El Model Context Protocol (MCP) es un estándar abierto, ideado por Anthropic, que busca hacer más sencillo y práctico conectar tus aplicaciones con los LLM. Imagina que tienes un asistente inteligente y quieres que pueda hablar con todas las herramientas y bases de datos que usas sin volverte loco configurando cada cosa; eso es lo que MCP hace por ti.
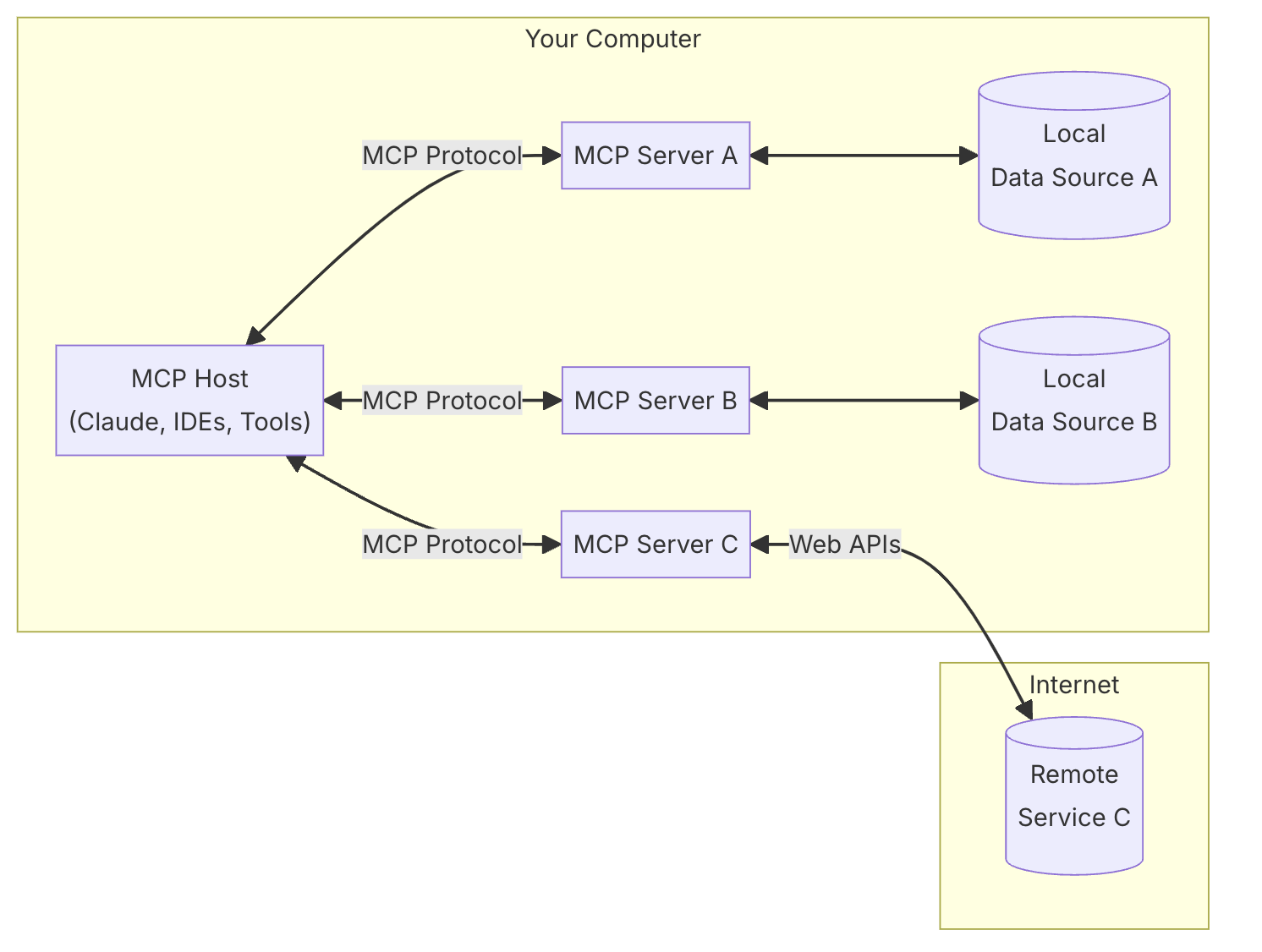
En la siguiente figura vemos que podemos tener distintos servicios MCP (ofreciendo por ejemplo conexión con una base de datos sqlite, con el sistema de archivos, con GitHub, etc.) y un cliente (host) que hace uso de dichos servicios (por ejemplo, Claude, a través de Claude Desktop, por ahora uno de los pocos clientes compatibles). Durante la preview, los servicios MCP deben estar ejecutándose en local, aunque Anthropic está trabajando para que en breve podamos usar servicios MCP remotos.
Veamos cómo configurar Claude Desktop (un cliente MCP) para que sepa hablar con una base de datos Sqlite.
Lo primero, desde Claude / Settings / Developer, pulsa en «Edit Config»
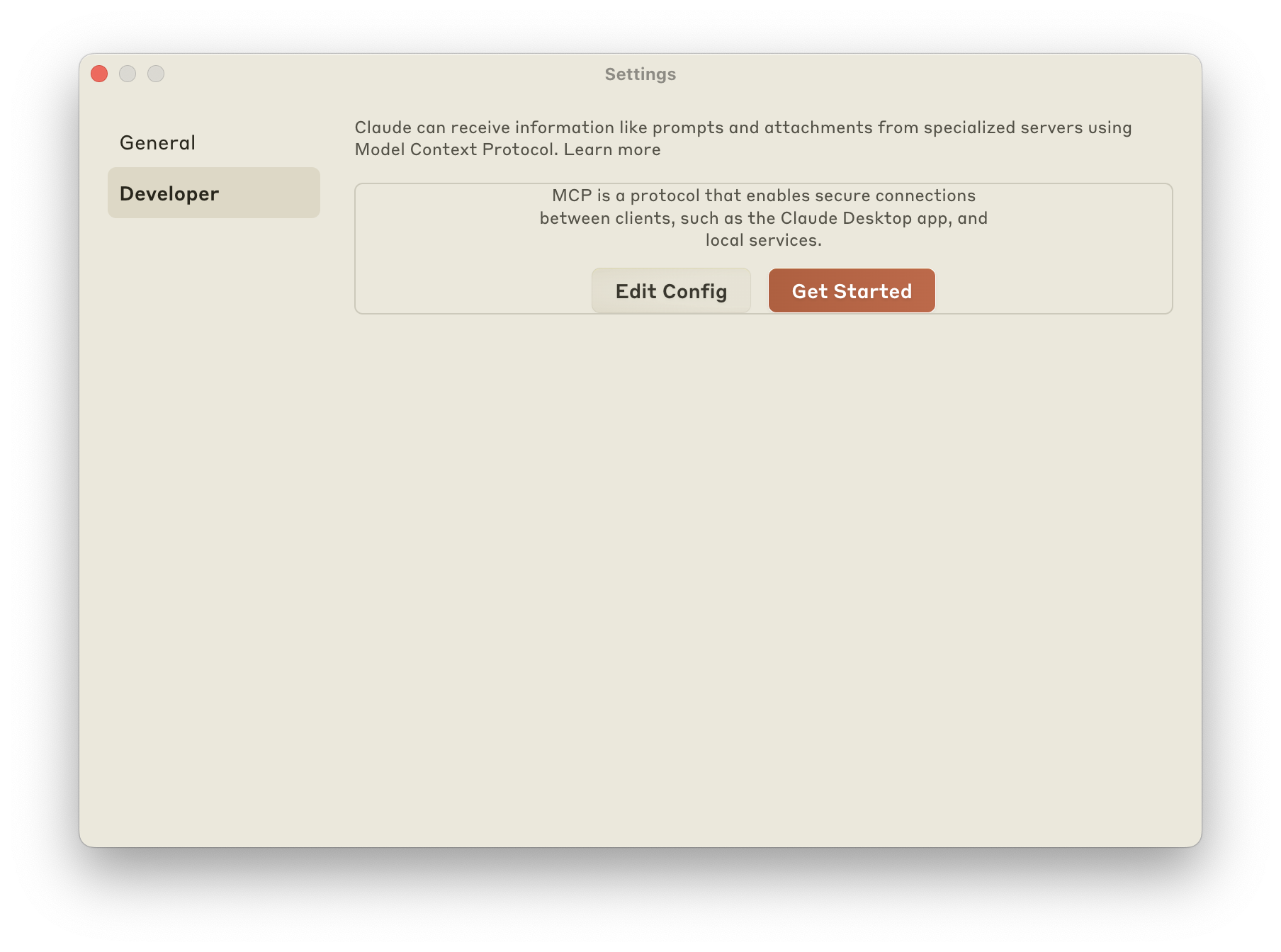
Edita el fichero claude_desktop_config.json:
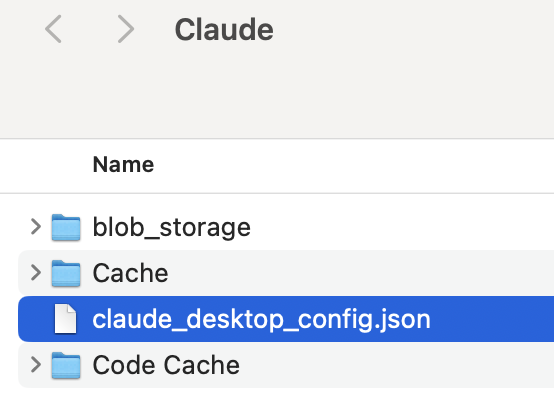
Para que quede así:
{
"mcpServers": {
"sqlite": {
"command": "uvx",
"args": ["mcp-server-sqlite", "--db-path", "/ruta/a/tu/basededatos.db"]
}
}
}
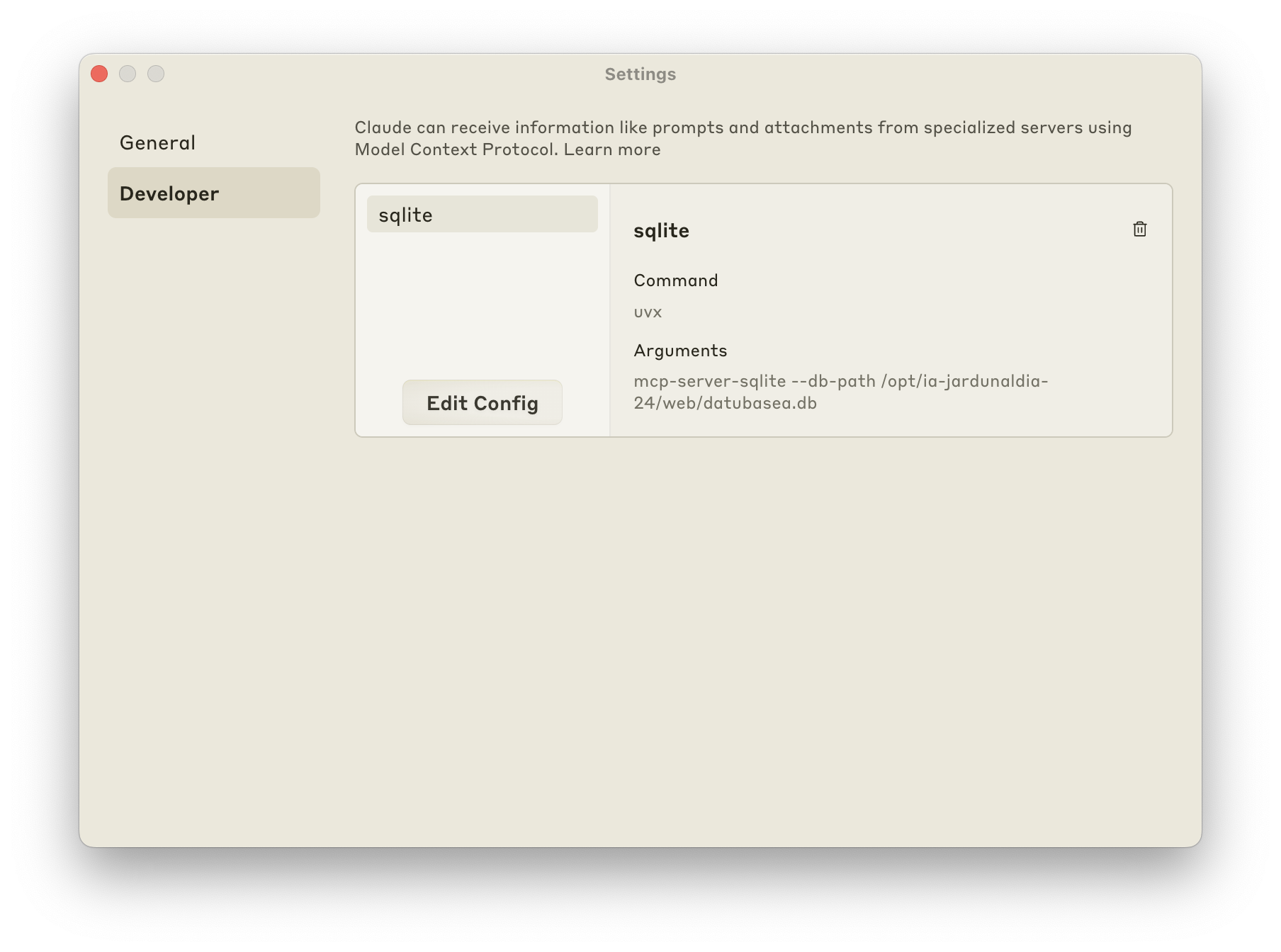
Cierra Claude Desktop y vuélvelo a abrir. Entra de nuevo en Settings / Developer. Deberías ver lo siguiente:
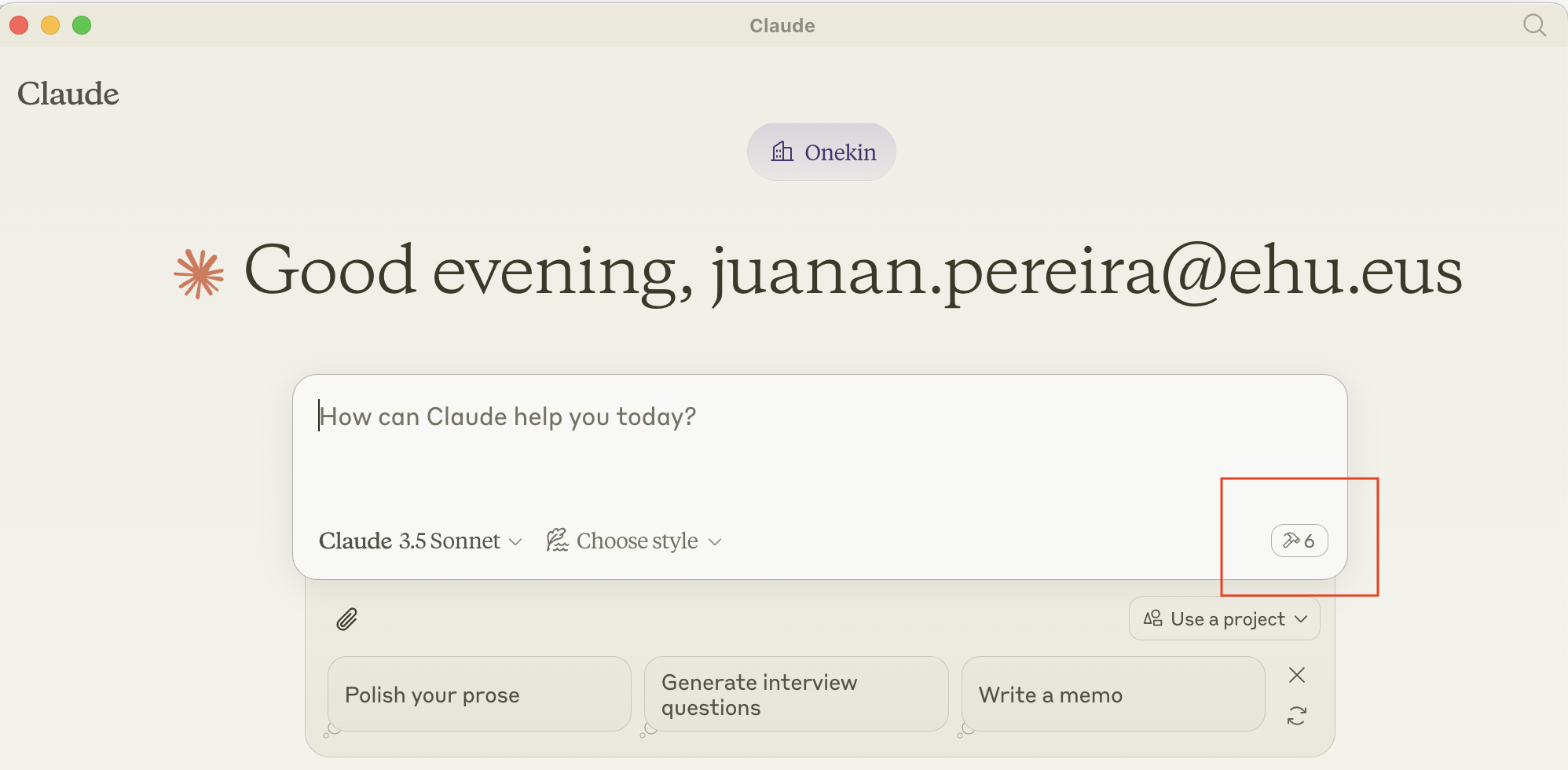
Y si abres un nuevo chat, tendrías que ver 6 tools disponibles:
Ahora podemos hacerle preguntas a Claude al respecto de la BBDD sqlite, por ejemplo:
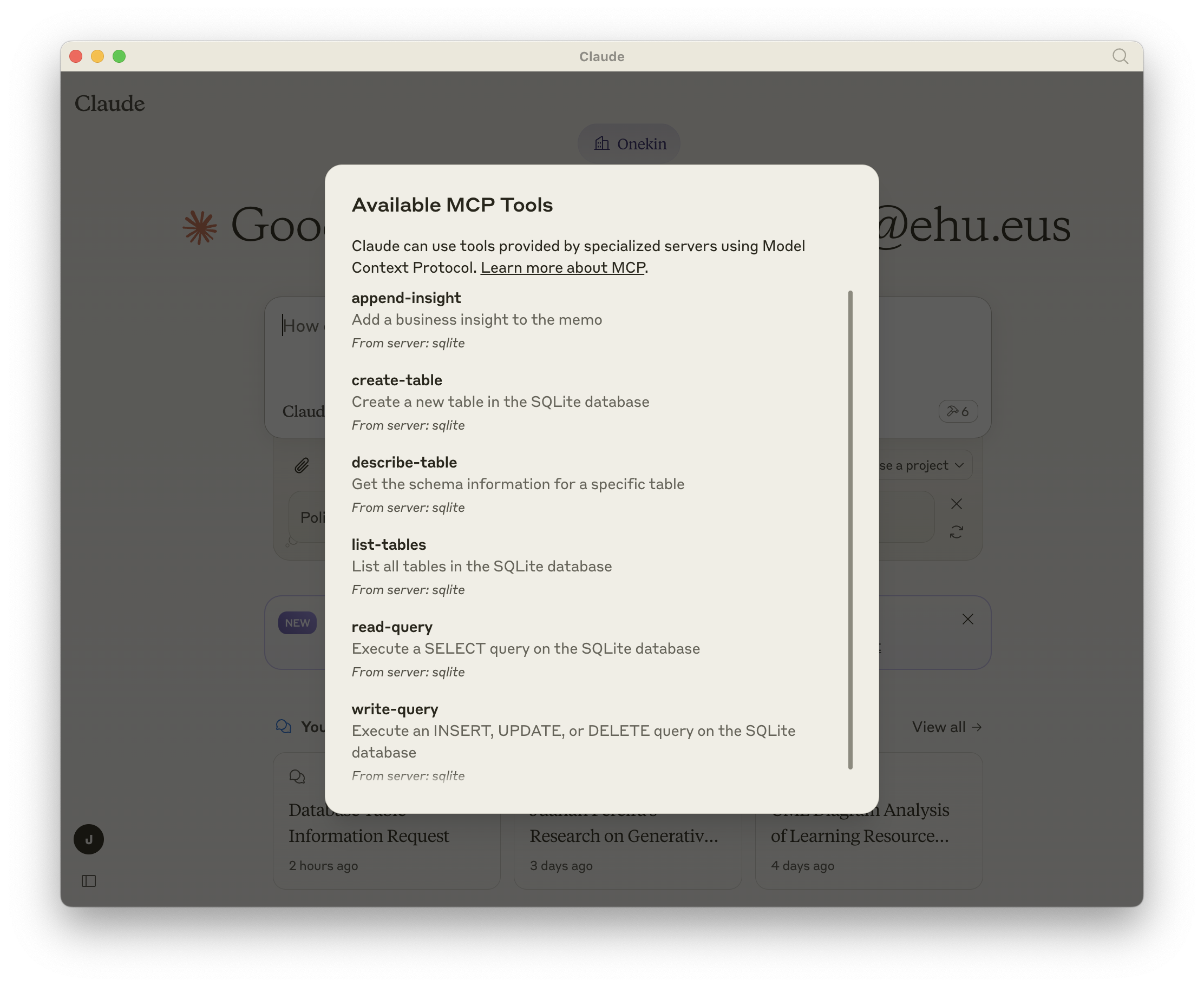
¿Cuántas tablas hay en la base de datos? ¿Puedes listarlas?
La primera vez Claude te pedirá permiso de ejecución:
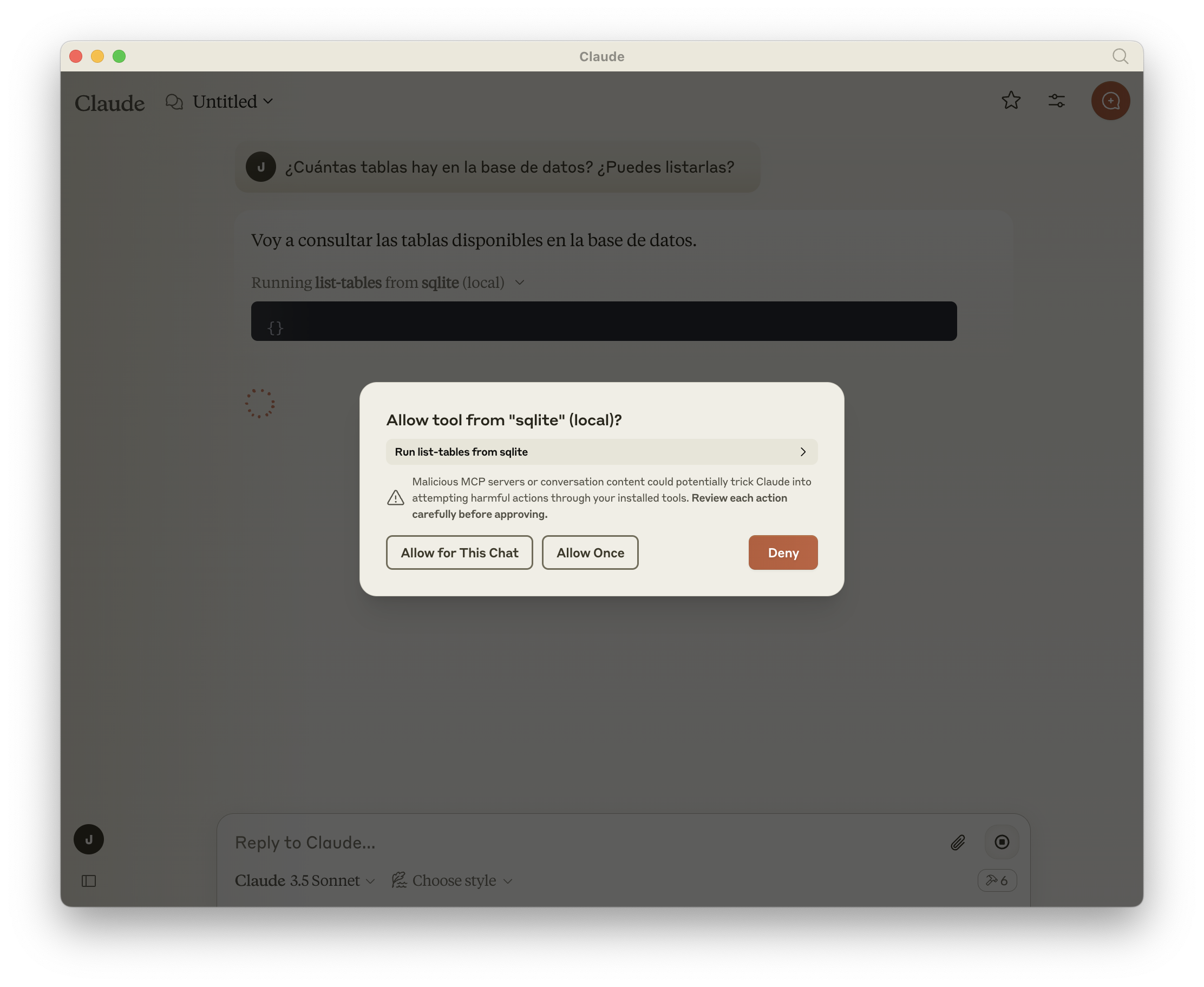
Y a continuación ejecutará el comando list-tables disponible a través de MCP: (y efectivamente, las tablas que le he pasado están en un sqlite de un proyecto en Euskera 🙂
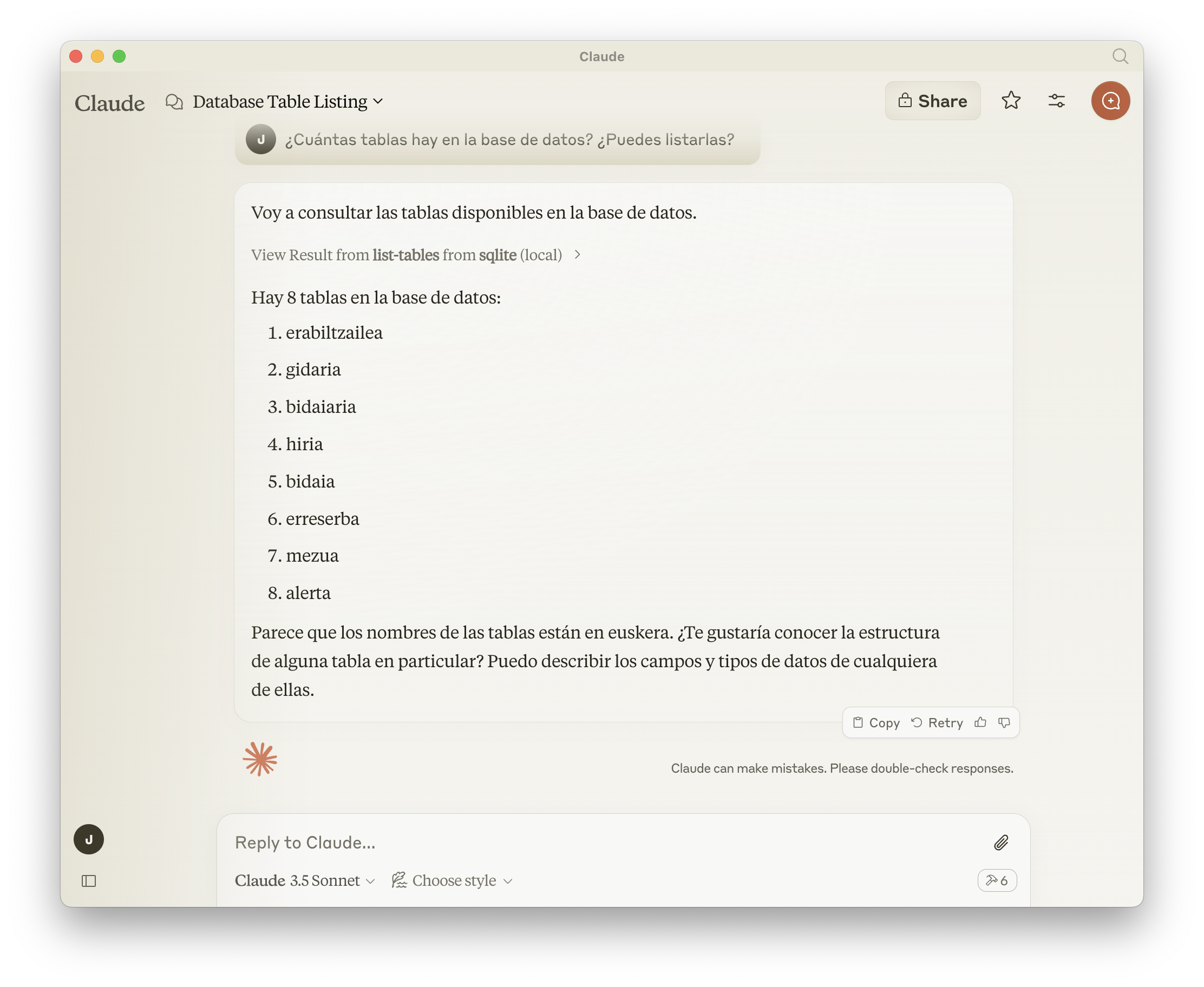
Podemos pedir que nos liste los usuarios (tabla erabiltzailea):
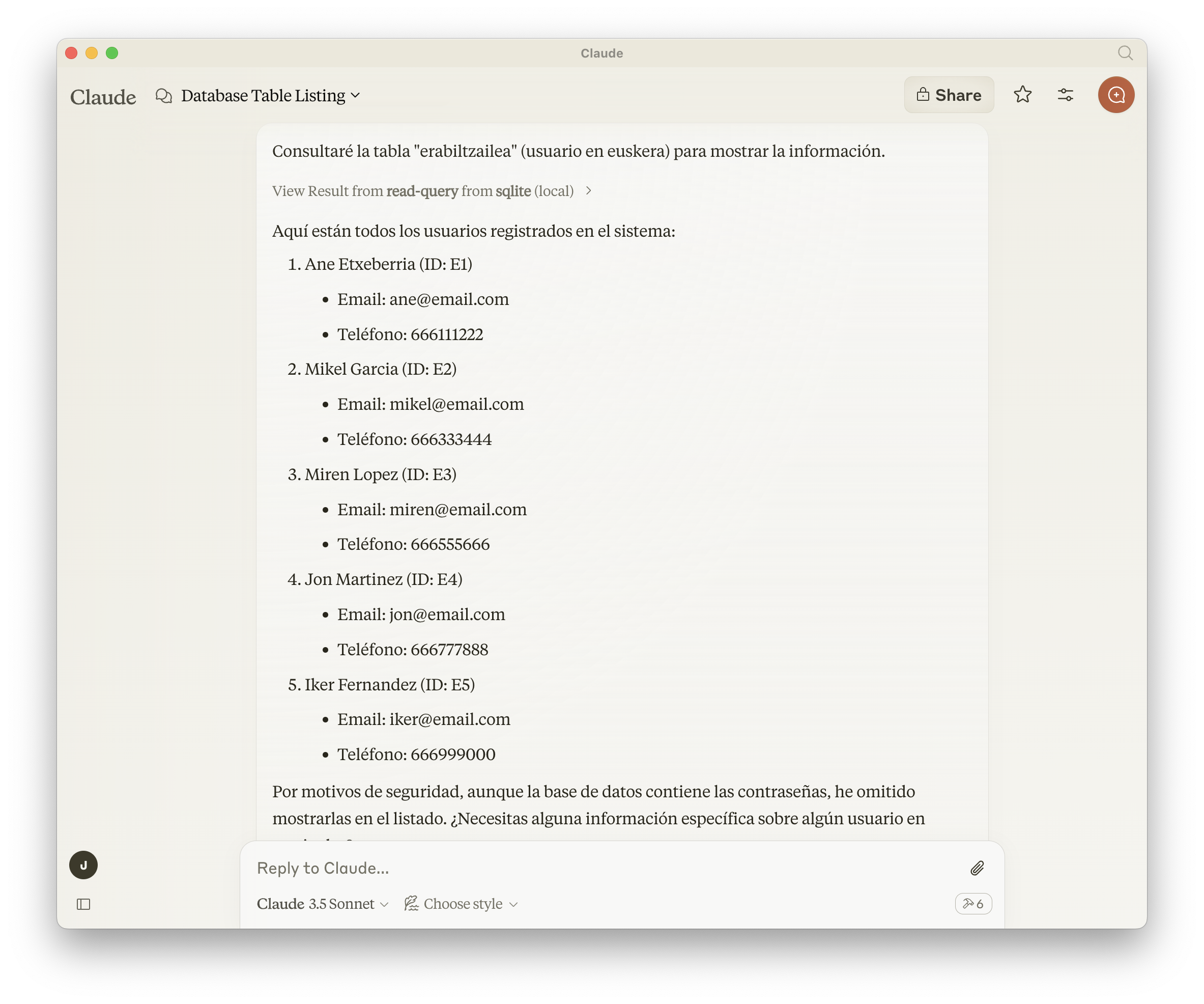
Es curioso el último párrafo, donde se niega a mostrar el contenido de la columna de passwords por motivos de seguridad.
Debugging
MCP ofrece una herramienta web llamada mcp-inspector que nos permite depurar un servicio MCP desde el navegador. Por ejemplo, si quisiéramos ver qué ofrece el servidor mcp-server-sqlite, podríamos lanzar el siguiente comando:
$ npx @modelcontextprotocol/inspector uvx mcp-server-sqlite --db-path /ruta/a/tu/basededatos.db
Desde donde podríamos ver los recursos ofrecidor por ese servidor:
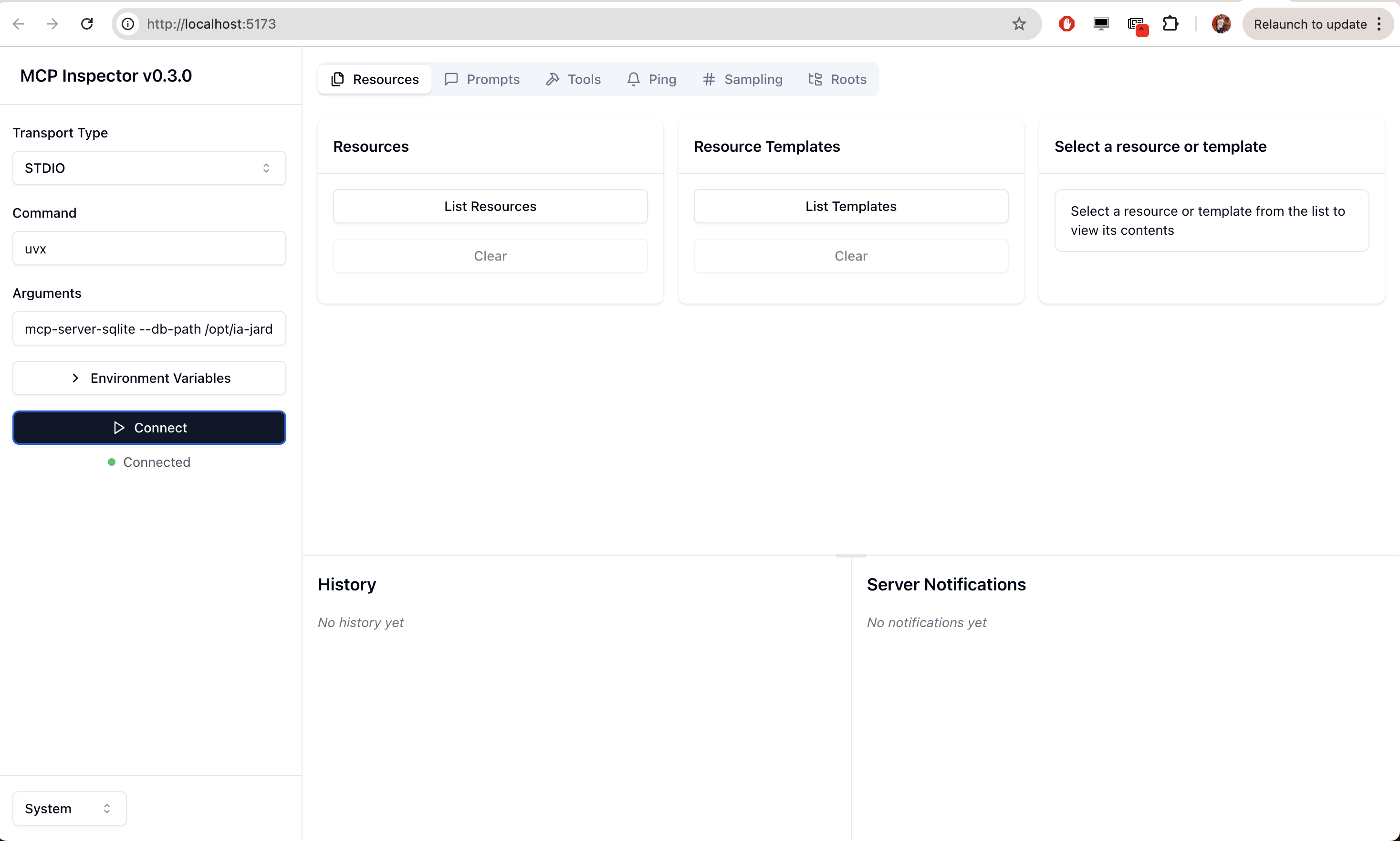
Por ejemplo, probar las herramientas desde el navegador, así:
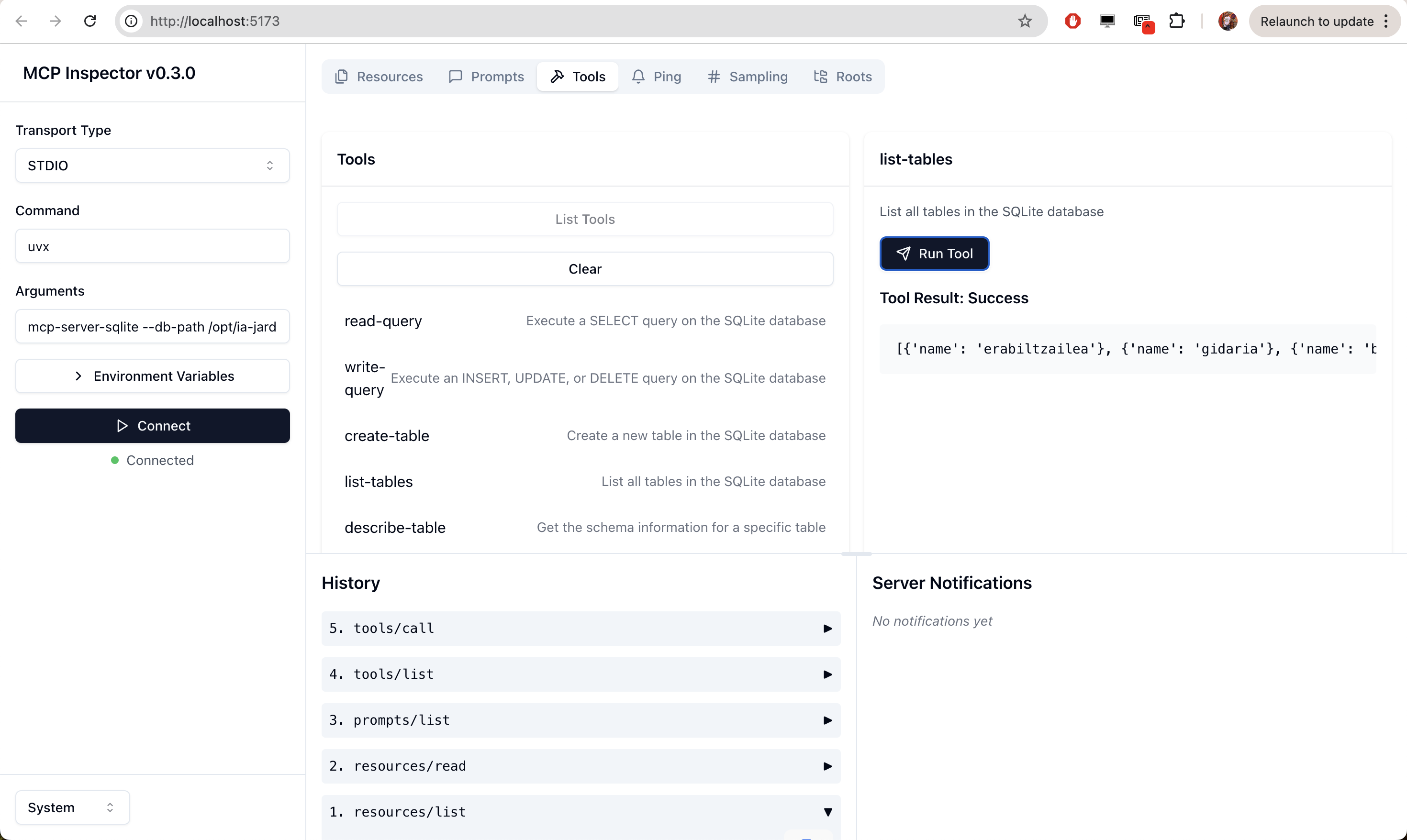
Troubleshooting
Si no te sale el icono de MCP en el chat, prueba lo siguiente.
Activa el Developer Mode para ver los logs de MCP:

Te mostrará por defecto el mcp.log. Pero si pulsas sobre el nombre con Cmd+Click izq. verás la ruta a ese log:
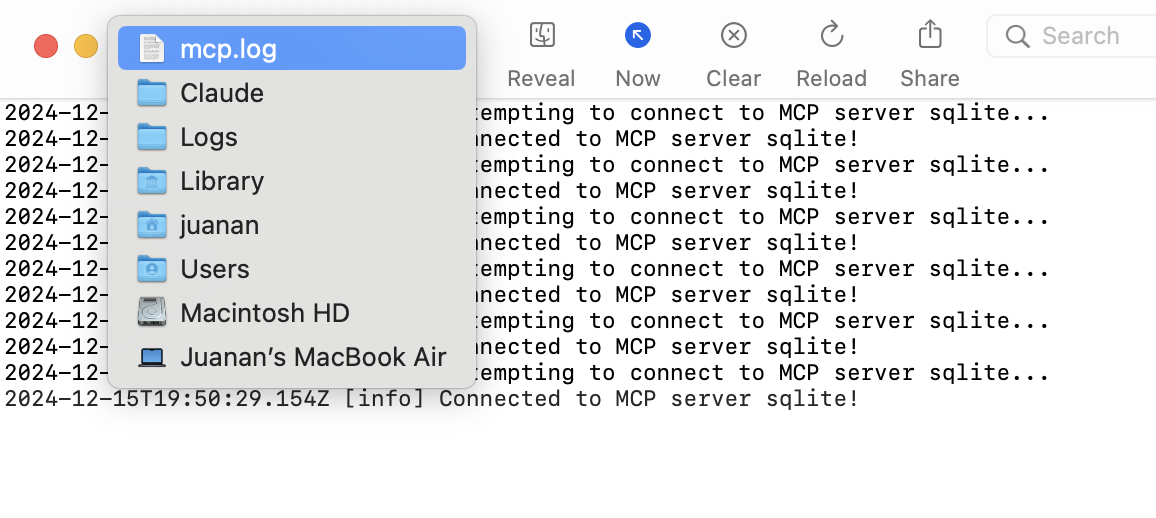
Y en ~/Library/Logs/Claude, verás también el fichero mcp-server-sqlite.log
En mi caso, tuve el siguiente problema:

Dado que mcp-server-sqlite requiere una versión de Python superior a la 3.9.13 (la que tengo por defecto en un equipo) es necesario especificar la ruta a un Python más moderno (3.12.14 en mi caso) en el JSON de configuración, así:
{
"mcpServers": {
"sqlite": {
"command": "uvx",
"args": ["--python", "/opt/homebrew/anaconda3/bin/python", "mcp-server-sqlite", "--db-path", "/ruta/a/tu/basededatos.db"]
}
}
}
Y ahora sí, veremos que tenemos tools disponibles en Claude: