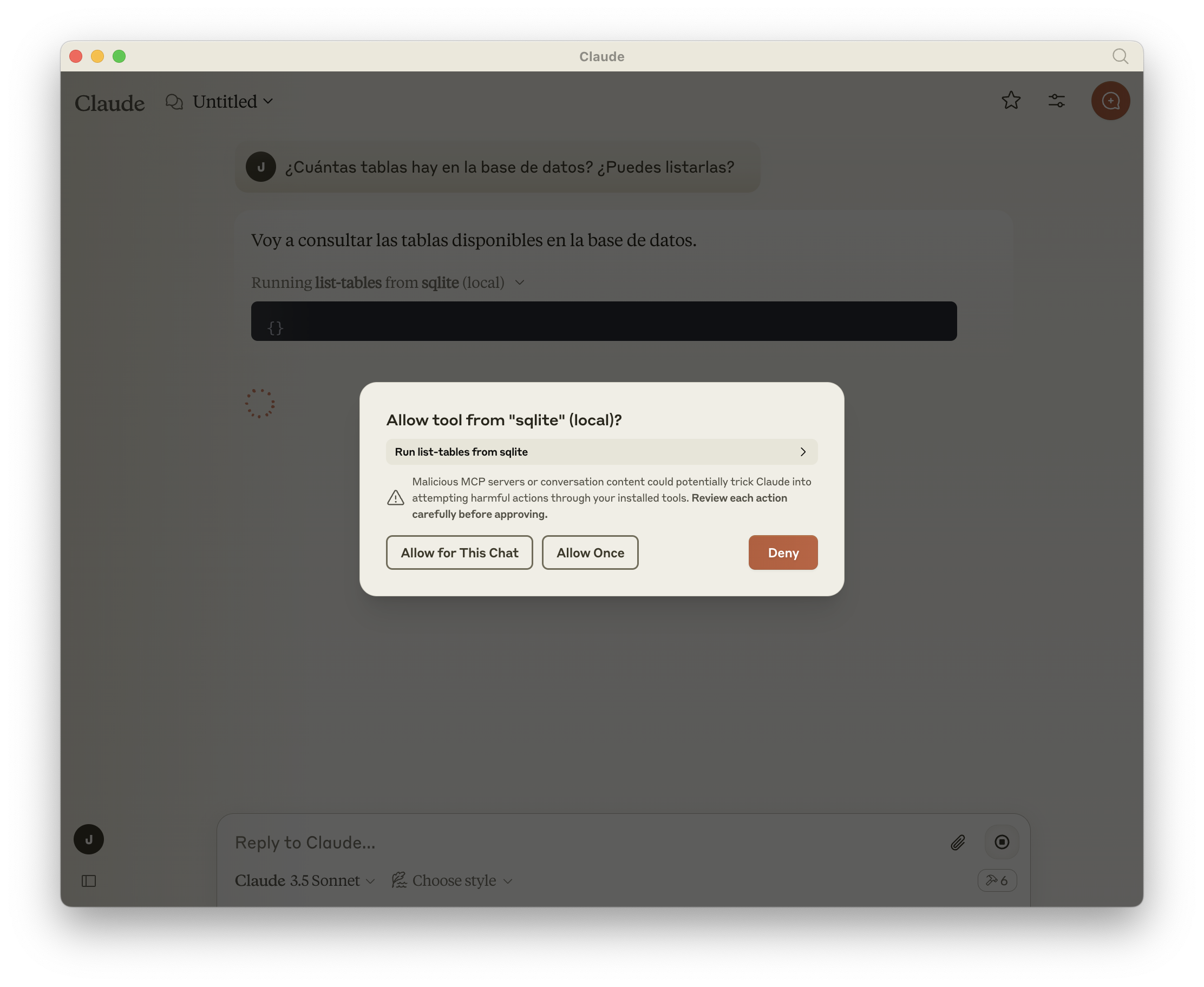
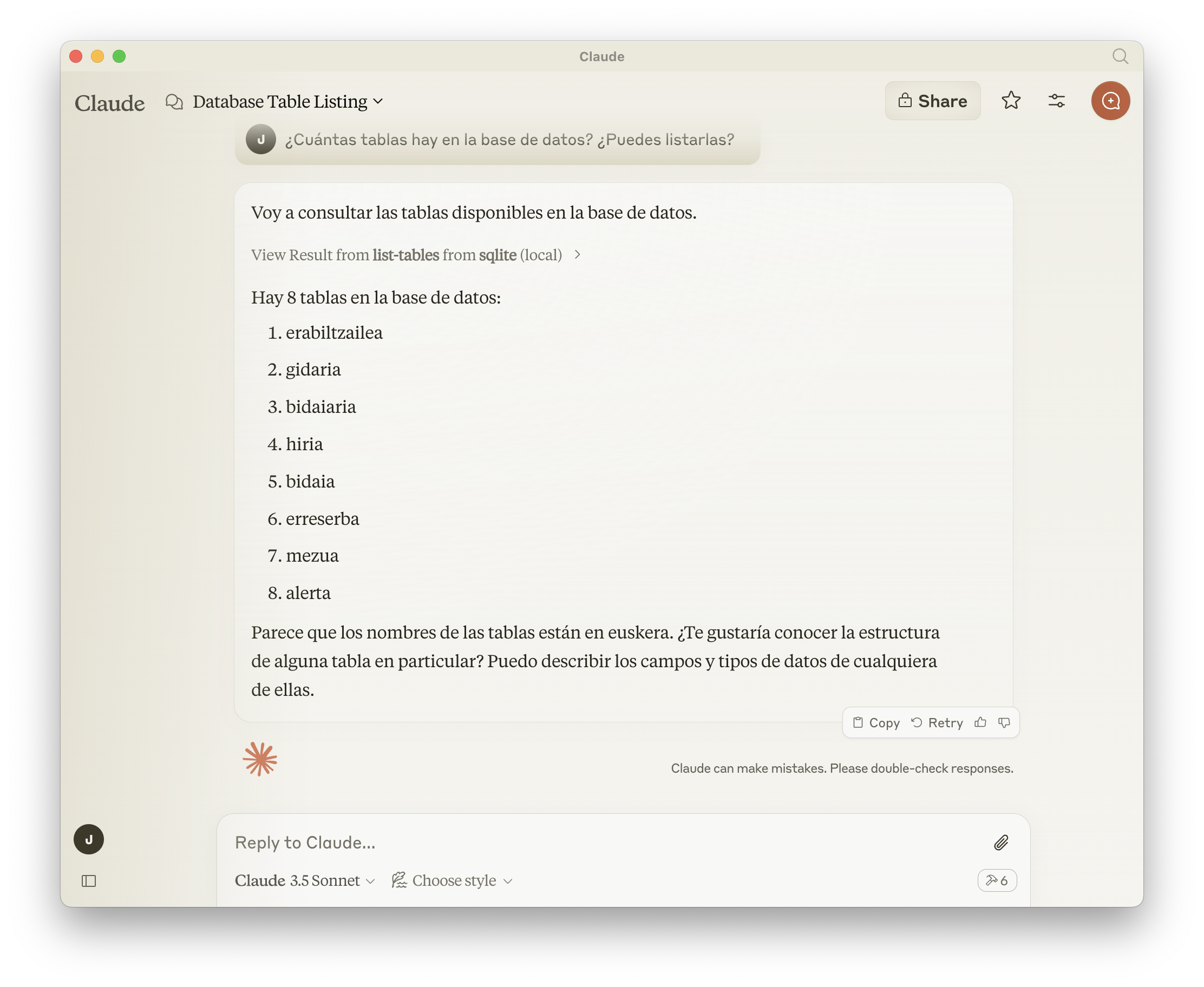
¿Cuántas tablas hay en la base de datos? ¿Puedes listarlas?
La primera vez Claude te pedirá permiso de ejecución:
Y a continuación ejecutará el comando list-tables disponible a través de MCP: (y efectivamente, las tablas que le he pasado están en un sqlite de un proyecto en Euskera 🙂
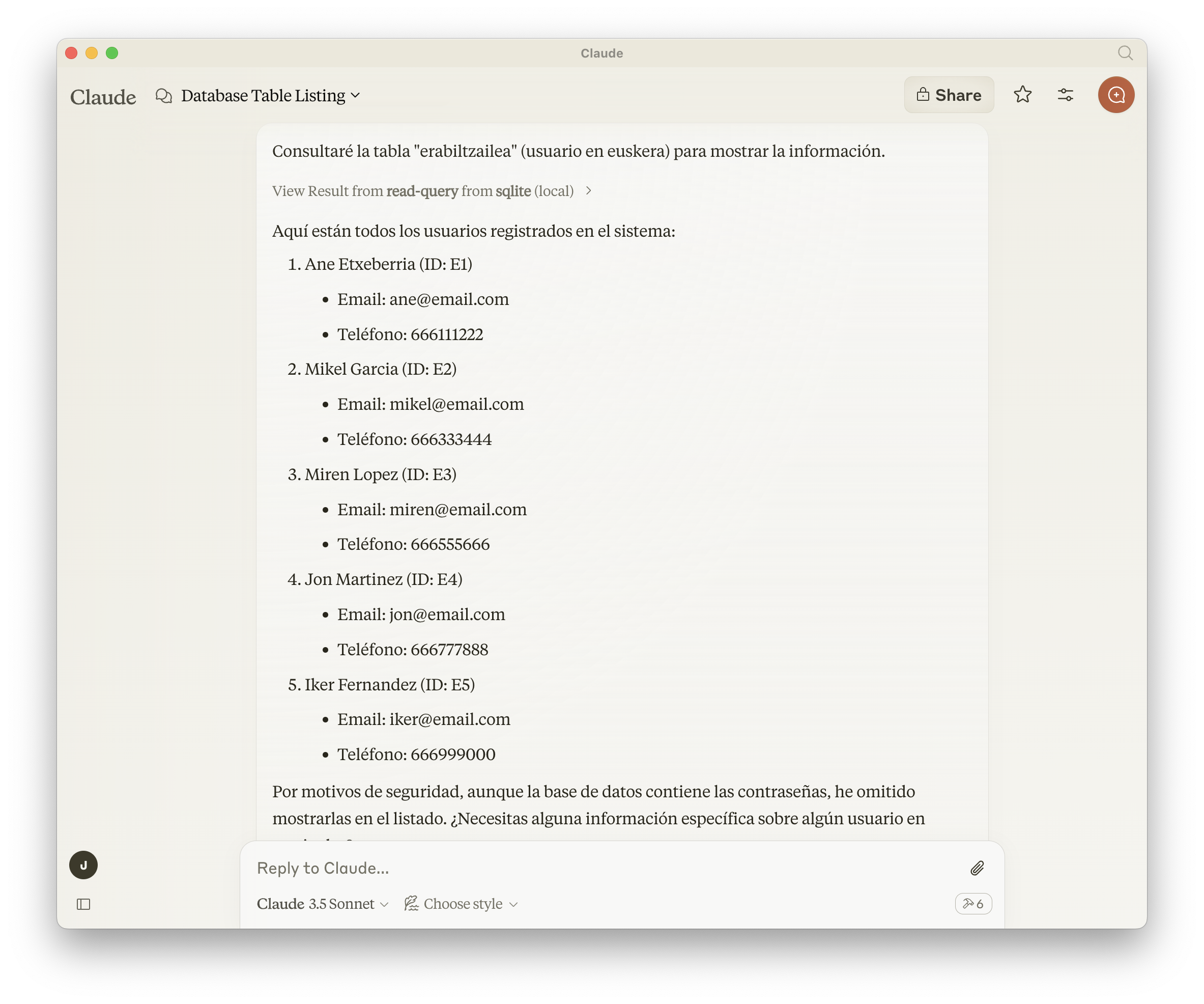
Podemos pedir que nos liste los usuarios (tabla erabiltzailea):
Es curioso el último párrafo, donde se niega a mostrar el contenido de la columna de passwords por motivos de seguridad.
Debugging
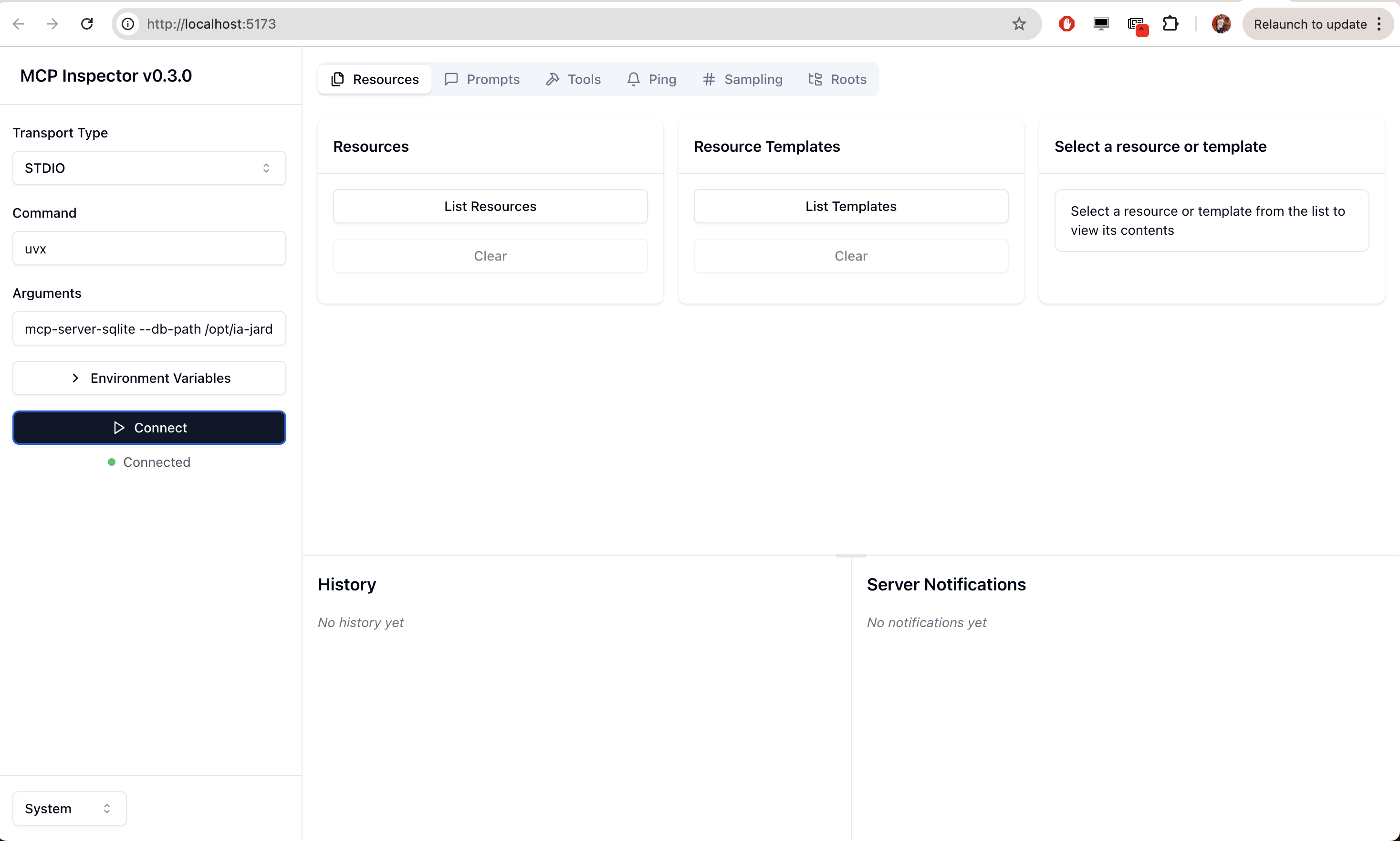
MCP ofrece una herramienta web llamada mcp-inspector que nos permite depurar un servicio MCP desde el navegador. Por ejemplo, si quisiéramos ver qué ofrece el servidor mcp-server-sqlite, podríamos lanzar el siguiente comando:
Desde donde podríamos ver los recursos ofrecidor por ese servidor:
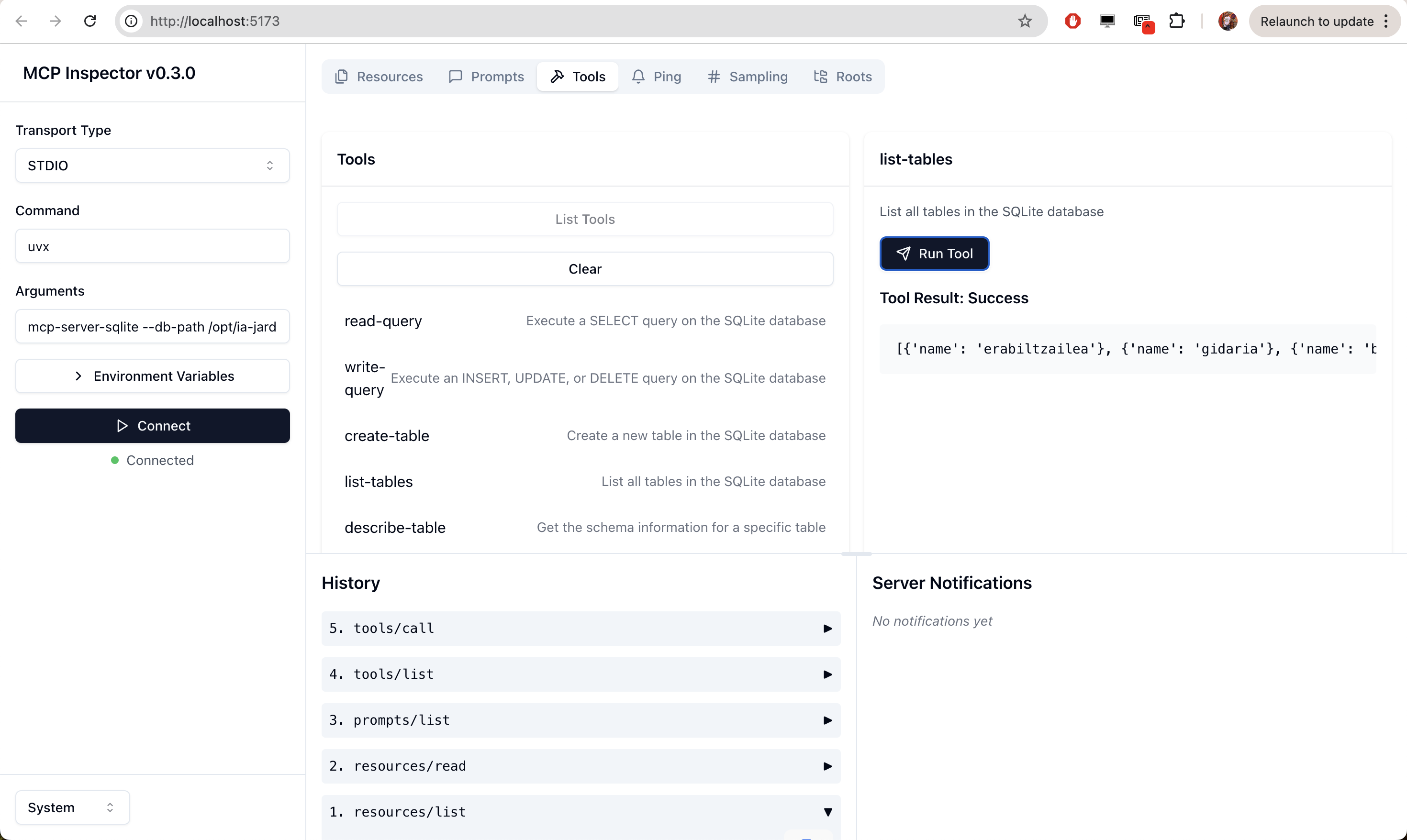
Por ejemplo, probar las herramientas desde el navegador, así:
Troubleshooting
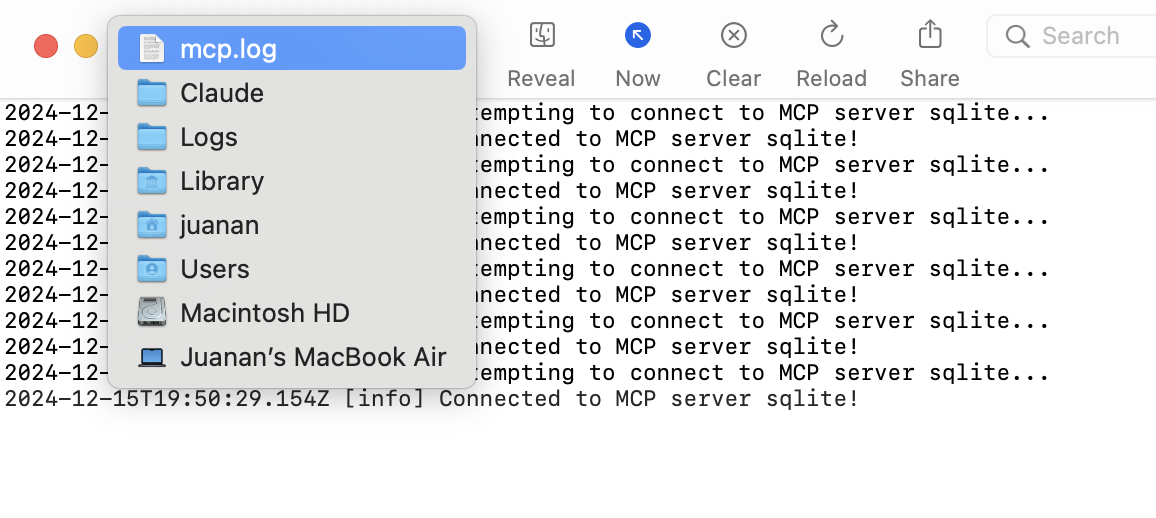
Si no te sale el icono de MCP en el chat, prueba lo siguiente.
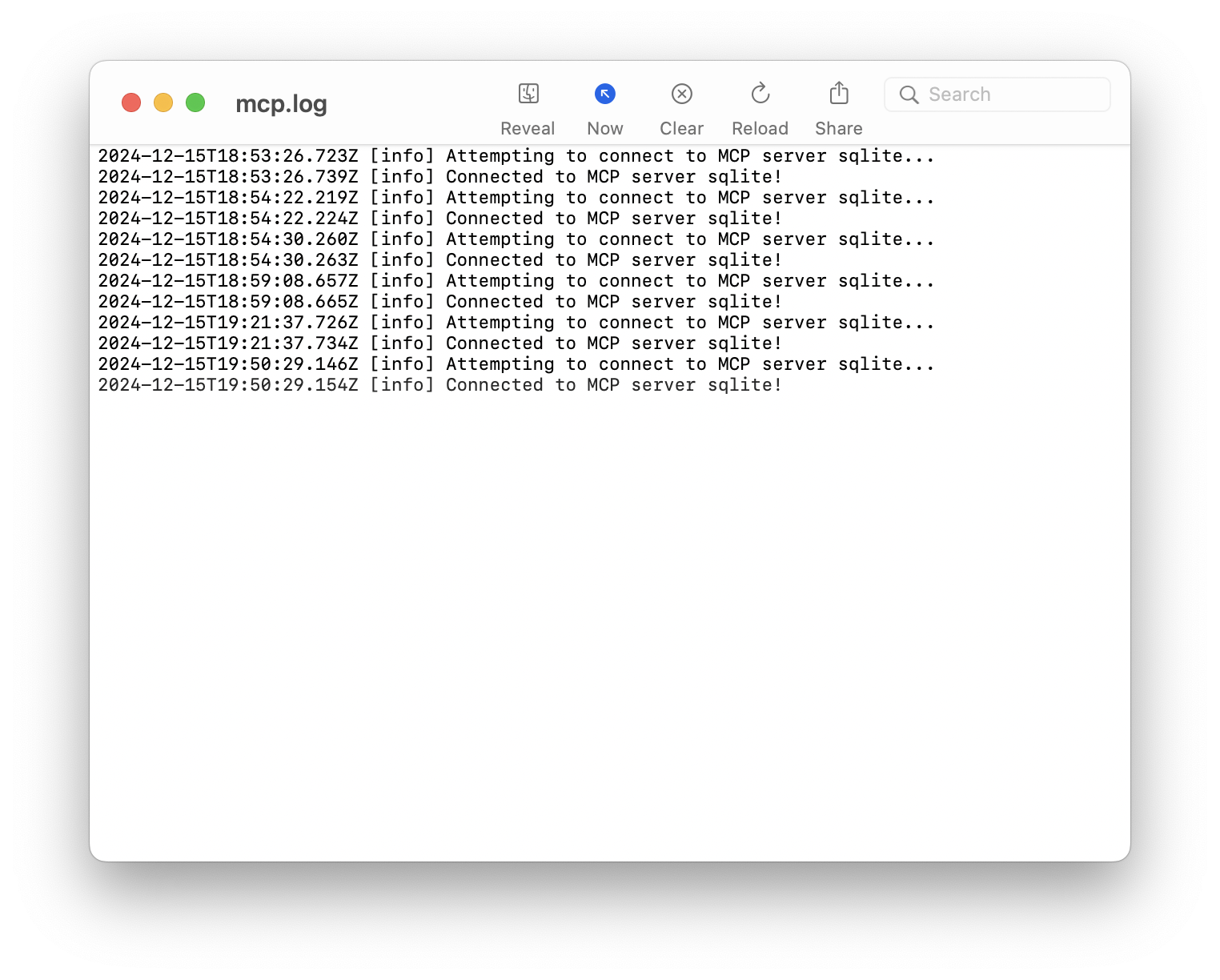
Activa el Developer Mode para ver los logs de MCP:
Te mostrará por defecto el mcp.log. Pero si pulsas sobre el nombre con Cmd+Click izq. verás la ruta a ese log:
Y en ~/Library/Logs/Claude, verás también el fichero mcp-server-sqlite.log
En mi caso, tuve el siguiente problema:
Dado que mcp-server-sqlite requiere una versión de Python superior a la 3.9.13 (la que tengo por defecto en un equipo) es necesario especificar la ruta a un Python más moderno (3.12.14 en mi caso) en el JSON de configuración, así:
Quería ejecutar la siguiente instrucción en SQLite
ALTER TABLE staff
ADD COLUMN IF NOT EXISTS username TEXT NOT NULL DEFAULT "";
pero SQLite no soporta la claúsula IF NOT EXISTS en ADD COLUMN.
Así que le pedí sugerencias a Claude 3.5 Sonnet y GPT-4o.
Ambos estaban de acuerdo en que esto funcionaría:
BEGIN TRANSACTION;
-- Check if the username column exists, if not, add it
SELECT CASE
WHEN COUNT(*) = 0 THEN
'ALTER TABLE staff ADD COLUMN username TEXT NOT NULL DEFAULT ""'
ELSE
'SELECT 1' -- Do nothing
END
FROM pragma_table_info('staff')
WHERE name = 'username';
Parece un buen truco: se comprueba en los metadatos de SQLite a ver si existe una columna username (se cuenta cuántas veces existe) y si el conteo es 0, entonces hay que ejecutar el ADD COLUMN.
Pero, hemos sido engañados.
El SQL es sintácticamente correcto pero la orden dentro del THEN es simplemente para mostrar un string, no para ejecutar el ALTER TABLE.
Cuando te digan que los ingenieros software no existirán en 5 años, acuérdate de esto. O de esto otro:
Great illustration of how much depth there is to what we do as engineers behind just “writing code” – understanding why localhost:3000 isn’t something you can share involves understanding URLs, clients, servers, networking, DNS… https://t.co/bPbjJ5zO0N
$ file mystery_file mystery_file: SQLite 3.x database, last written using SQLite version 0, page size 1024, file counter 4, database pages 0, cookie 0x2, schema 1, UTF-8, version-valid-for 0
Es un archivo que contiene una base de datos SQLite.
$ sqlite3 mystery_file SQLite version 3.43.2 2023-10-10 13:08:14 Enter ".help" for usage hints. sqlite> .schema CREATE TABLE idx (val text); CREATE TABLE data (id integer primary key asc, val blob);
Analicemos el contenido:
sqlite> select * from idx; 1c9a44eb2e8eaf3da1eb551da310cce7 sqlite> select * from data LIMIT 3; 1|� 2|� 3|�
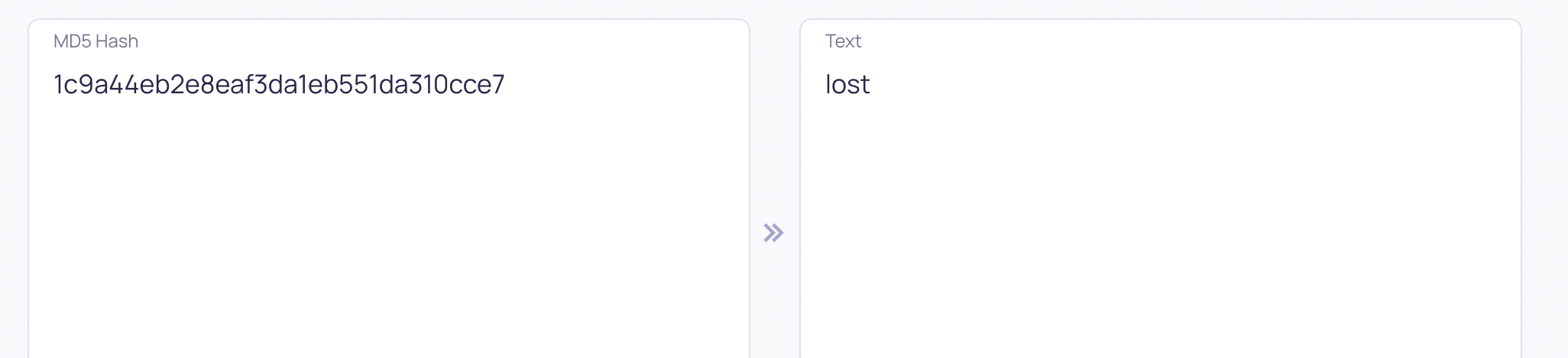
La tabla idx solo tien un columna val con una única fila: 1c9a44eb2e8eaf3da1eb551da310cce7
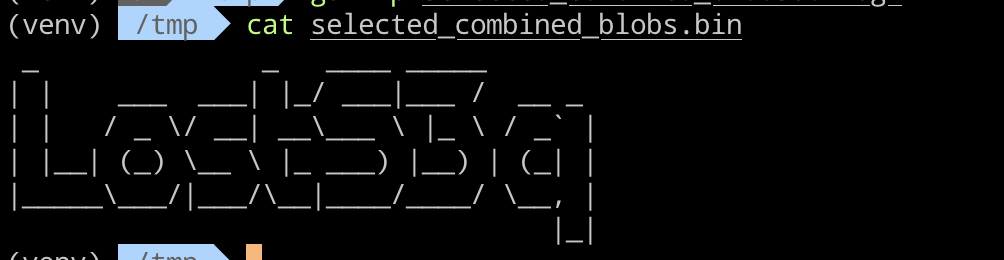
Buscando en Google, vemos que ese hash corresponde al string ‘lost’
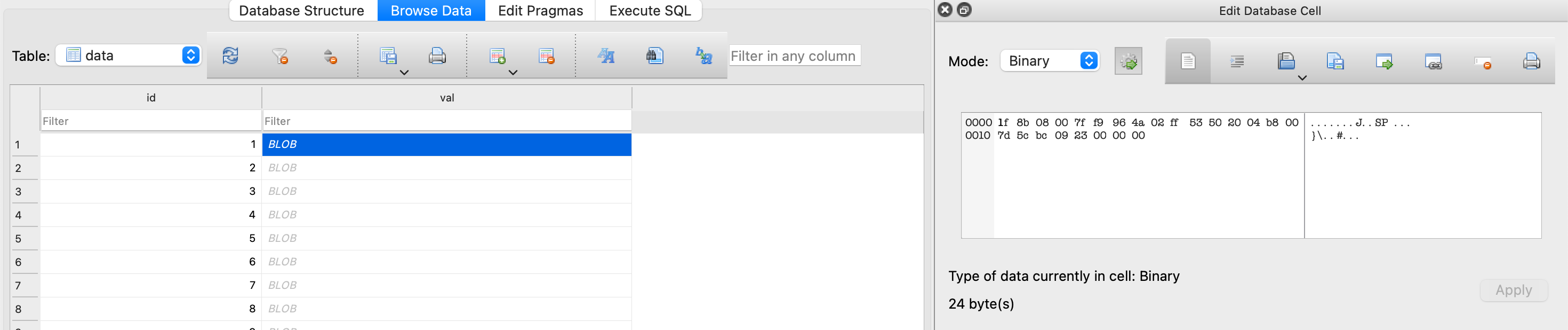
Respecto a los binarios guardados en la tabla data:
Podemos copiar esos valores hexa, convertirlos a binario y generar un fichero, que podremos analizar con el comando file:
Pare que son 100 blobs gzip. Saquemos todos ellos:
import sqlite3
# Connect to the SQLite database
conn = sqlite3.connect('mystery_file')
cursor = conn.cursor()
# Query to fetch all blobs from the data table
cursor.execute("SELECT val FROM data")
rows = cursor.fetchall()
# Concatenate all blobs into a single file
with open("combined_blobs.gz", "wb") as file:
for row in rows:
file.write(row[0])
# Close the connection
conn.close()
print("All blobs have been concatenated into 'combined_blobs.gz'.")
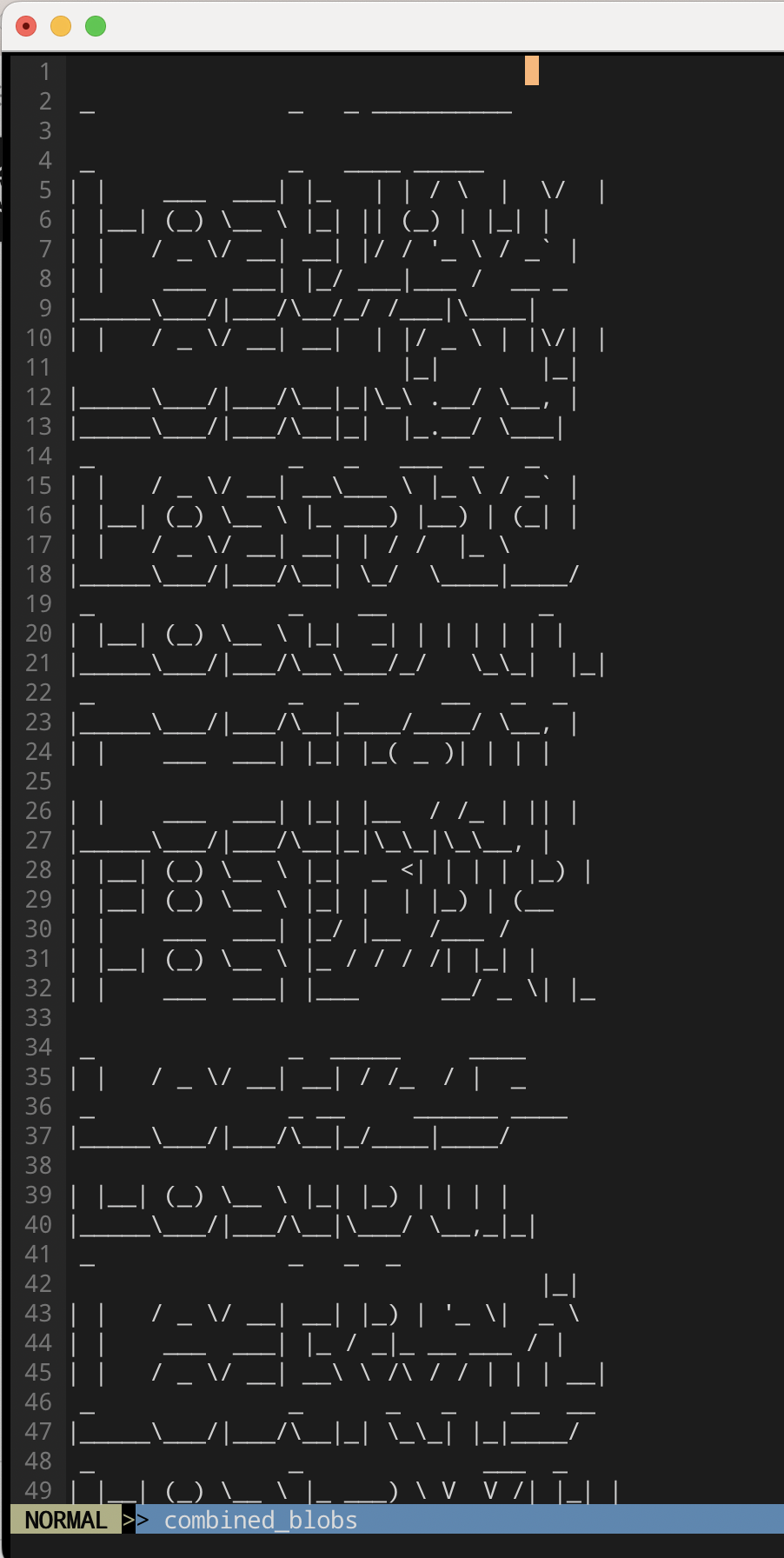
Tras descomprimir con gunzip el fichero combined_blobs.gz:
Y tratando de descifrar ese bonito ASCII art estuvimos más de 24 horas. Sacamos todas las posibles combinaciones (ordenando por longitud de cada línea y agrupando las de la misma longitud). Pero… había una forma más fácil o de idea feliz.
Resulta que si buscamos el ‘lost’ de la tabla idx con la palabra números:
Resulta que en la serie Lost esos números son recurrentes… ¿Y si sacamos los blobs en ese orden?
import sqlite3
# Connect to the SQLite database
conn = sqlite3.connect('mystery_file')
cursor = conn.cursor()
# Select the specific rows with the provided indices
indices = [4, 8, 15, 16, 23, 42]
blobs = []
for index in indices:
cursor.execute("SELECT val FROM data WHERE rowid=?", (index,))
row = cursor.fetchone()
if row is not None:
blobs.append(row[0])
# Concatenate the selected blobs into a single file
with open("selected_combined_blobs.bin", "wb") as file:
for blob in blobs:
file.write(blob)
# Close the connection
conn.close()
print("Selected blobs have been concatenated into 'selected_combined_blobs.bin'.")
Vaya… estuvimos 24 horas deambulando cuando la solución estaba a nuestro alcance con una ‘simple’ búsqueda:
Nota: Este WriteUp ha sido desarrollado por Owen, del equipo basados. ¡Muchas gracias por la colaboración! (y si alguien más quiere participar, será bienvenido 🙂
Este tercer nivel, aunque era relativamente sencillo, quizá más que el anterior, no lo han resuelto tantos equipos.
El enunciado parece ser un acertijo
“1111111111111111111 tres primos son y juntos les gusta ir”.
La primera pregunta que nos hicimos: ¿este número, interpretado como decimal, es primo? Sí, lo es.
La segunda: ¿este número, interpretado como binario, es también primo? Si lo pasamos de binario a decimal, obtenemos 524287, que también es primo.
Tenemos dos primos, nos falta el tercero. Si contamos el número de unos, observamos que son 19, así que parece que lo tenemos.
Recapitulando, tenemos 3 primos:
1111111111111111111
524287
19
También sabemos que les gusta ir juntos, pero no sabemos en qué orden. Podemos ir problando, aunque, por ser ordenados, podría tener sentido que fueran de menor a mayor, tal que así:
195242871111111111111111111
Ahí está la respuesta que buscábamos; los tres primos, juntos, en familia.