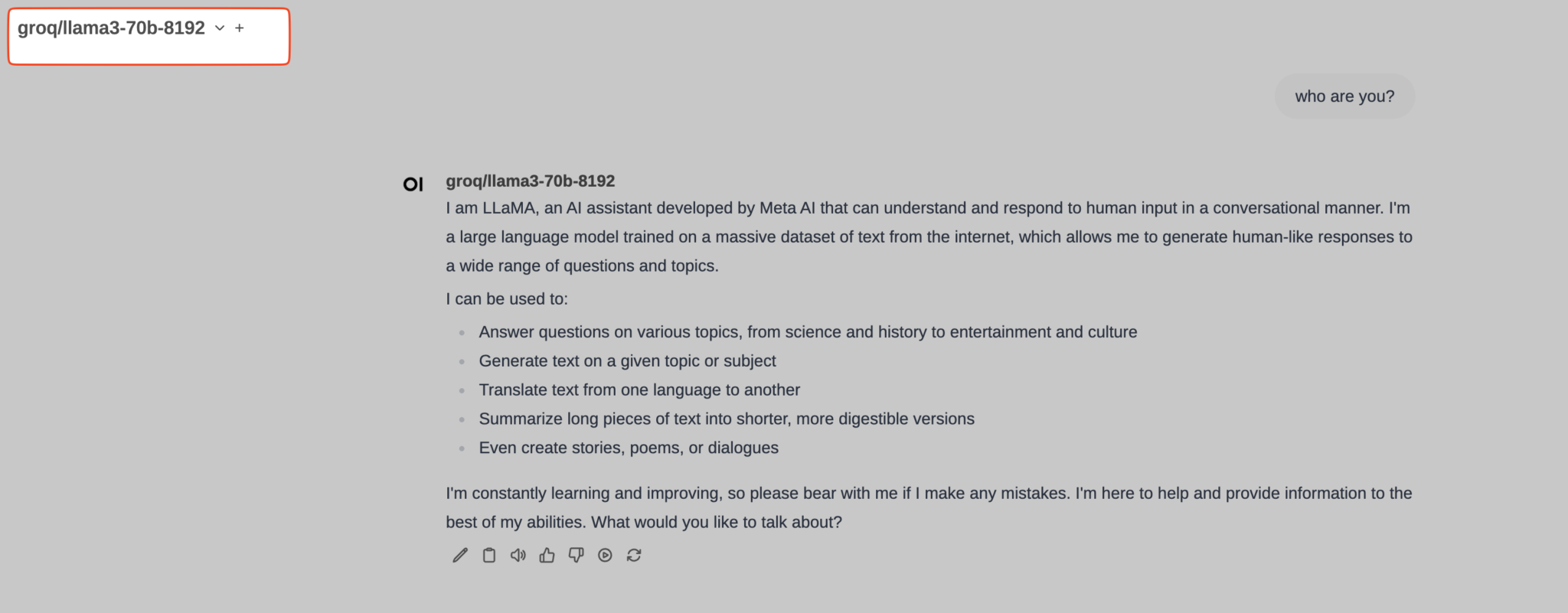
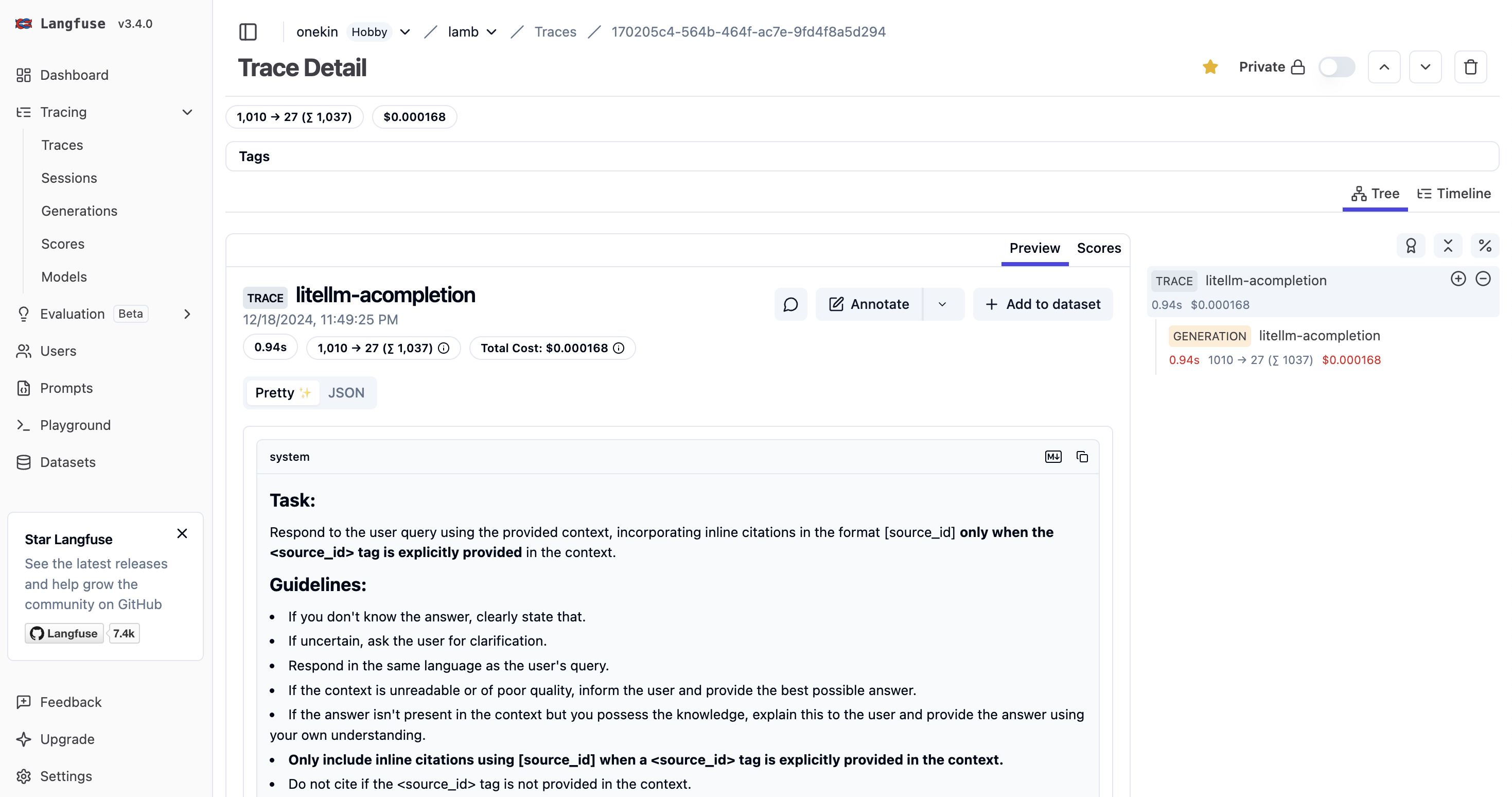
Contexto: has implementado o estás usando una aplicación web que internamente hace llamadas vía API a un LLM (GPT, Claude, LLama, whatever). Quieres analizar cuáles son los prompts que dicha aplicación está enviando. Necesitarás litellm (para que haga de proxy entre tu aplicación y el LLM) y langfuse, que recibirá un callback y te mostrará gráficamente todos los prompts. La idea es que litellm enviará automáticamente a langfuse una copia de cada lllamada al LLM (y de su respuesta) para que luego las puedas visualizar cómodamente.
Receta rápida:
Instala las dependencias necesarias
$ pip install litellm 'litellm[proxy]' prisma langfuse
Usa el fichero de configuración de litellm del que ya hablamos en su día en ikasten.io.
Instala Postgresql, por ejemplo, a través de docker. Para ello, usa el siguiente docker-compose.yaml:
version: '3'
services:
db:
image: postgres
restart: always
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
ports:
- "5432:5432"
(cambia el password dbpassword9090 como quieras). Postgresql es necesario para que litellm guarde información de los modelos. Necesitarás también crear un schema para postgresql a través de Prisma.
Copia el fichero schema.prisma del repositorio GitHub de litellm:
https://github.com/BerriAI/litellm/blob/main/schema.prisma
$ prisma generate
Lanza litellm :
$ DATABASE_URL="postgresql://llmproxy:dbpassword9090@localhost:5432/litellm" STORE_MODEL_IN_DB="True" LITELLM_MASTER_KEY=sk-12345 LITELLM_SALT_KEY="saltkey1234" litellm --config ./config.yaml
Abre el panel de administración gráfica de litellm en localhost:4000/ui
Por defecto, login: admin, pass: el master_key que hayas definido. En el ejemplo: sk-12345.
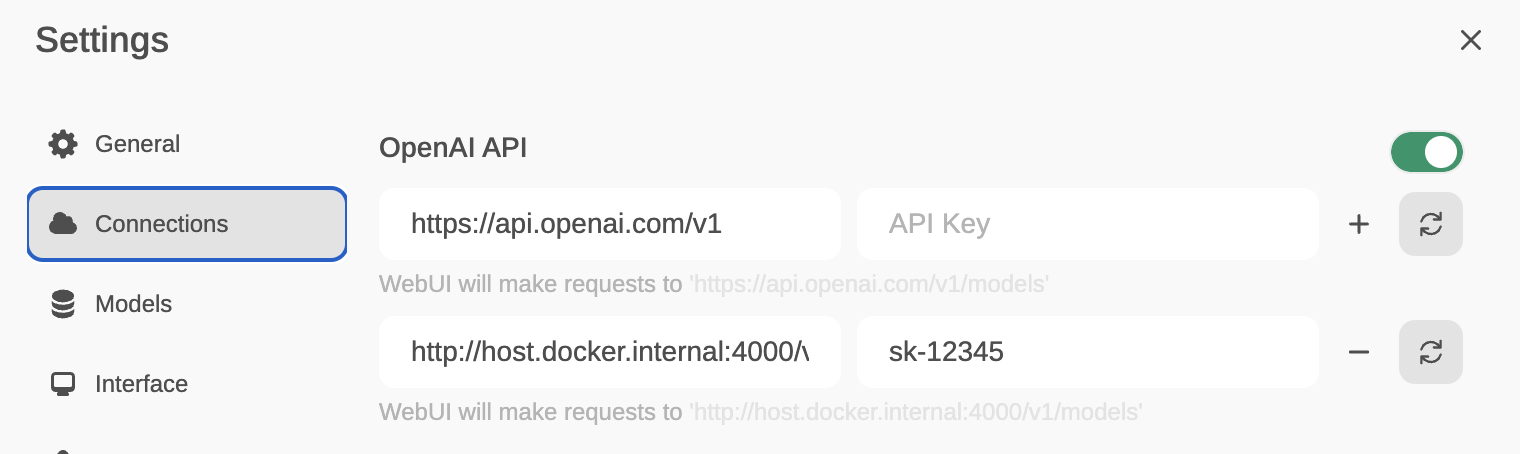
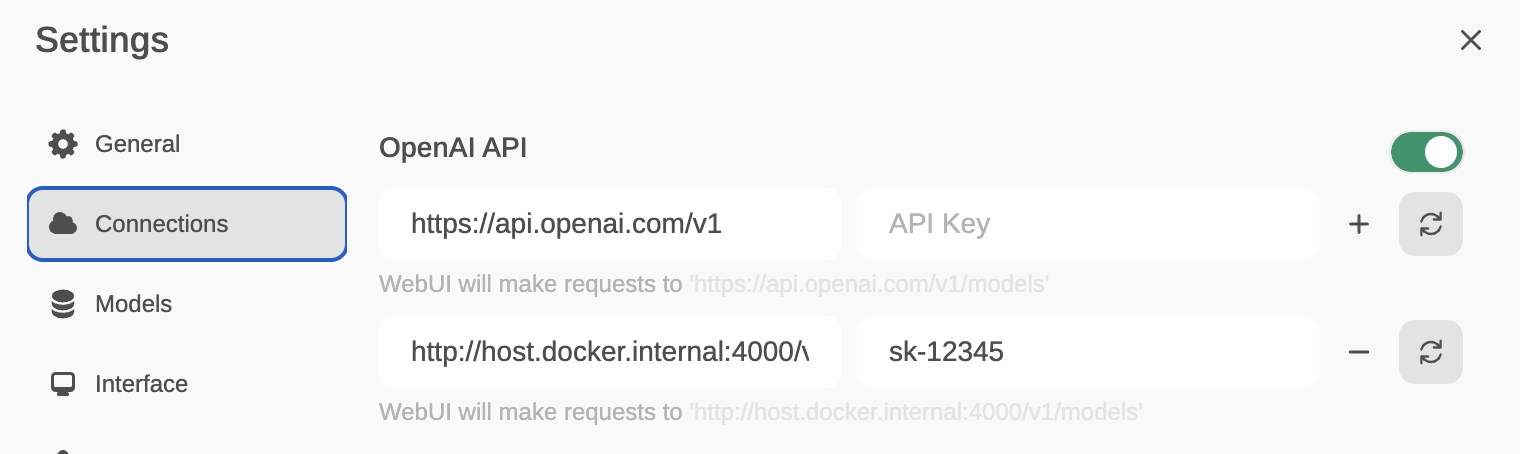
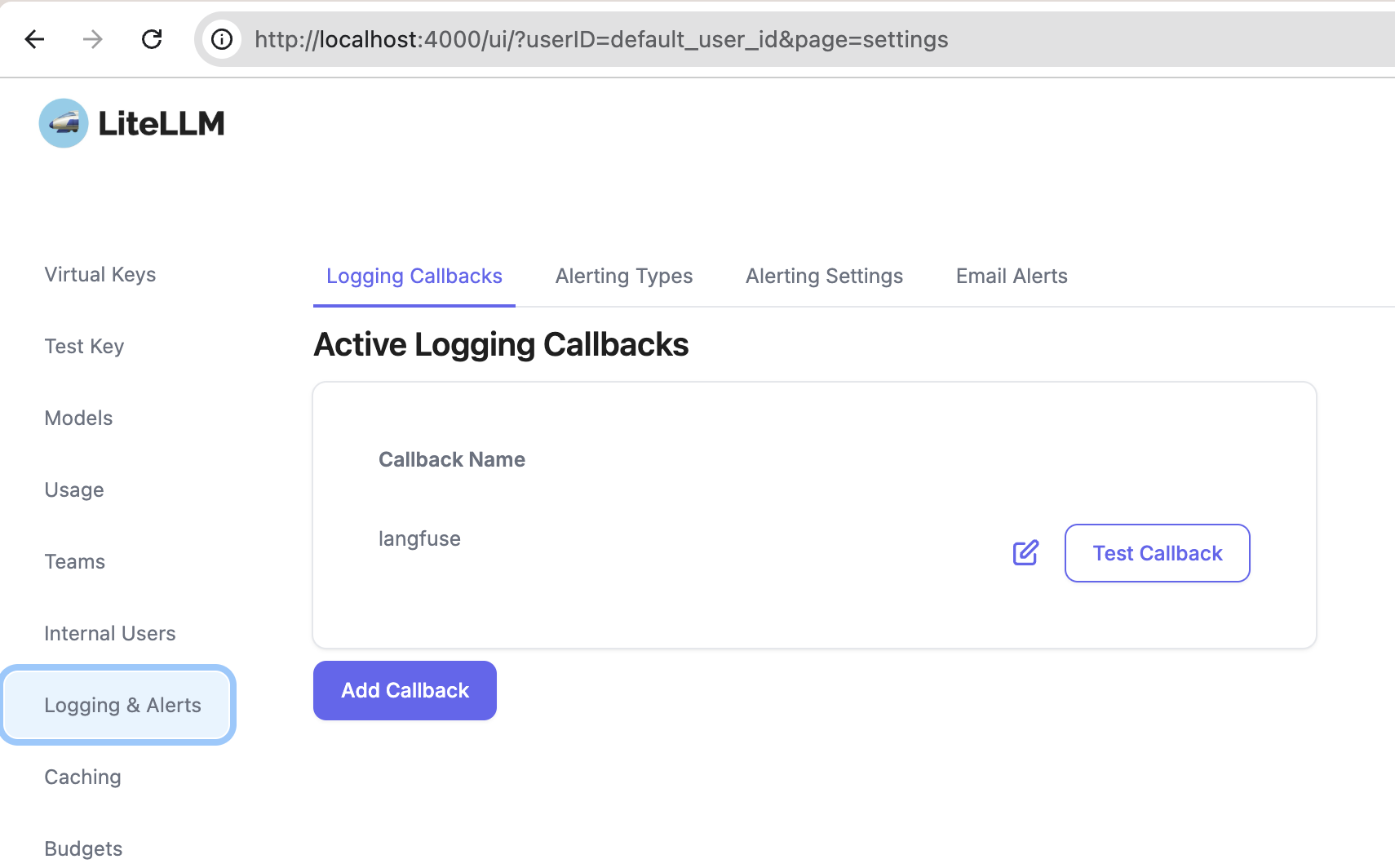
Pulsa en Logging&Alerts -> Add Callback
Elige langfuse y a continuación, teclea los parámetros indicados:
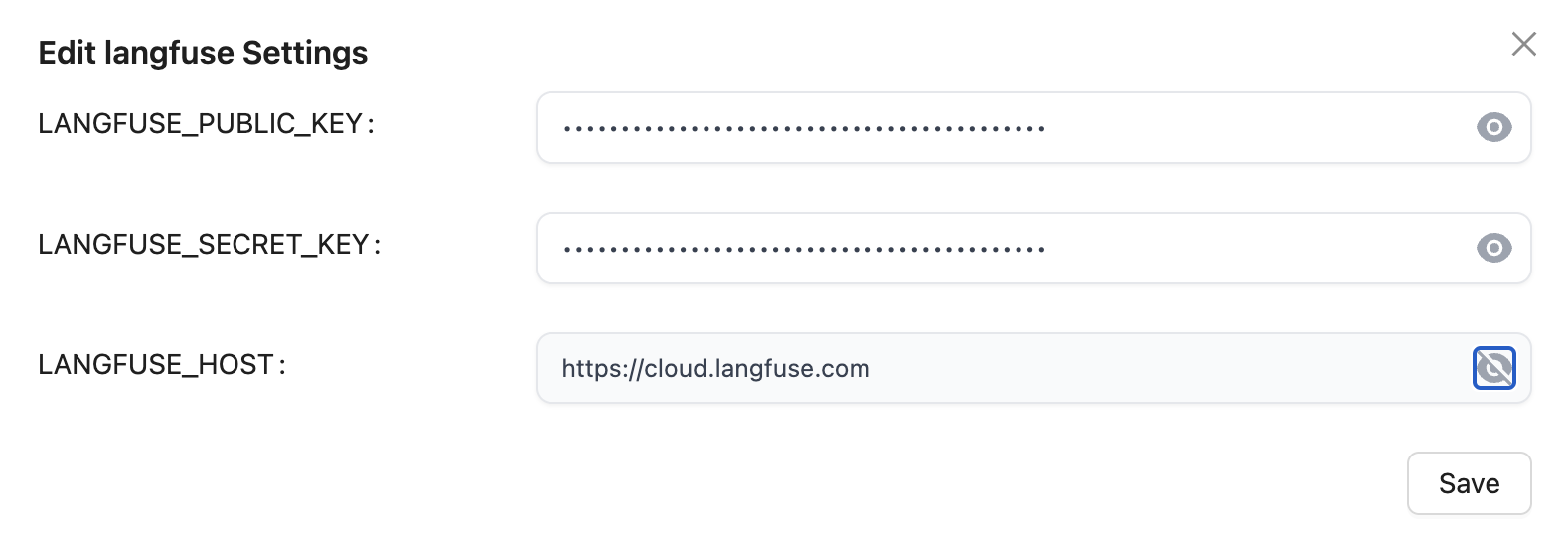
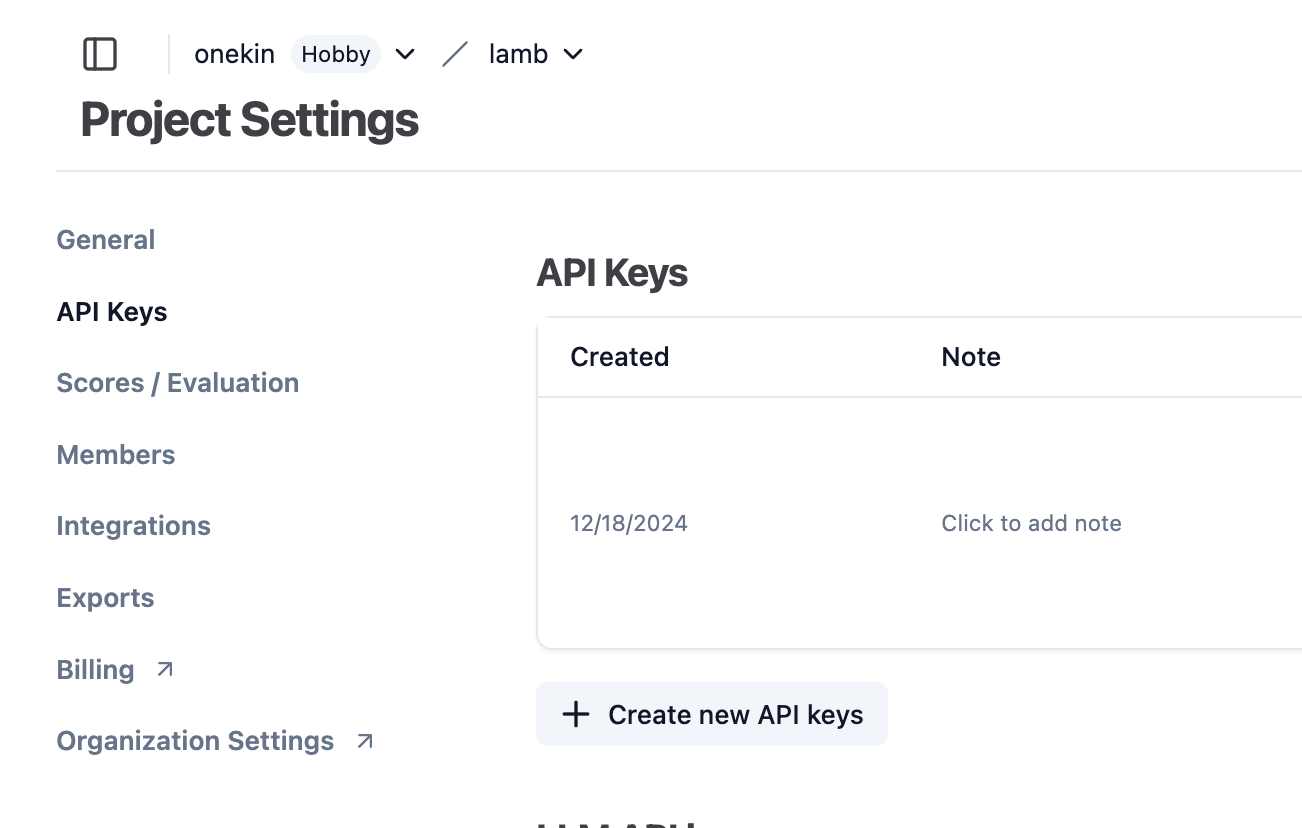
Puedes obtener el public_key y secret_key creando una cuenta gratuita en langfuse. https://cloud.langfuse.com/
Crea un proyecto y obtén los api keys:
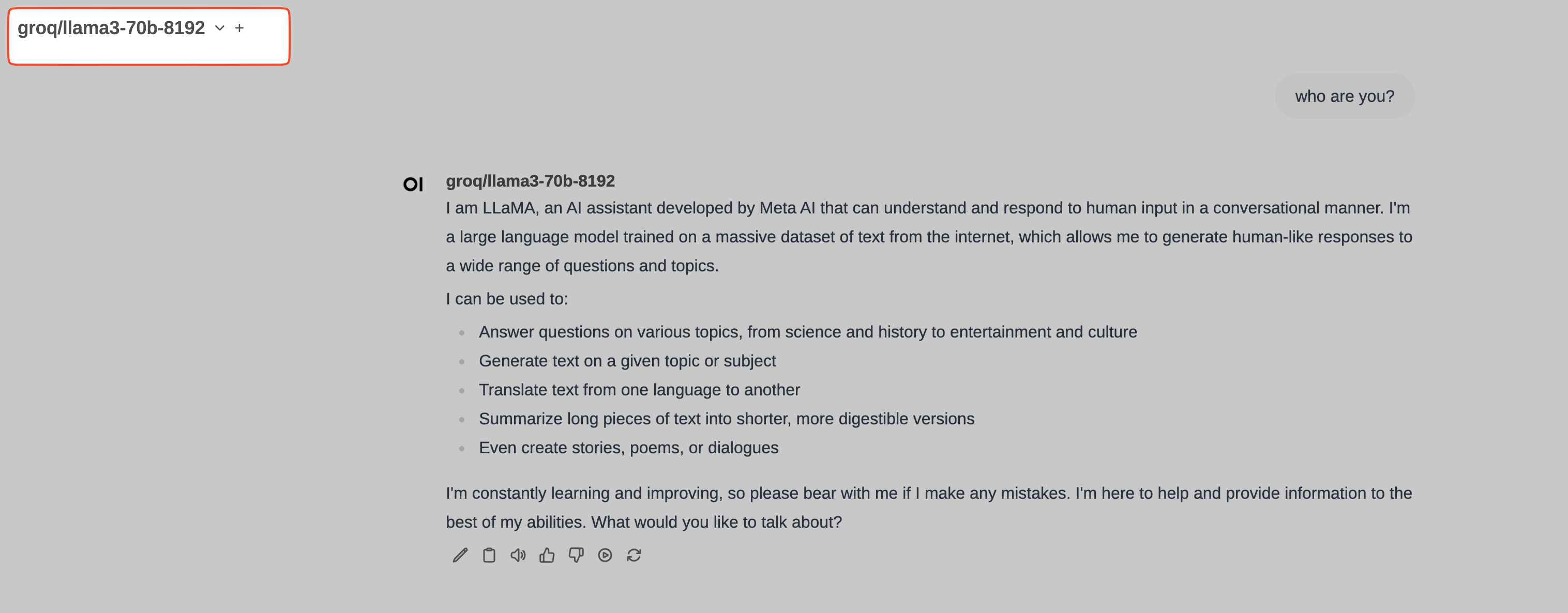
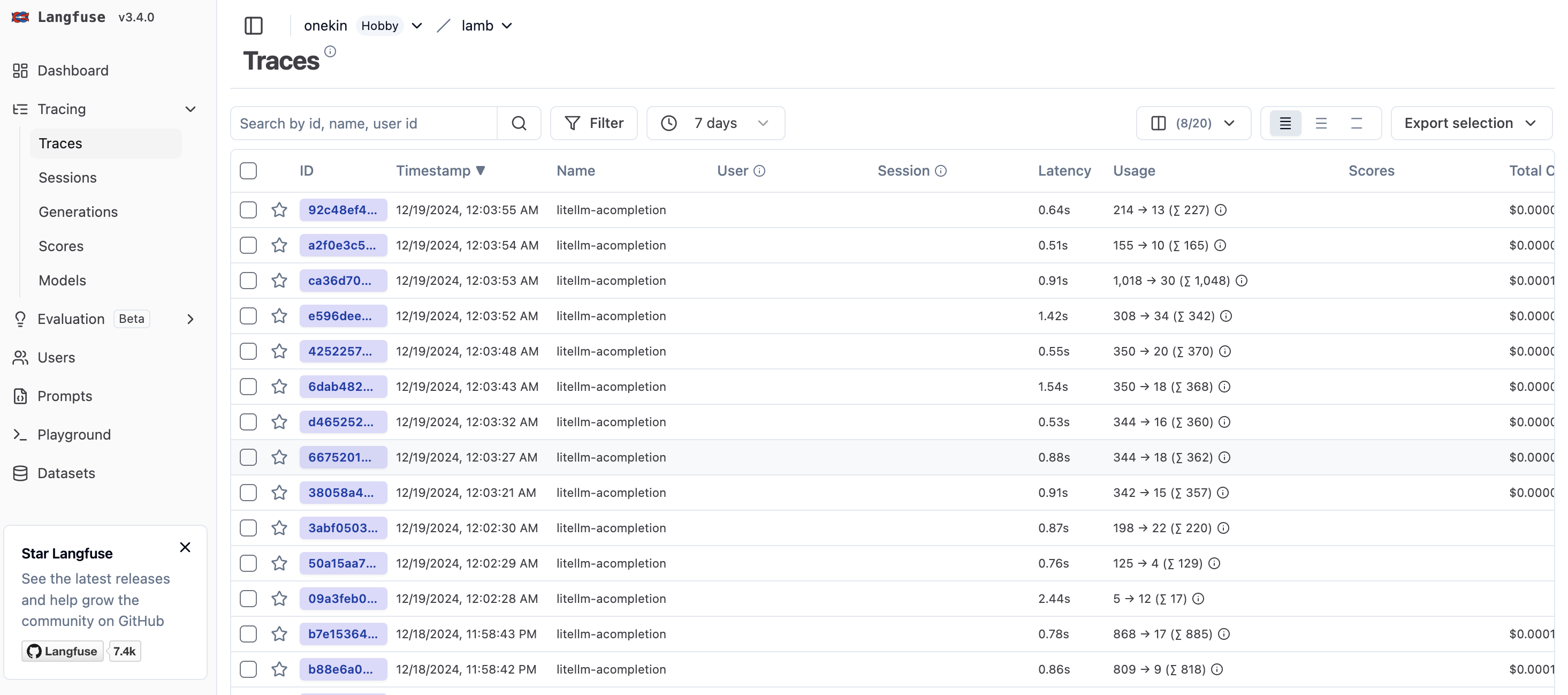
Prueba a pulsar en el Test Callback y deberías ver a los pocos segundos una nueva entrada de test en los logs de langfuse:
Más info:
https://robert-mcdermott.medium.com/centralizing-multi-vendor-llm-services-with-litellm-9874563f3062