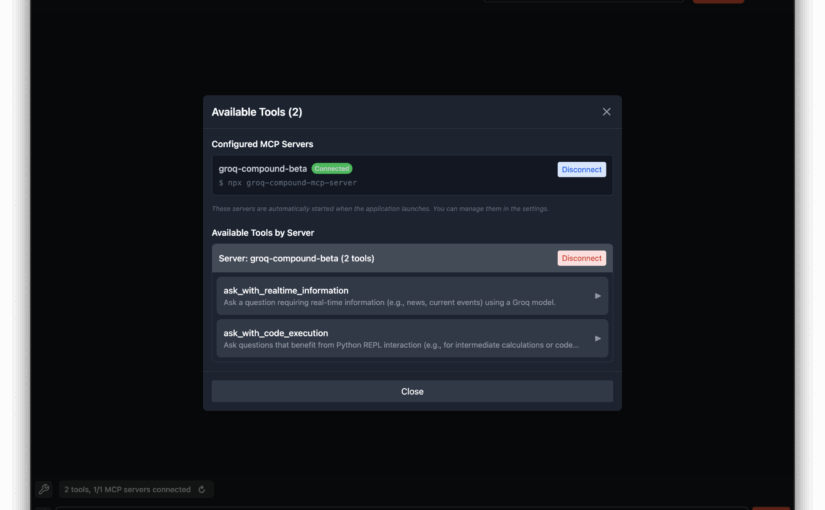
Groq has just released Groq Desktop in beta mode (https://github.com/groq/groq-desktop-beta), and I’ve had the chance to try it out. What caught my attention was its impressive MCP support, which seems to outshine Claude Desktop. Here are three reasons why:
1. YOLO Mode: Groq Desktop allows you to accept tool execution without asking questions, making the process smoother.
2. On-the-fly Server Reload: Unlike Claude, where you need to restart the app to reload MCP servers, Groq Desktop lets you do it seamlessly.
3. Hot Enable/Disable MCP Servers: You can enable or disable MCP servers on the fly, without needing to reload Groq Desktop.
These features make Groq Desktop a strong contender in the MCP support arena. Have you tried it out? What are your thoughts?
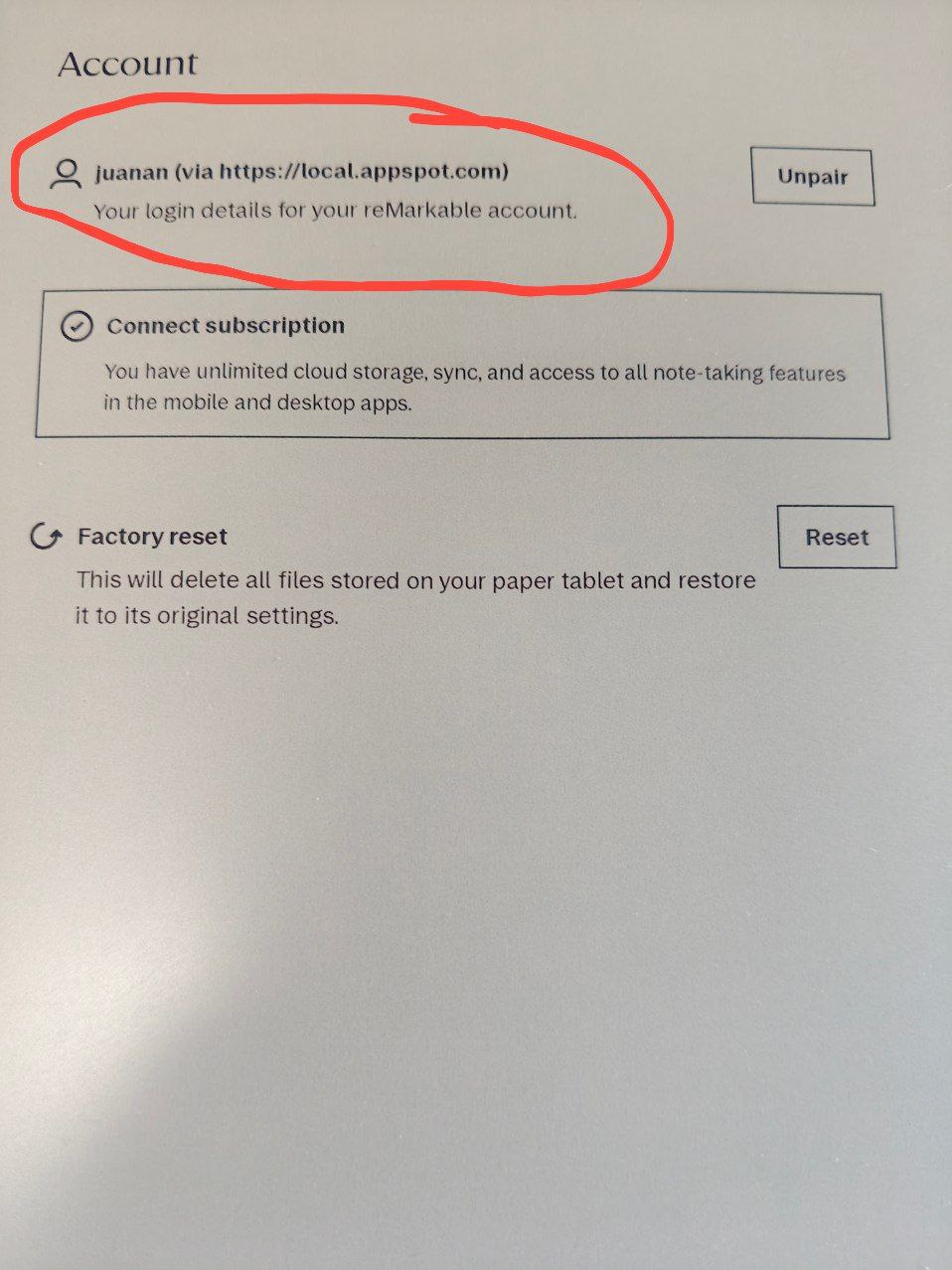
Tengo una remarkable pro. Quiero conseguir 3 cosas: 1) Poder acceder via ssh 2) Poder sincronizar mis archivos usando mi propio cloud. Solución: rmfakecloud (no el cloud privativo de pago de remarkable) 3) Poder usar el pen de la rM como el pen de una tablet. Solución: remarkable-mouse
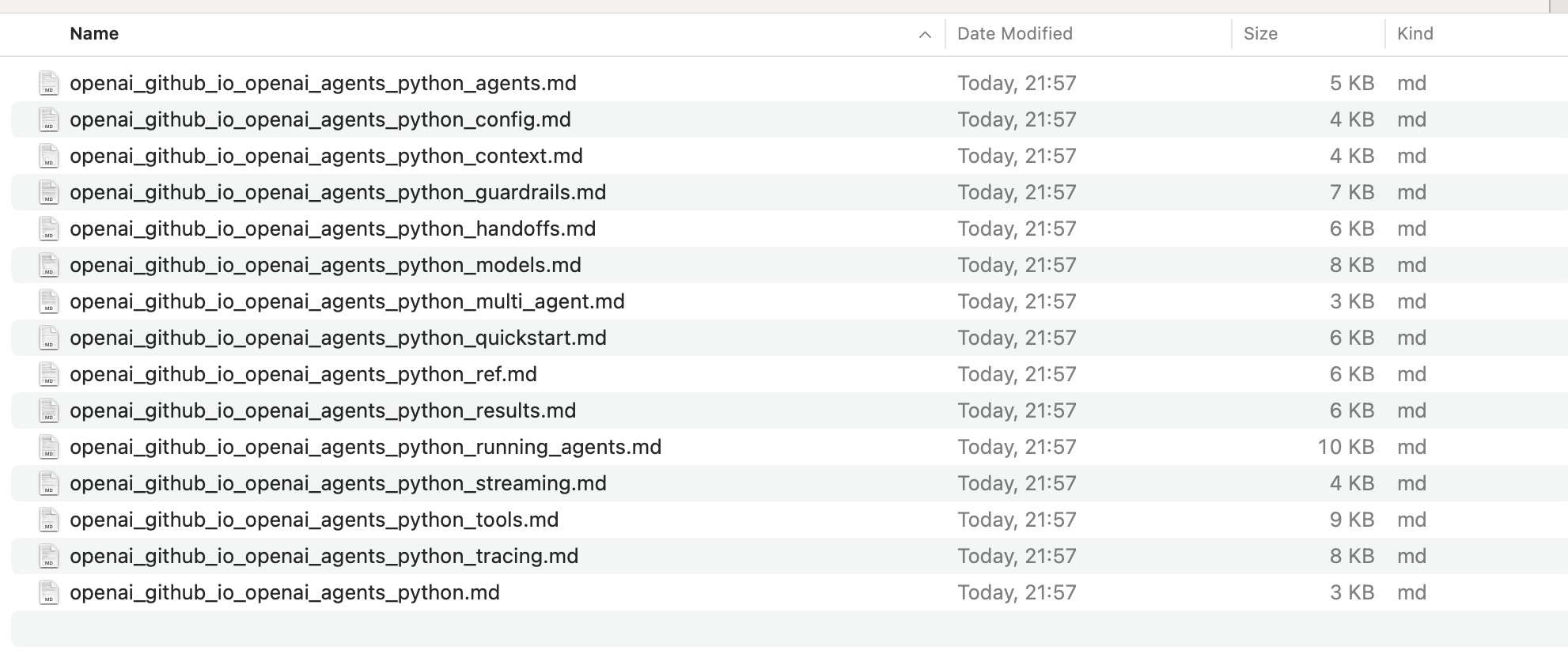
Recently, OpenAI published its framework https://openai.github.io/openai-agents-python (A lightweight, powerful framework for multi-agent workflows). I wanted to try it out, but I didn’t have much time… so I resorted to a new technique I’ve been using lately to do quick tests on new frameworks I want to explore.
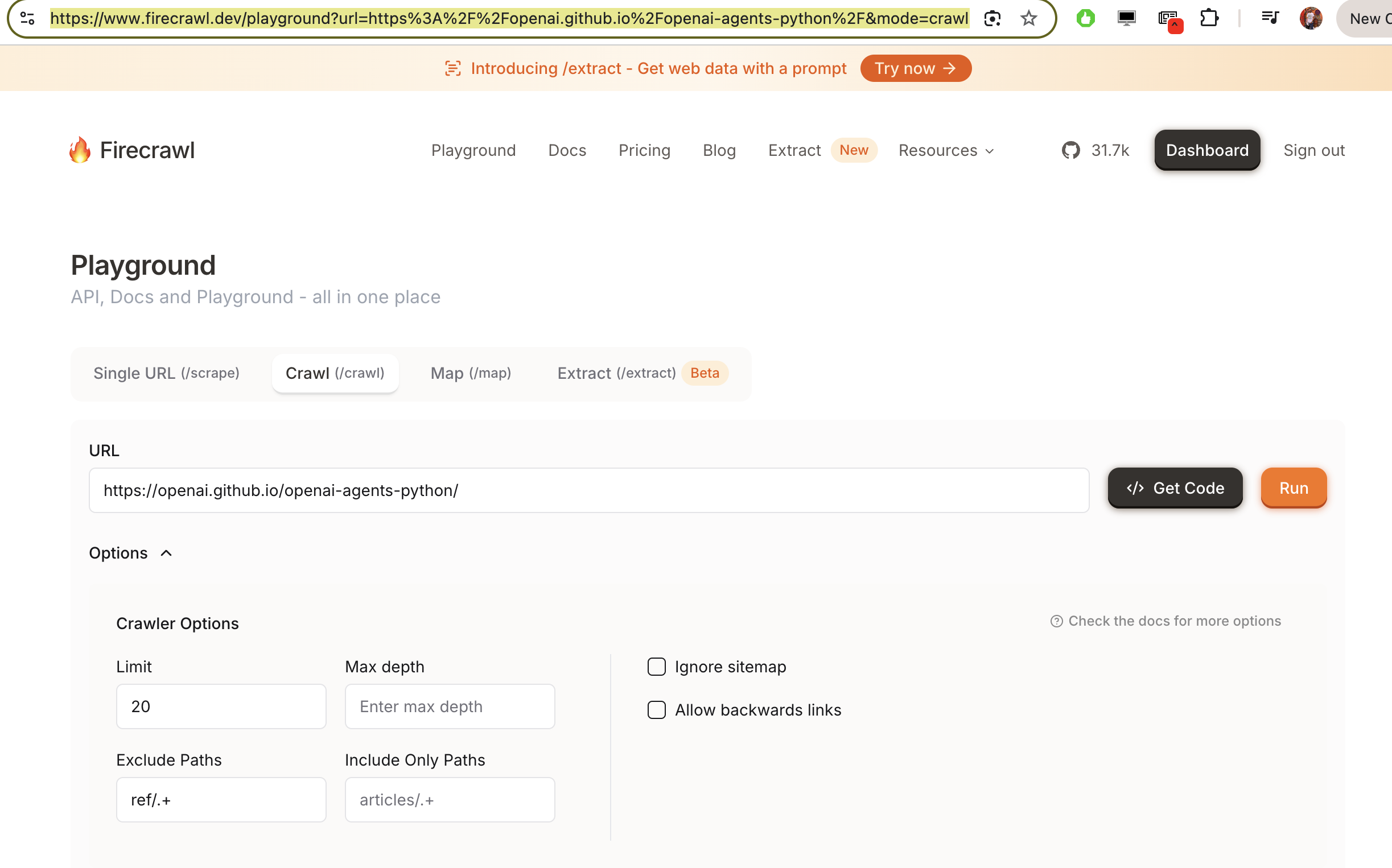
Access the online documentation: https://openai.github.io/openai-agents-python/
Open Firecrawl.dev. This application will allow us to crawl a website, extracting the main text into markdown or json format. The idea is to collect all the HTML documentation of the framework to be explored in plain text.
I have indicated that it should not include pages that contain the path ref/.+ to avoid overloading the LLM with extra context (I’ll explain this in a second)
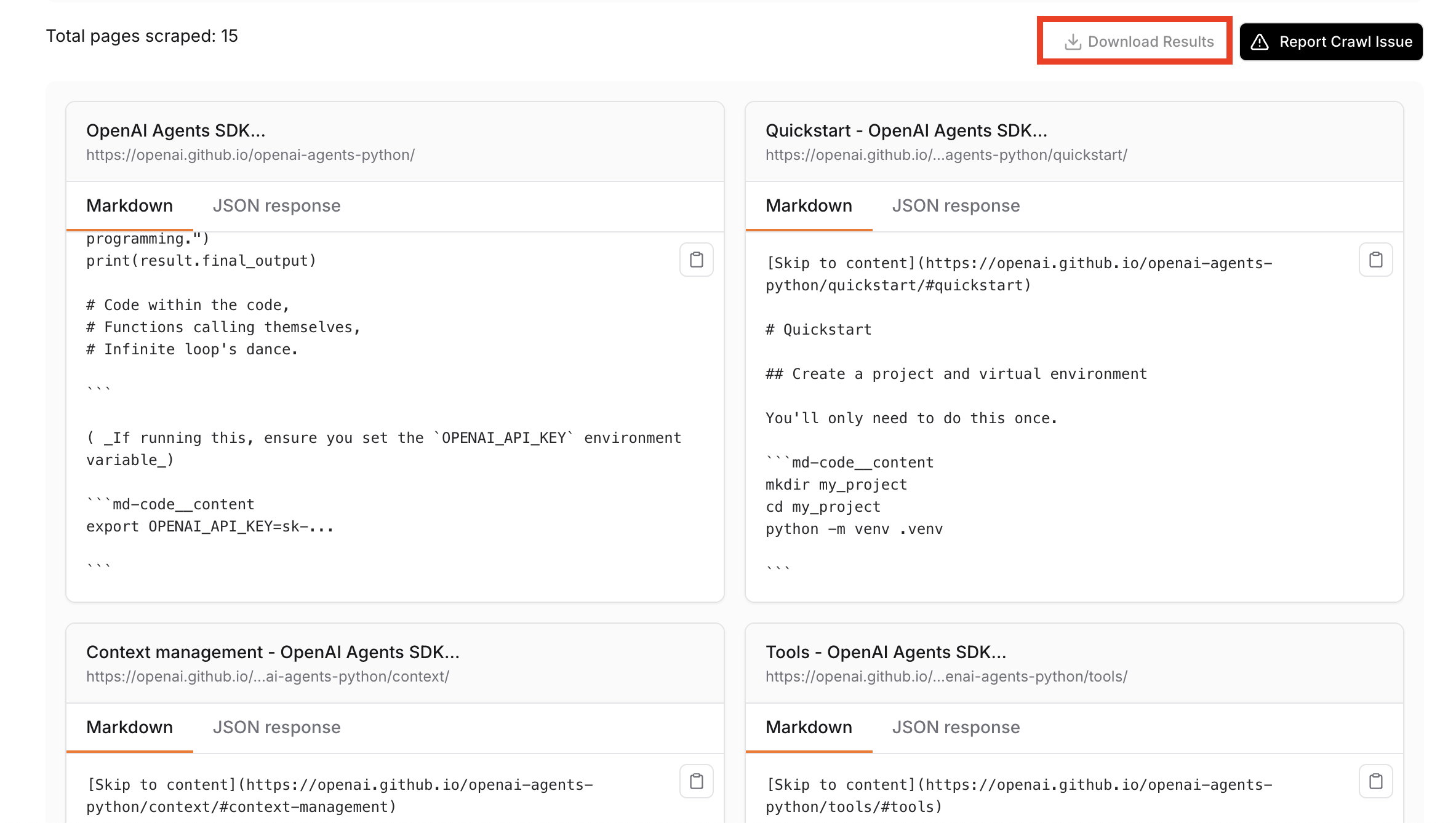
3. Download the results:
4. Unpack and check:
5. We attach the .md as context to Claude. We can do it by drag&drop or by concatenating all in a single file using cat *.md > documentation.md and uploading that single file.
6. The prompt: Read the following info about how to create an agent with OpenAI Agents SDK. I want to create an agent that knows how to fetch info from a webpage. We can use a python function that internally uses request
7. Claude got it right on the first try, and was able to generate an agent, using the new OpenAI Agents Framework, that we can use to ask questions about any website.
I had been thinking for a while that I would take advantage of Christmas to install Kodi on my LG TV (webOS). So yesterday I got to work on it.
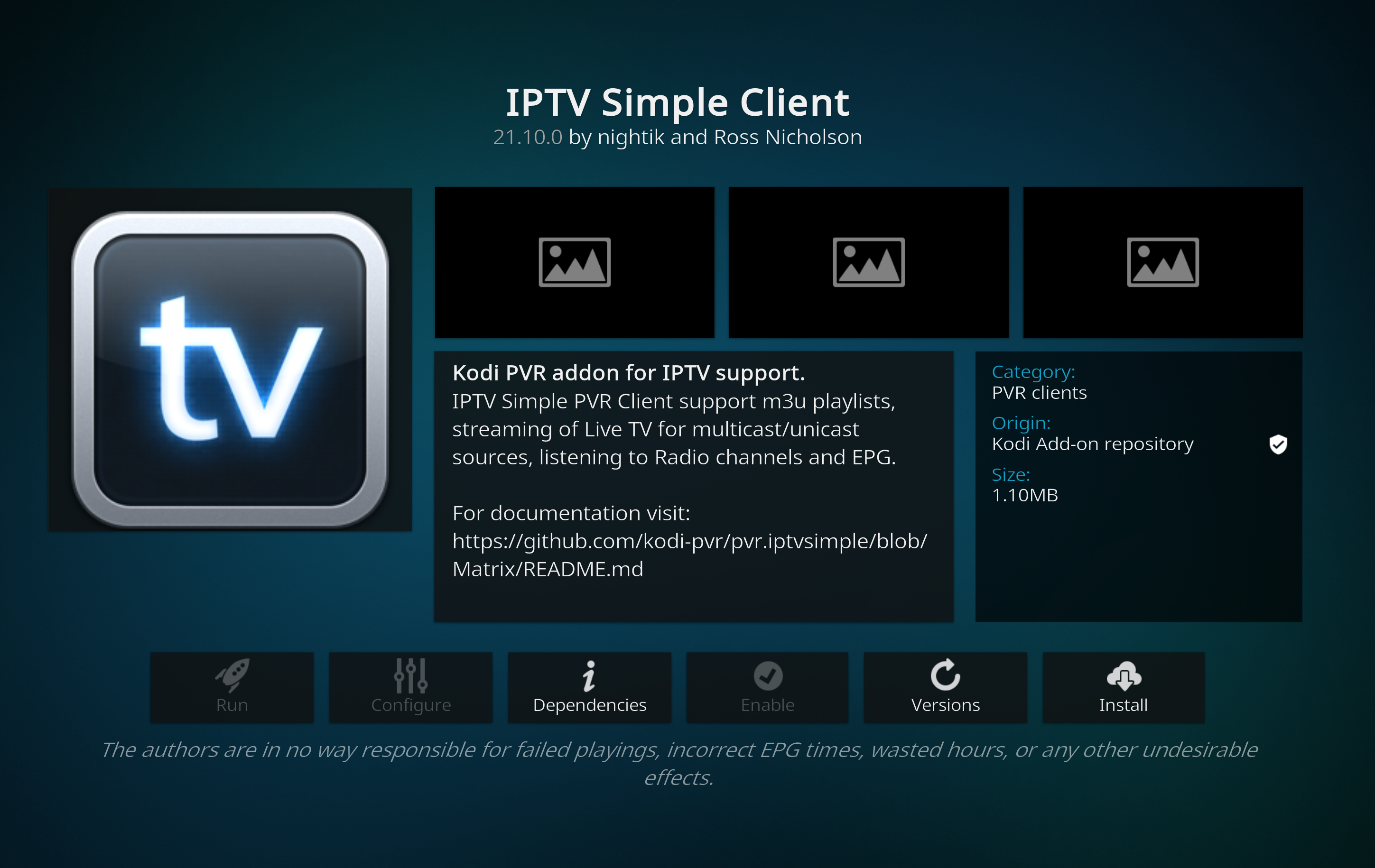
The installation is straightforward by following this mini-tutorial: https://kodi.wiki/view/HOW-TO:Install_Kodi_for_webOS. The problem arose when trying to install the IPTV Simple Client. This client has several dependencies, including inputstream.ffmpegdirect and inputstream.rtmp, which are not available in the Kodi repository for LG. It is necessary to download and install the pre-compiled binaries.
Reboot Kodi. Accept the messages that Kodi will display indicating that it has discovered two new add-ons. Open the settings of IPTV Simple Client.
When this add-on is enabled, it displays all channels it can make available from the M3U file you specified during the configuration step, under the menu option ‘PVR & Live TV’ (you can’t «run» the add-on like you do with the others). Since it starts automatically when Kodi starts, there is no ‘run’ option. When the add-on is configured with a working channel list (*.m3u), it will scan that list and display all available channels in the main window.
Bonus: TIL: you can use CanI.RootMy.TV to find an exploit for your TV.
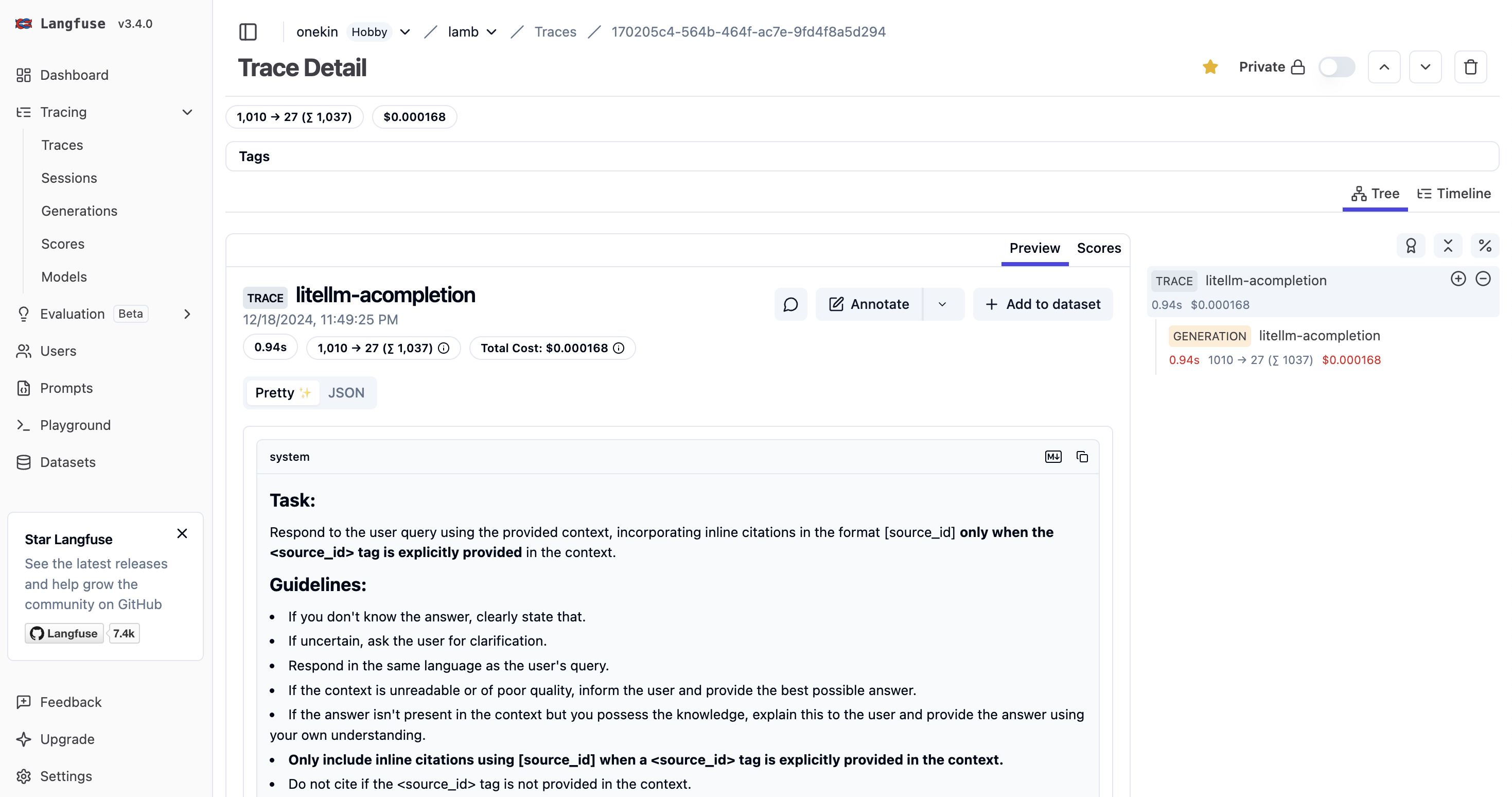
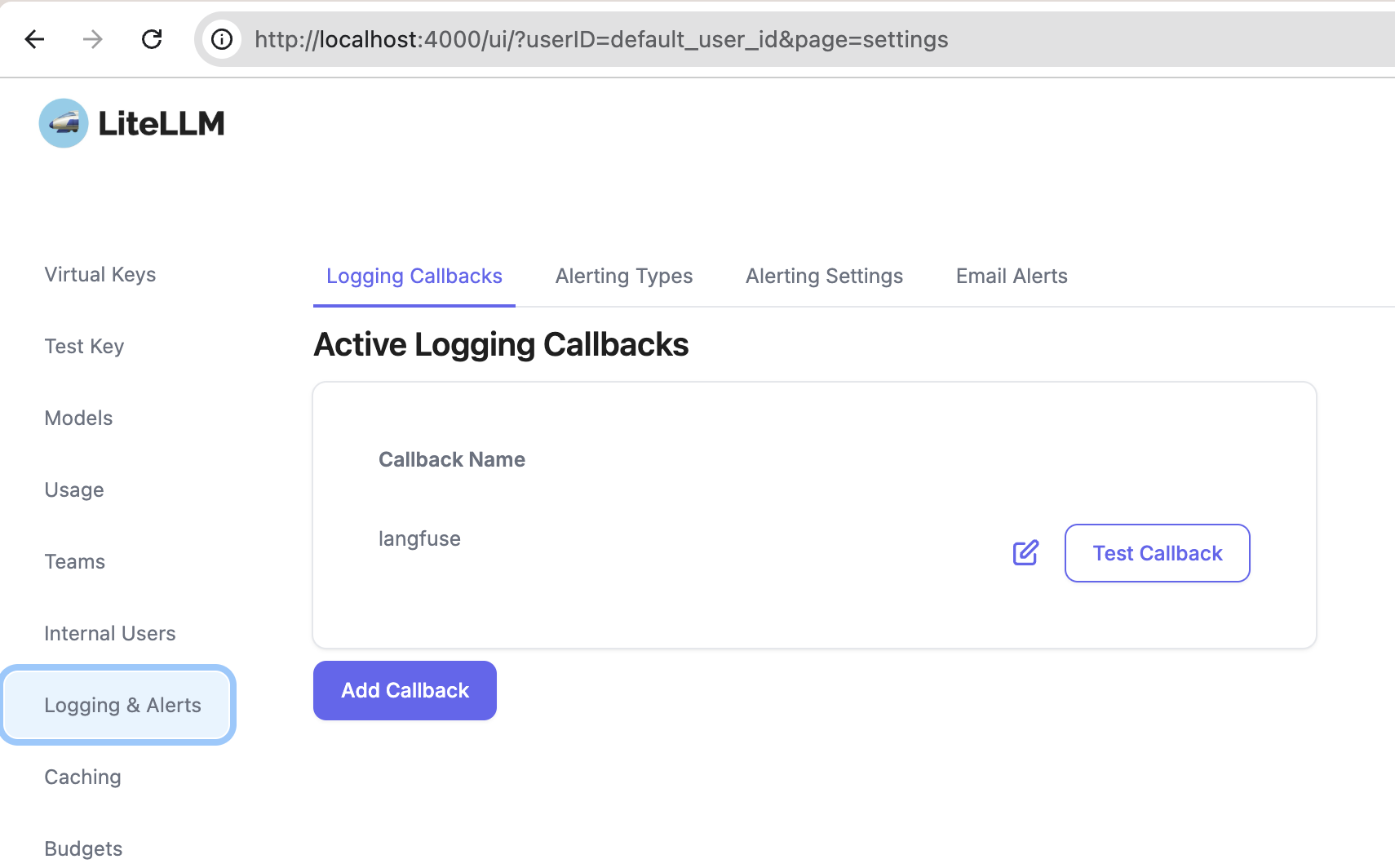
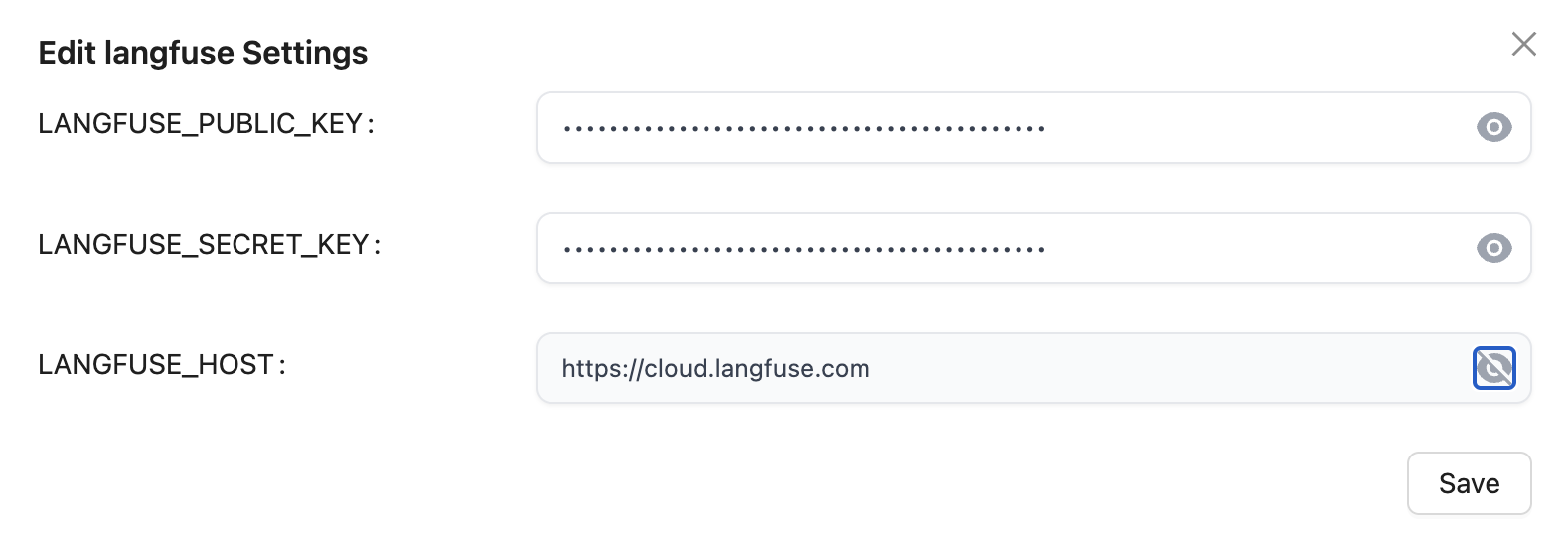
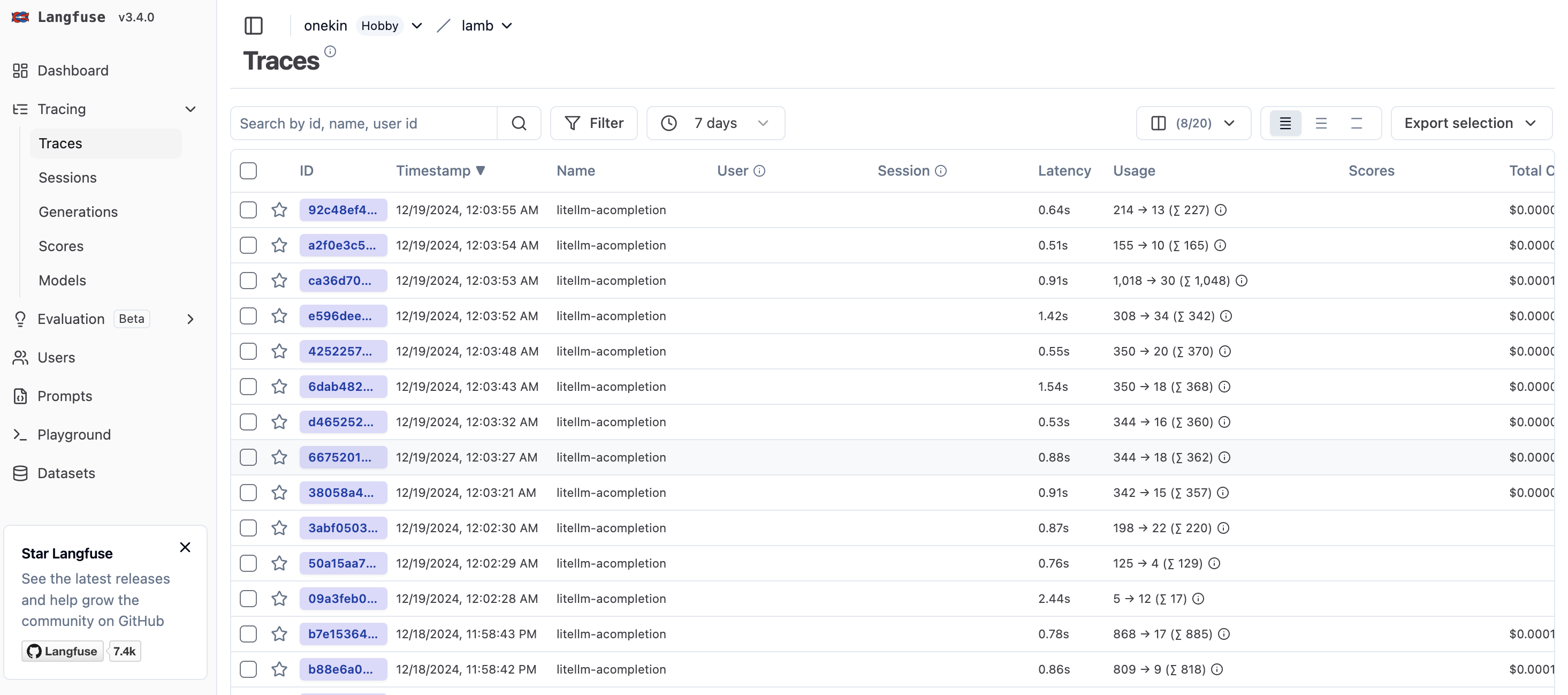
Contexto: has implementado o estás usando una aplicación web que internamente hace llamadas vía API a un LLM (GPT, Claude, LLama, whatever). Quieres analizar cuáles son los prompts que dicha aplicación está enviando. Necesitarás litellm (para que haga de proxy entre tu aplicación y el LLM) y langfuse, que recibirá un callback y te mostrará gráficamente todos los prompts. La idea es que litellm enviará automáticamente a langfuse una copia de cada lllamada al LLM (y de su respuesta) para que luego las puedas visualizar cómodamente.
(cambia el password dbpassword9090 como quieras). Postgresql es necesario para que litellm guarde información de los modelos. Necesitarás también crear un schema para postgresql a través de Prisma.
Copia el fichero schema.prisma del repositorio GitHub de litellm: