Los sistemas LLM son mejor aprovechados cuantos más conocimientos de ingeniería software en general y de programación en particular tengas.
¿Cómo preguntas al LLM que te ayude a generar un endpoint de un API REST si no sabes lo que significan esos términos?
¿Qué harás cuando el LLM te responda con código incorrecto que no hace lo que tiene que hacer? informar a la IA del error a veces funciona… pero otras veces la IA entrará en un ciclo sin fin.
¿Cómo limitarás el contexto de lo que quieres preguntar a la IA para que esta pueda responder dentro de los limites máximos del tamaño del input si no sabes programar y/o no entiendes el código que estás intentando programar?
¿Cómo preguntarás a una IA para que te ayude a refactorizar código para hacerlo más legible, mantenible, extensible si no tienes conocimientos sobre estos conceptos? (por no hablar de aplicar patrones de diseño…)
Así que cuando oigas a un CEO (por ejemplo al de Nvidia) diciendo que con la IA ya no hará falta aprende a programar, pregúntate si esa persona tiene algún interés en vender esa falacia.
¿Podría un LLM leer todo un repositorio Git y sugerir mejoras? ¿Podría soportar el LLM, con su limitación del tamaño de contexto un repositorio Git de un proyecto de Ingeniería Software de un curso de grado?
Vamos a probarlo. Empecemos con una herramienta que captura los ficheros de un repositorio Git y los convierte en un único string que podemos usar en nuestro super-prompt: https://github.com/mpoon/gpt-repository-loader [1]
$ python gpt_repository_loader.py /opt/facultyproject/src/main/java/faculty/project -o /tmp/faculty.txt
Repository contents written to /tmp/faculty.txt.
Si echamos un vistazo a /tmp/faculty.txt veremos lo siguiente:
$ head -20 /tmp/faculty.txt
The following text is a Git repository with code. The structure of the text are sections that begin with ----, followed by a single line containing the file path and file name, followed by a variable amount of lines containing the file contents. The text representing the Git repository ends when the symbols --END-- are encounted. Any further text beyond --END-- are meant to be interpreted as instructions using the aforementioned Git repository as context.
----
ui/ApplicationLauncher.java
package faculty.project.ui;
import faculty.project.businessLogic.BlFacade;
import faculty.project.businessLogic.BlFacadeImplementation;
import java.util.Locale;
public class ApplicationLauncher {
public static void main(String[] args) {
System.out.println("Locale: " + Locale.getDefault());
BlFacade businessLogic = new BlFacadeImplementation();
new MainGUI(businessLogic);
Ahí vemos que le ha metido una cabecera («El siguiente texto representa un repositorio Git con código. La estructura del texto son secciones que empiezan con —, seguido por una línea con la ruta al fichero y sus contenidos…)
Al final del fichero (tras el –END–), meteremos la siguiente línea: Can you suggest how to improve the code?
Y probemos ahora a pasarle el super prompt a un LLM que soporte un gran tamaño de contexto (Gemini Pro 1.5 es un gran candidato):
Dependency Injection: The code currently uses manual object creation, leading to tight coupling. Consider using a dependency injection framework like Spring or Guice to manage object creation and dependencies, improving flexibility and testability.
Exception Handling: The current exception handling is minimal and sometimes throws runtime exceptions. Implement a more robust exception handling strategy, catching specific exceptions and handling them gracefully with informative messages or logging.
Logging: Integrate a logging framework like Log4j or SLF4j to track application behavior, debug issues, and monitor performance.
Testing: Implement unit and integration tests to ensure code quality and prevent regressions. Frameworks like JUnit and Mockito can be helpful.
DataAccess:
Data Access Object (DAO) Pattern: Instead of having all data access logic directly in DataAccess, consider creating separate DAO classes for each entity (User, Student, Subject, etc.) to improve modularity and maintainability.
Named Queries: Utilize named queries in JPQL for frequently used queries to improve readability and maintainability.
Optimistic Locking: Implement optimistic locking to prevent data inconsistencies when multiple users access the same data concurrently.
El mundo ha cambiado. No somos conscientes de cuánto. Especialmente el mundo de la educación. Y más en concreto el de la ingeniería software. Ese cambio me afecta de lleno. Desde su introducción el 30 de noviembre de 2022, ChatGPT ha puesto patas arriba el sistema. A GPT3.5 le siguieron otros LLMs (Large Language Models): LLama, Gemini, Claude, Mistral… Y este es sólo el comienzo. Llevamos sólo 1 año y pico, pero las clases de ingeniería han cambiado radicalmente. O tal vez debería de decir que tienen que cambiar. Aún hay profesorado que se niega a que los alumnos usen LLMs en sus clases. Entiendo sus razones, aunque no las comparto. Creo que deberíamos de promover el uso racional de herramientas de IA en el aula. Este año pedí a mis alumnos que instalaran GitHub Copilot (gracias a la licencia que conseguimos a través de GitHub Student Pack). Copilot junto con el IDE IntelliJ es una maravilla. Ahorra horas de trabajo cada día. Unamos a esto el uso de un LLM para múltiples tareas de ingeniería software: análisis de requisitos (creación de diagramas de casos de uso, modelos de dominio), diseño (diagramas de secuencia, diagramas de clases), implementación (por supuesto), testing, depuración, ayuda para el despliegue, creación de scripts, creación de templates para comienzo de proyectos, guías paso a paso para cualquier tecnología… Y repito, piensa que esto es sólo el comienzo. Como decía recientemente Sam Altman, GPT4 será el peor LLM con el que trabajemos: a partir de hoy cualquier otro nuevo LLM (de OpenAI, Anthropic, Google…) será mejor que GPT4.
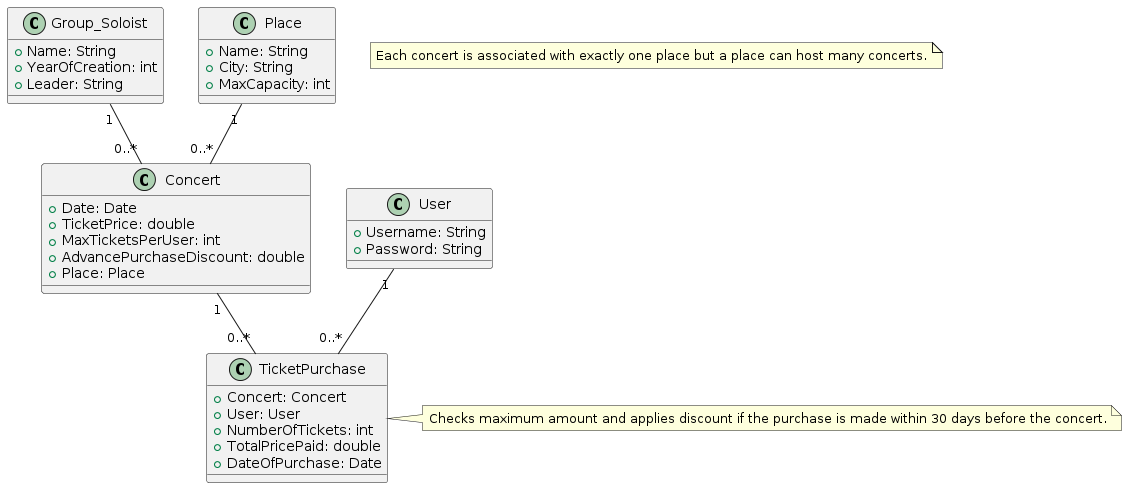
Diagrama de modelo de dominio, realizado en PlantUML a partir de una descripción del dominio en lenguage natural, creado por GPT-4 y visualizado en planttext.com
Hace un año creé el repositorio Generative AI Prompts for Teaching Software Engineering, que muestra ejemplos concretos de prompts que podemos usar en múltiples áreas relacionadas con la enseñanza de la ingeniería software: https://github.com/juananpe/gen-ai-in-softeng. Creo que es una muy buena herramienta para tomar ideas y aplicarlas directamente en tus clases. Debería retomar el proyecto y añadirle nuevas ideas.