LiteLLM es un paquete que simplifica las llamadas a API de varios proveedores de LLM (Large Language Model), como Azure, Anthropic, OpenAI, Cohere y Replicate, permitiendo realizar llamadas en un formato consistente similar al de la API de OpenAI. Integrado con OpenWebUI permite usar este interfaz de usuario contra cualquier proveedor LLM. En mi caso, uso OpenWebUI+LiteLLM para hacer consultas a groq/llama3-70b, Anthropic Claude Opus 3, GPT-4o y Gemini-1.5-pro, entre otros.
El problema es que la release 0.2.0 de OpenWebUI dejó de integrar una versión de LiteLLM. Eso no quiere decir que no se pueda usar, sino que hay que lanzar LiteLLM aparte, a través de un container Docker, por ejemplo.
Esa orden lanza LiteLLM a la escucha en el puerto 4000, usando config.yaml como fichero de configuración. El fichero config.yaml puede ser algo como este (no te olvides de introducir tus API Keys):
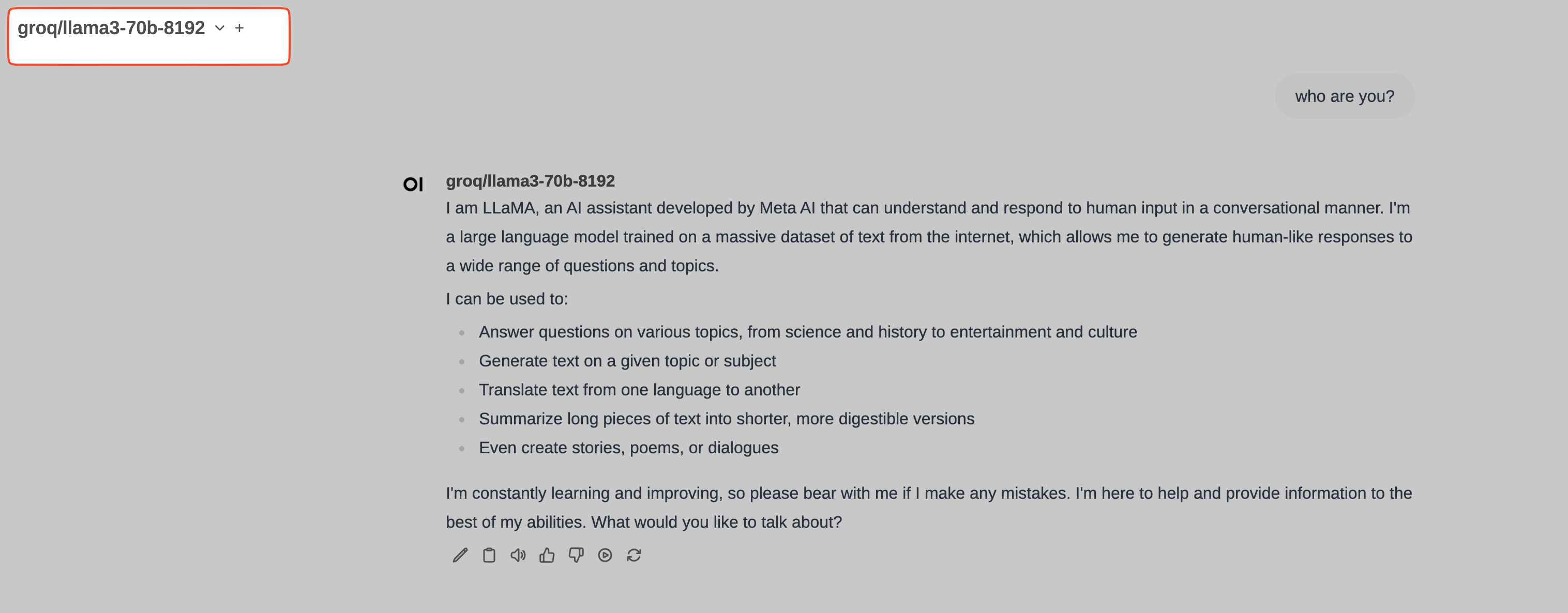
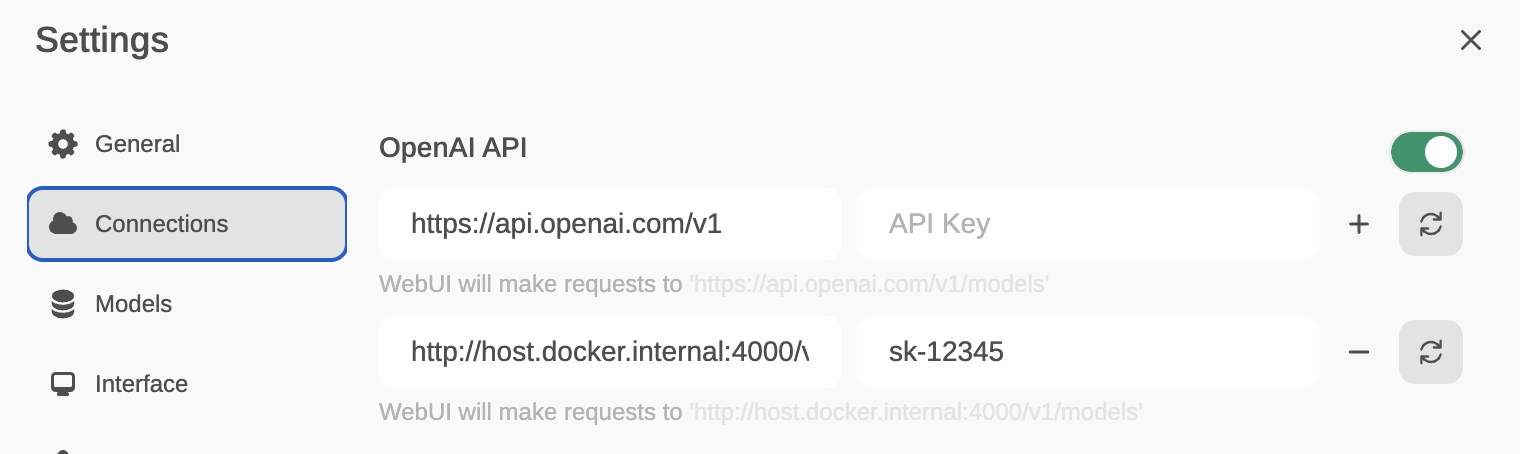
Ahora, desde OpenWebUI, entramos en Settings/Connections e introducimos http://host.docker.internal:4000/v1 en el campo host y sk-12345 (o la clave que hayas puesto a LiteLLM cuando lo lanzaste vía docker) en el API-Key.
Pipelines is defined as a UI-Agnostic OpenAI API Plugin Framework. In essence, it allows injecting plugins that intercept user prompts before they are sent to the final LLM, process them, and then send the processed prompt to the LLM. What can this be used for? For example, to execute functions based on what a prompt requires before sending it to the LLM (simple example: what time is it? What’s the weather like in Donostia?), to consult external databases and inject responses as prompt context (RAG), to execute code…
Pipelines is agnostic to the UI client, as long as the client supports the OpenAI API. Being a creation of the OpenWebUI team, the first UI to support Pipelines is, of course, OpenWebUI.
There are two types of pipelines: filters and pipes.
Filters: Regardless of the model you choose (although you can determine for which models you want to apply it, by default it is for all), the user’s prompt – Form Data – will go through the filter (entering through an inlet function), will be processed, and will exit the filter already processed (via an outlet function). Or, it could be that it doesn’t need to be processed, in which case the model will respond as usual.
Pipeline filters are only compatible with Open WebUI. You can think of a filter pipeline as a middleware that can be used to edit the form data before it is sent to the OpenAI API.
Pipes: The user must choose the pipe they want to apply to their prompt – Form Data. This will go through the pipe and be returned as a response (context) that can then be used for other questions. For example, we can select Wikipedia as a pipe, ask it to inject the first paragraphs of a Wikipedia entry into the context, and then continue asking questions.
Let’s see how to get Pipelines up and running with OpenWebUI 0.2.2.
Testing Pipelines
I will assume that you already have OpenWebUI 0.2.2 running and all you need to know is how to launch and use Pipelines. The easiest way to do this is via Docker. We launch Pipelines like this:
We can see the logs it leaves us with this command:
$ docker logs -f pipelines
Connecting OpenWebUI with Pipelines
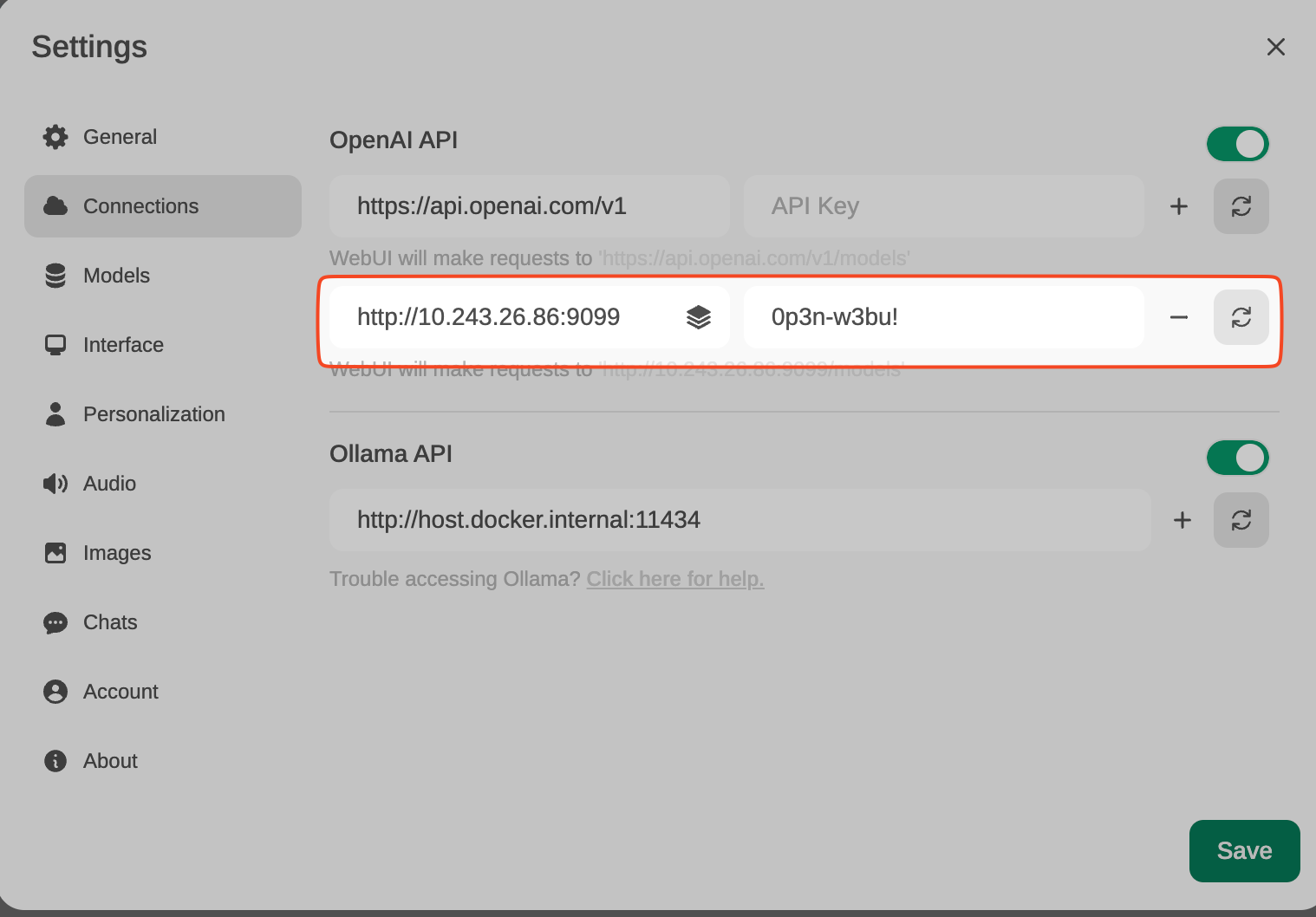
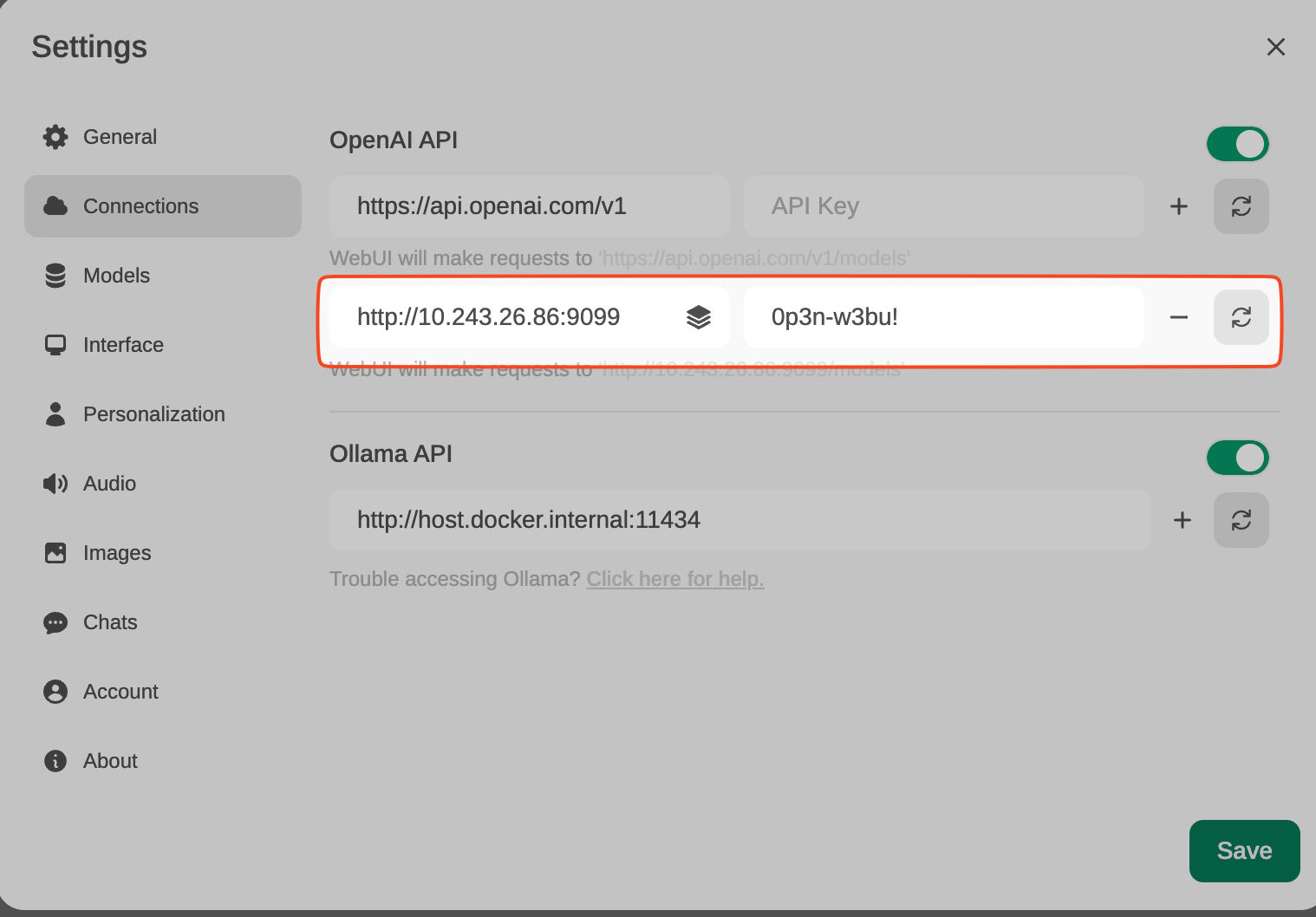
From Settings, create and save a new connection of type OpenAI API, with these details:
URL: http://YOUR_IP_ADDRESS:9099 (the previous docker has been launched here). Pass: 0p3n-w3bu!
Adding a Function Calling Pipeline
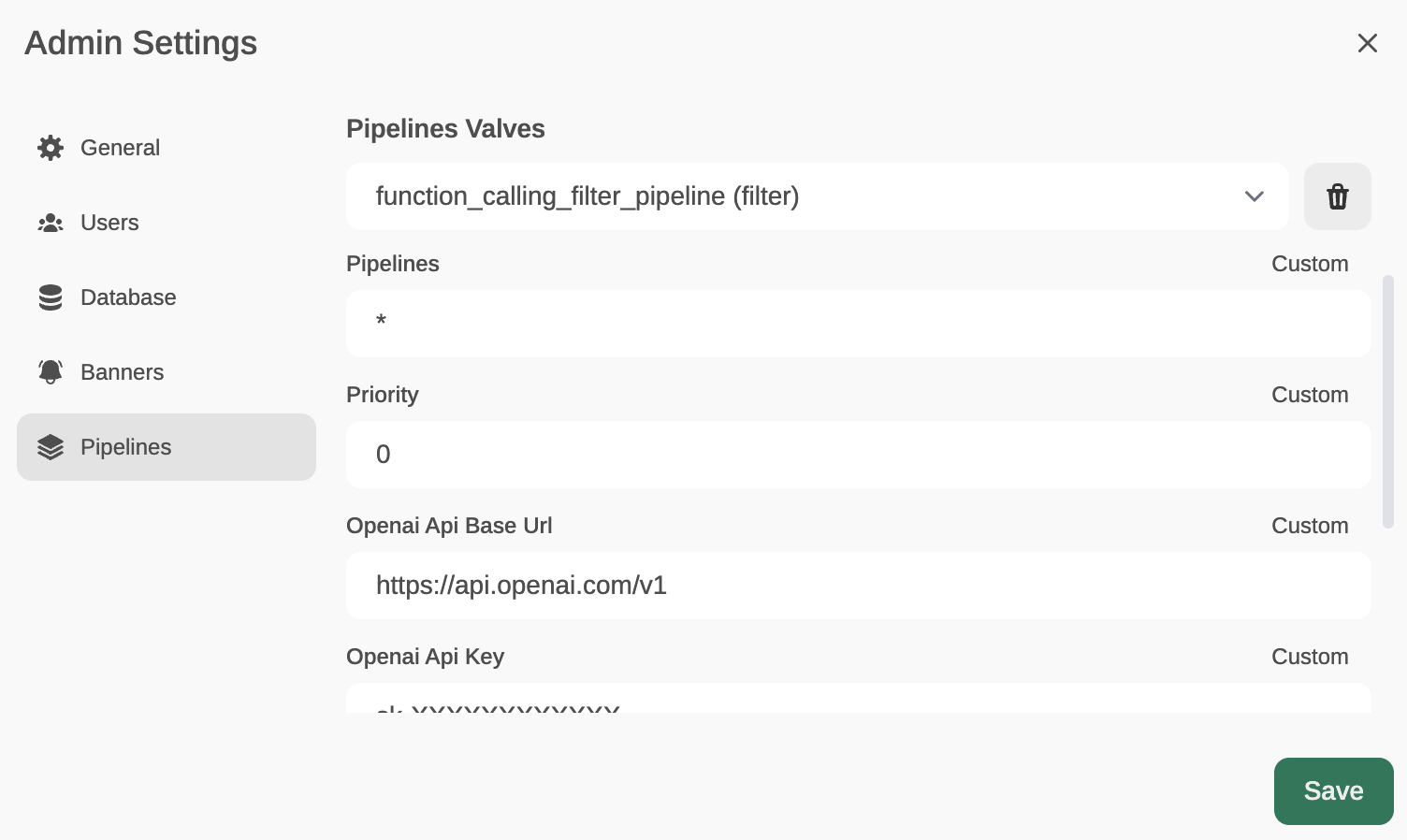
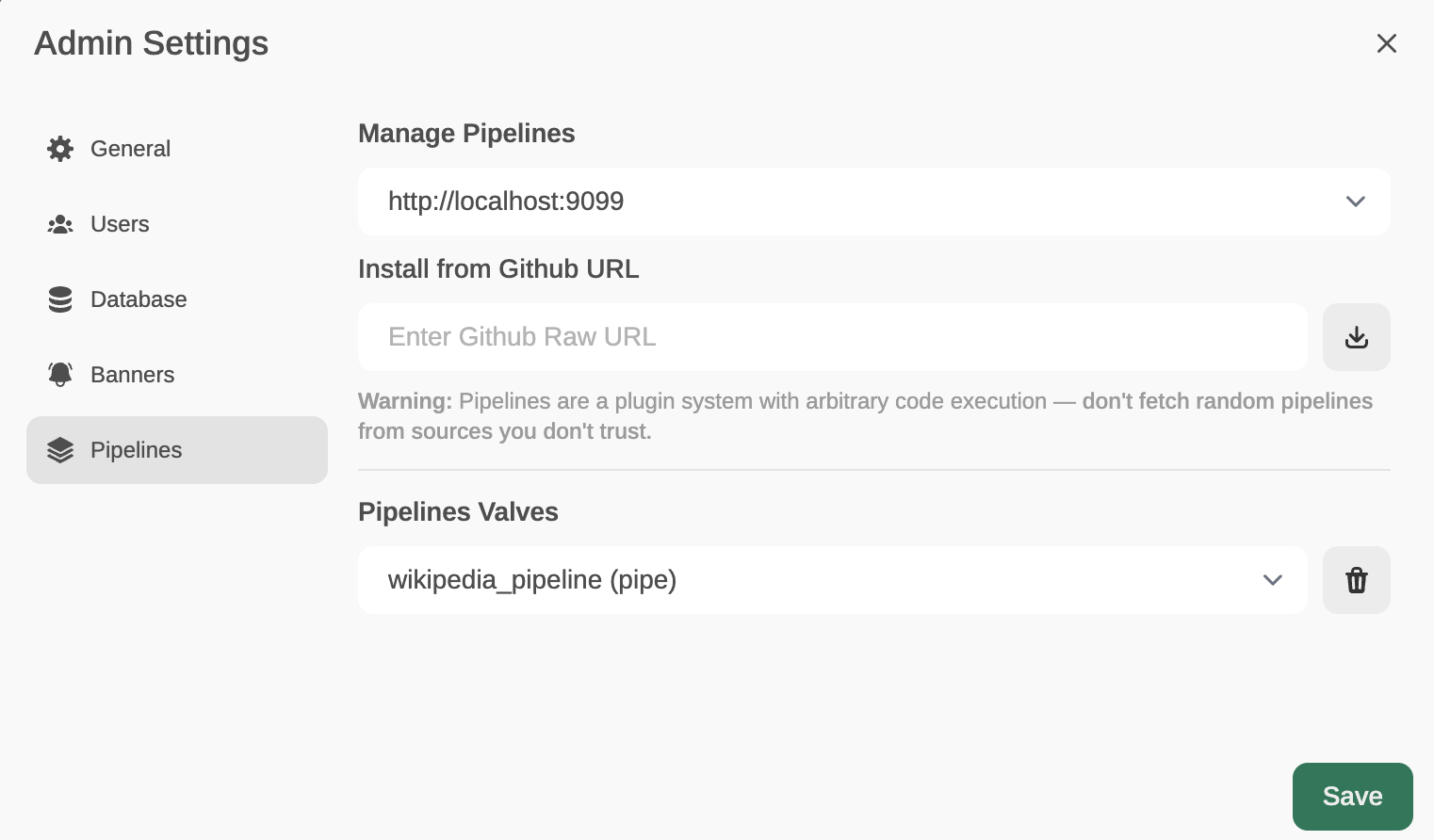
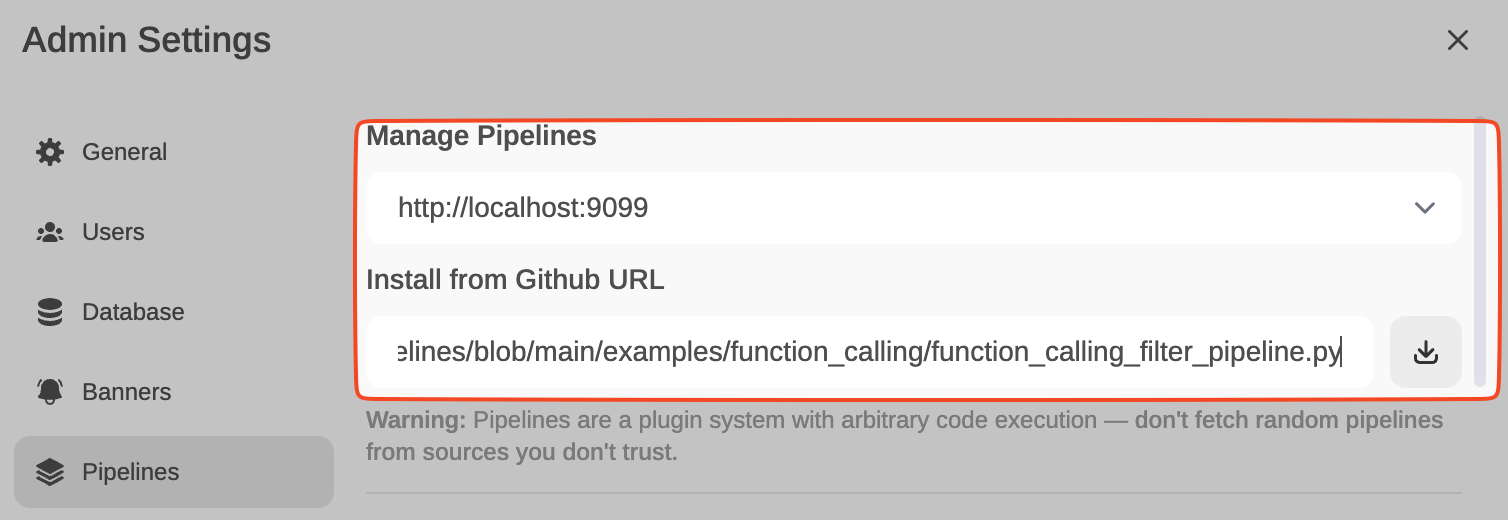
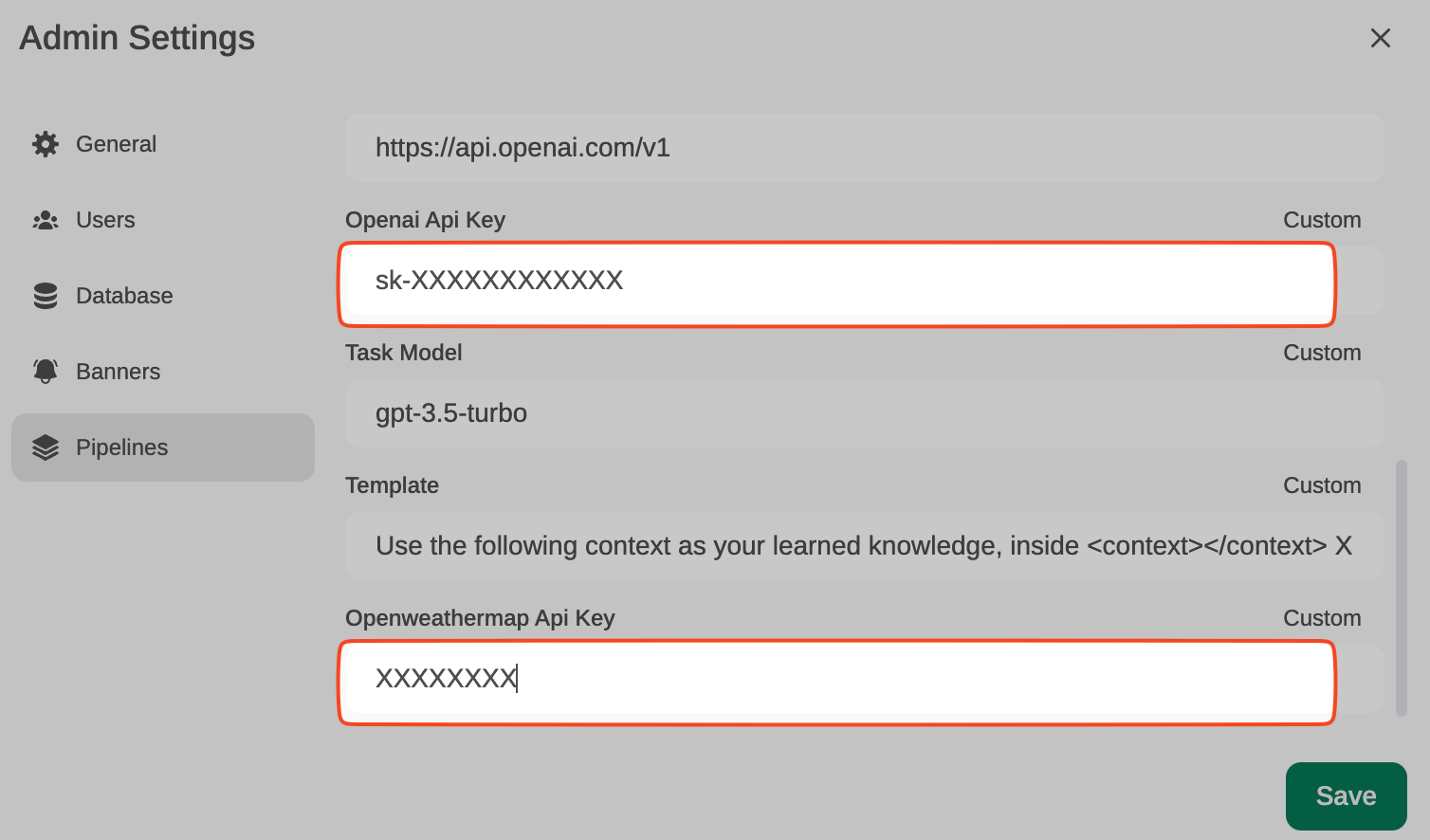
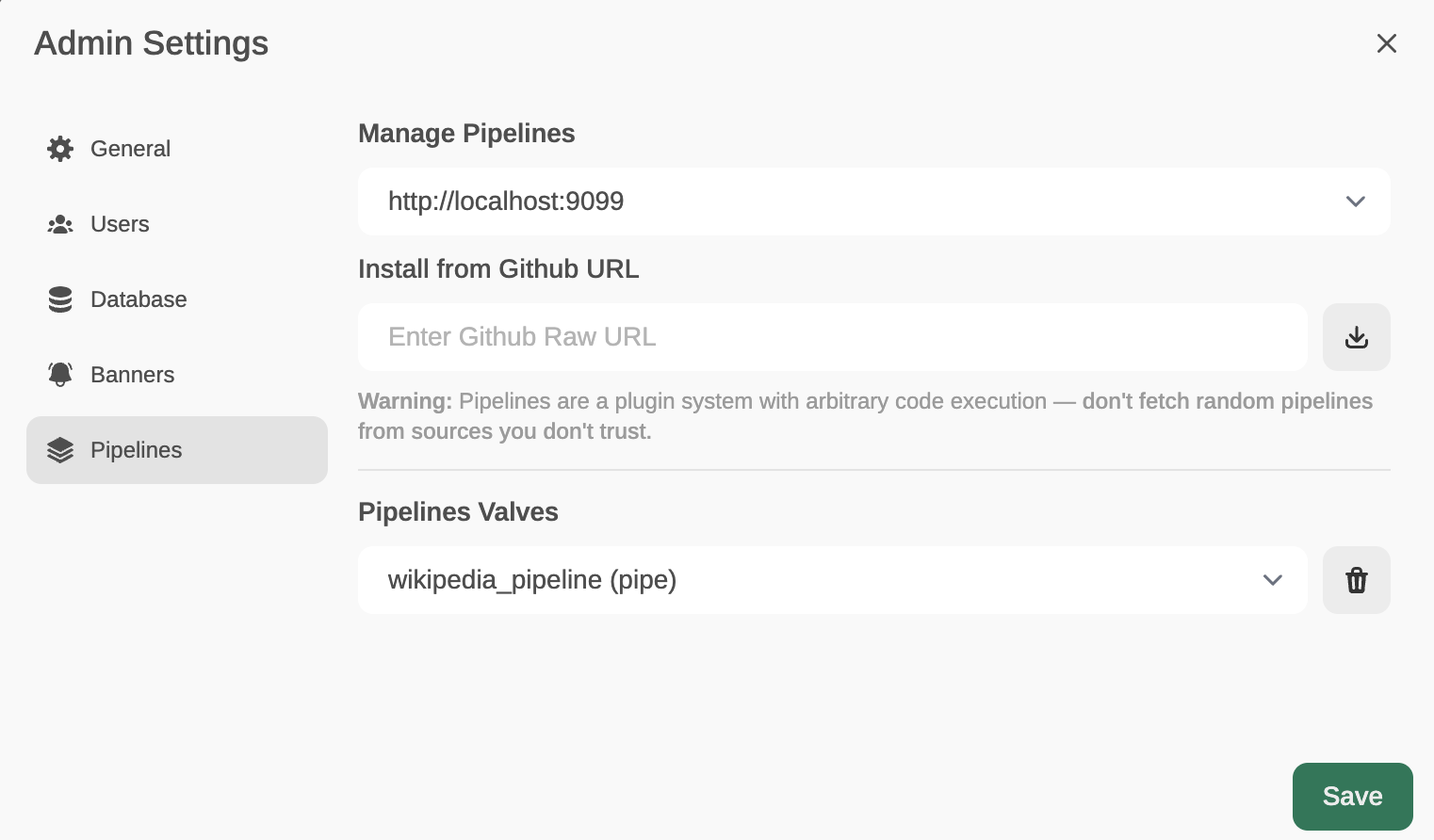
Now, from Admin Settings / Pipelines, we will add our first filter: Function Calling. We will do this by indicating that Pipelines is listening on http://localhost:9099 (where we configured it before) and that we want to install the following Function Calling filter from GitHub: https://github.com/open-webui/pipelines/blob/main/examples/function_calling/function_calling_filter_pipeline.py
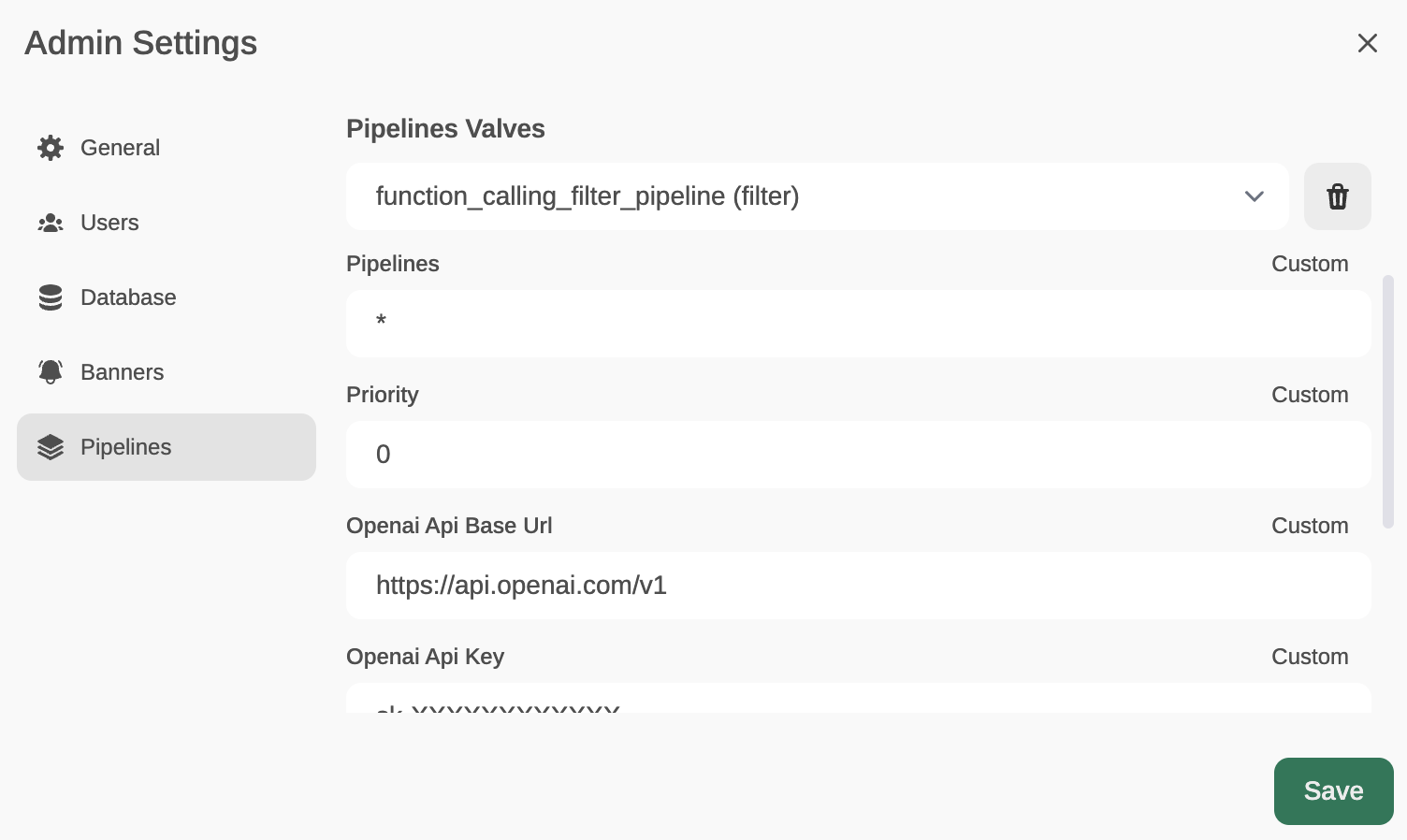
We can specify which models the pipeline affects (by default, all *), the priority (it is possible to chain pipes, the one with a lower number will be the highest priority) and in this case, also the OpenAI API Base URL, its API key and the model to use. For instance, GPT-3.5-Turbo. This LLM will be used to decide whether the user’s prompt needs to be answered through a function or not, and if so, the model will decide which function to use (something like function calling, but through prompt-responses with normal GPT-3.5, internally I’ve seen that it doesn’t use function calling).
In the template, you can specify the prompt that GPT 3.5-Turbo will receive to decide whether it is necessary to execute a function (and which one) or lets the prompt pass through without needing to execute any function (in which case it would respond with an empty function name)
The last parameter, OpenWeatherMap API key will be used to respond (if necessary) to the user’s prompt that is requesting to know the weather in a location.
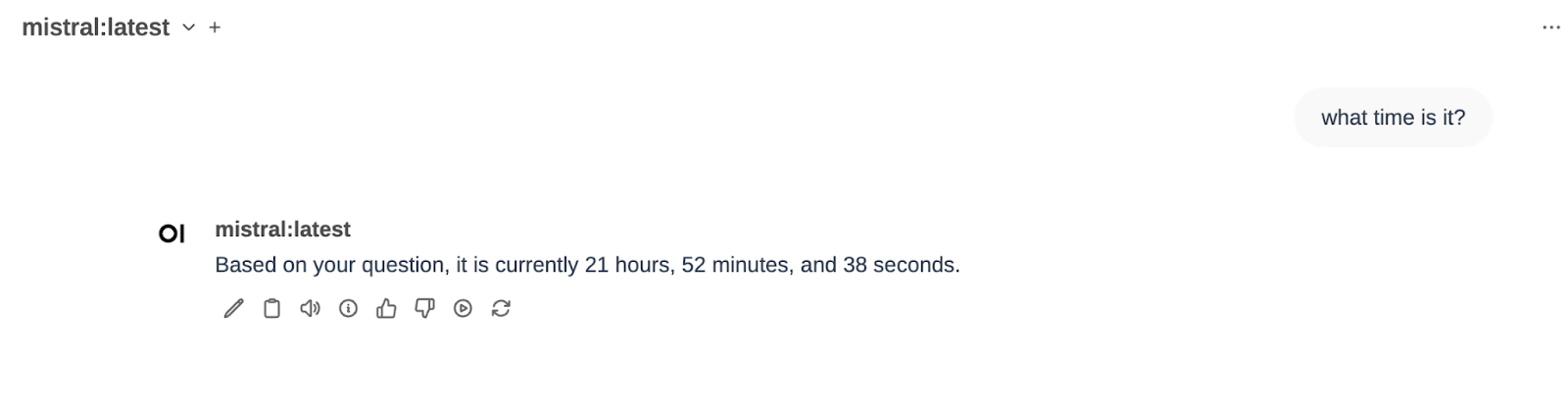
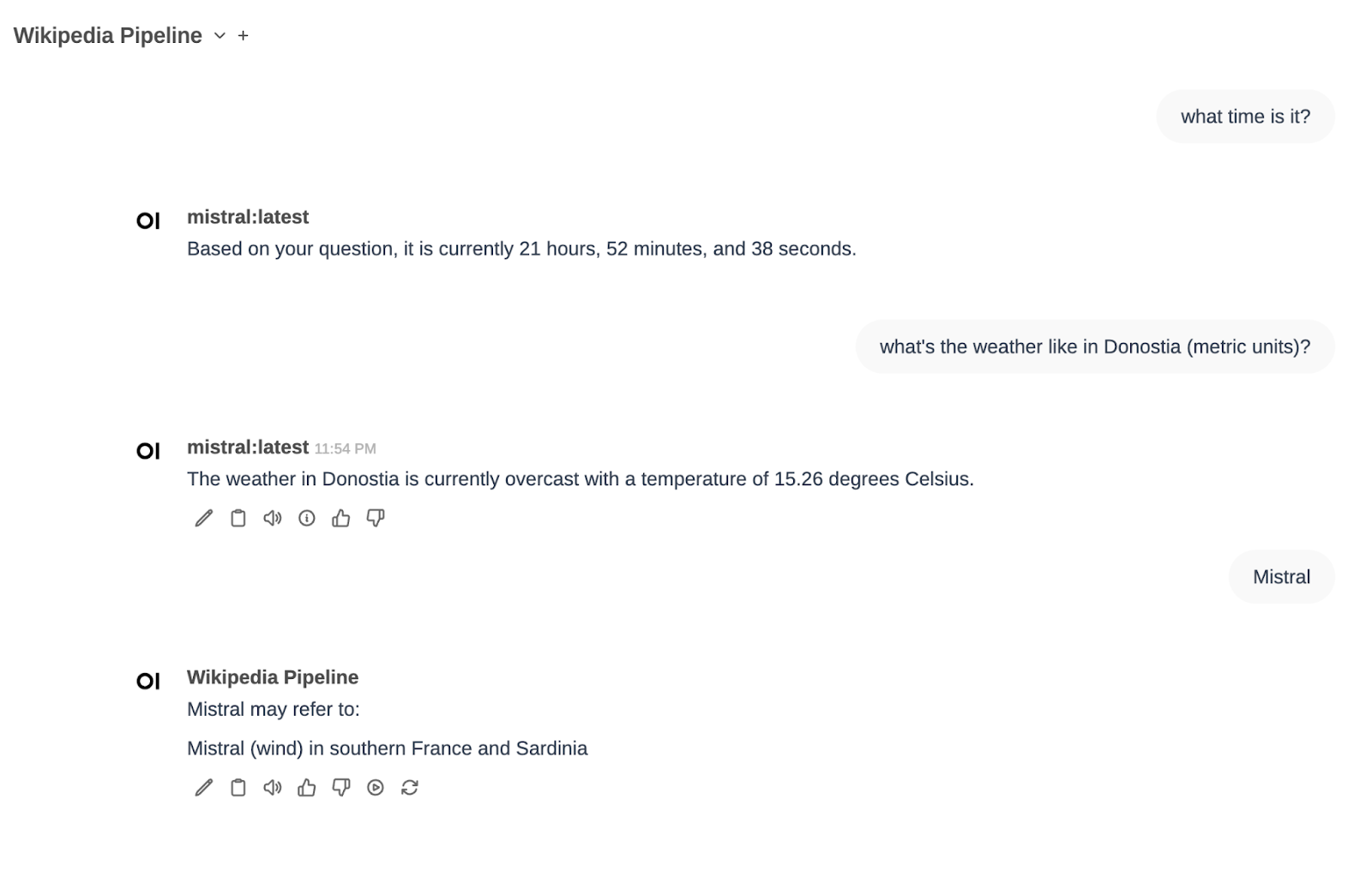
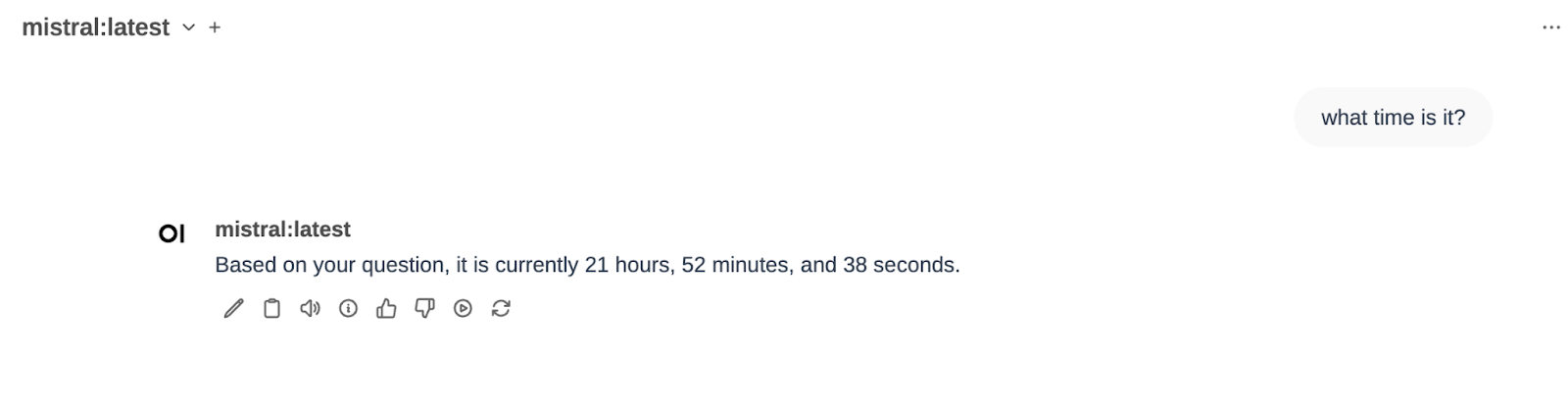
Let’s try it out. We choose a model in OpenWebUI (in my case, mistral:latest) and ask for the current time (I did it last night).
It works!
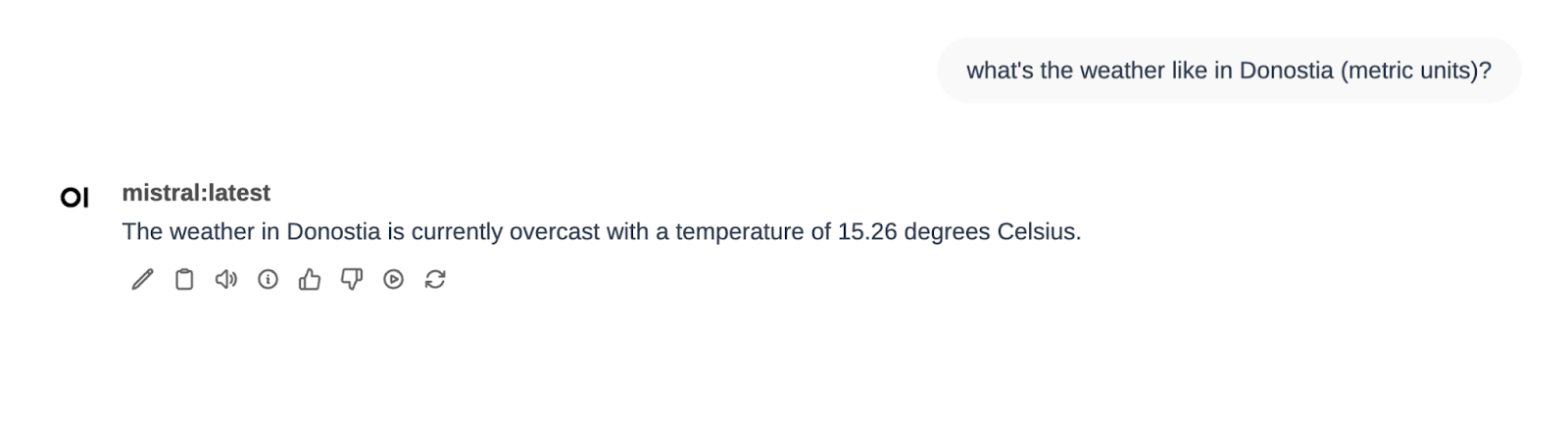
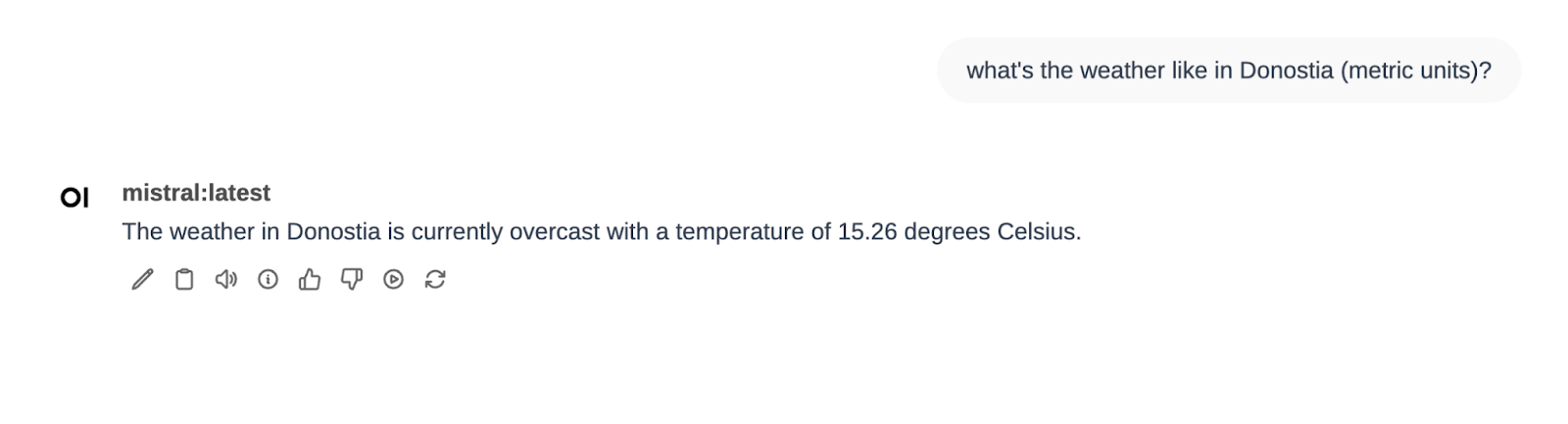
In the same Function Calling filter, we also have two other tools defined: Weather and Calculator. Let’s try the weather one…
Perfect!
Adding a Pipe: Wikipedia Pipe
As mentioned, Pipes can also be used instead of Filters. An example would be the use of Wikipedia. As before, from the Admin settings, we add this pipeline: https://github.com/open-webui/pipelines/blob/main/examples/pipelines/integrations/wikipedia_pipeline.py
Click on the small gear icon (top-right corner) for displaying Admin Settings:
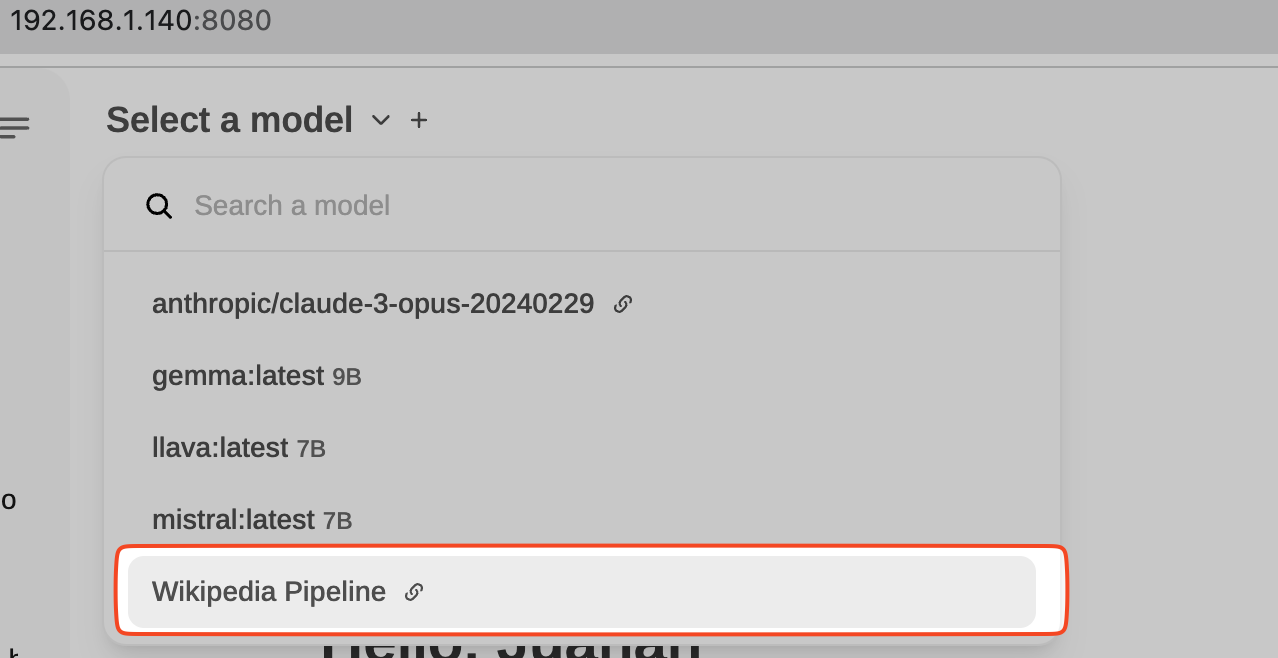
We will now see that we have a new model available in OpenWebUI:
Let’s try it. We select the Wikipedia Pipeline model and search for ‘Mistral AI’:
It works perfectly.
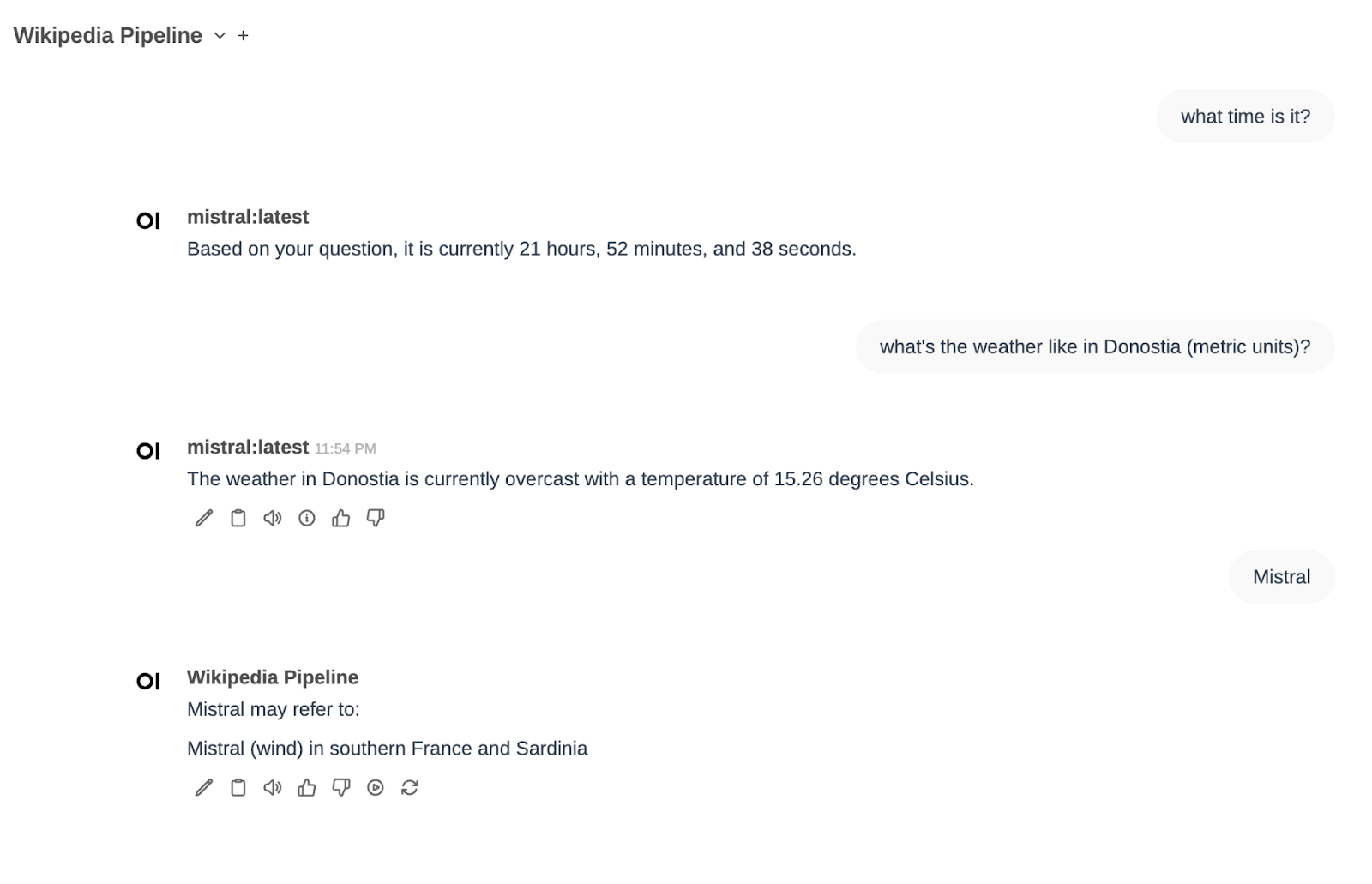
And one last test with everything at once:
I have chosen mistral as the model, and I have asked for the time («What time is it»). The function calling pipeline has determined that it is something that can be answered by executing the function of getting the system time and has returned the current time to me.
After that I asked for the weather in Donostia and it told me the temperature. Finally I selected the Wikipedia Pipe and asked about Mistral. There I saw that I wasn’t explicit enough (Mistral can be several things…)
In a second attempt, I requested information about Mistral AI. This time I found the information I wanted, as we saw before.
Pipelines es la nueva creación del equipo de Open WebUI, encabezado por @timothyjbaek (https://github.com/tjbck) y @justinh-rahb (https://github.com/justinh-rahb)
Pipelines se define como a UI-Agnostic OpenAI API Plugin Framework. En resumidas cuentas permite inyectar plugins que interceptan el prompt del usuario antes de enviarlo al LLM final, lo procesan y se lo envían, ya procesado, al LLM. ¿Y para qué puede servir esto? Por ejemplo para ejecutar funciones en base a lo que requiera un prompt antes de enviarlo al LLM (ejemplo sencillo: ¿qué hora es? ¿qué tiempo hace ahora en Donostia?…), para consultar bases de datos externas e inyectar las respuestas como contexto del prompt (RAG), para ejecutar código…
Pipelines es agnóstico del cliente UI, basta con que éste cliente soporte el API de OpenAI. Al ser una creación del equipo de OpenWebUI el primer UI que soporta Pipelines es, por supuest, OpenWebUI.
Hay dos tipos de pipelines: filtros y pipes.
Filtros: da igual el modelo que elijas (aunque se puede determinar para qué modelos quieres aplicarlo, por defecto es para todos), el prompt del usuario – Form Data – pasará por el filtro (entrando por una función de inlet), si es necesario se procesará y saldrá por el filtro ya procesado (outlet). Podría ser que no fuera necesario ser procesado, en tal caso, el modelo responderá como siempre.
Pipes: el usuario debe elegir el pipe que quiere aplicar a su prompt – Form Data. Este pasará por el pipe y será devuelto como respuesta (contexto) que luego podrá ser usado para otras preguntas. Por ejemplo, podemos seleccionar Wikipedia como un pipe, pedirle que inyecte los primeros párrafos de una entrada de wikipedia en el contexto y luego seguir preguntando.
Veamos cómo ponerlo en marcha Pipelines con OpenWebUI 0.2.2.
Probando Pipelines
Asumiré que ya tienes OpenWebUI 0.2.2 lanzado y lo único que necesitas es saber cómo lanzar y usar Pipelines. Lo más sencillo será hacerlo vía Docker. Lanzamos Pipelines así:
Ahora, desde Admin Settings / Pipelines, añadiremos nuestro primer filtro: Function Calling.Lo haremos indicando que Pipelines está a la escucha en http://localhost:9099 (donde lo hemos configurado antes) y que queremos instalar el siguiente filtro de Function Calling desde GitHub: https://github.com/open-webui/pipelines/blob/main/examples/function_calling/function_calling_filter_pipeline.py
Podemos especificar a qué modelos afecta el pipeline (por defecto, a todos *), la prioridad (es posible encadenar pipes, el que tenga un número menor será el más prioritario) y en este caso, también el OpenAI API Base URL, su key y el modelo. Por ejemplo, GPT-3.5-Turbo. Este LLM será usado para decidir si el prompt del usuario necesita ser respondido a través de una función o no, y en caso afirmativo, el modelo decidirá qué función usar (algo com function calling, pero a través de prompts-respuestas con GPT-3.5 normales, internamente he visto que no usa function calling).
En el template se puede especificar el prompt que recibirá GPT 3.5-Turbo para decidir si es necesario ejecutar una función (y cuál) o deja pasar el prompt sin necesidad de ejecutar ninguna función (en cuyo caso respondería con el nombre de función vacío)
El último parámetro, OpenWeatherMap API Key servirá para responder (si es necesario) al prompt del usuario que esté solicitando conocer el tiempo que hace en una localidad.
Vamos a probarlo. Elegimos un modelo en OpenWebUI (en mi caso, mistral:latest) y preguntamos por la hora actual (lo hice ayer a la noche 🙂
¡Funciona!
En el mismo filtro de Function Calling tenemos también definidas otras dos tools, Weather y Calculator. Probemos la de weather…
Perfecto 🙂
Añadiendo un Pipe: Wikipedia Pipe
Tal y como hemos comentado, también se pueden usar Pipes en lugar de Filters. Un ejemplo sería el uso de Wikipedia.
Igual que antes, desde los settings de Admin, añadimos este pipeline: https://github.com/open-webui/pipelines/blob/main/examples/pipelines/integrations/wikipedia_pipeline.py
Veremos ahora que tenemos un nuevo modelo disponible en OpenWebUI:
Vamos a probarlo. Seleccionamos el modelo Wikipedia Pipeline y buscamos ‘Mistral AI’:
¡Funciona!
Y una última prueba con todo a la vez:
He elegido mistral como modelo, y he preguntado por la hora («What time is it»). El pipeline de function calling ha determinado que es algo que se puede responder ejecutando la función de obtener la hora del sistema y me ha devuleto la hora actual.
Después he pedido el tiempo en Donostia y me ha dicho la temperatura. Finalmente he seleccionado el Pipe de Wikipedia y he preguntado por Mistral. Ahí he visto que no he sido lo suficientemente explícito (Mistral puede ser varias cosas…)
En un segundo intento, he solicitado información sobre Mistral AI. En esta ocasión he encontrado la información que quería, como hemos visto antes.
Los sistemas LLM son mejor aprovechados cuantos más conocimientos de ingeniería software en general y de programación en particular tengas.
¿Cómo preguntas al LLM que te ayude a generar un endpoint de un API REST si no sabes lo que significan esos términos?
¿Qué harás cuando el LLM te responda con código incorrecto que no hace lo que tiene que hacer? informar a la IA del error a veces funciona… pero otras veces la IA entrará en un ciclo sin fin.
¿Cómo limitarás el contexto de lo que quieres preguntar a la IA para que esta pueda responder dentro de los limites máximos del tamaño del input si no sabes programar y/o no entiendes el código que estás intentando programar?
¿Cómo preguntarás a una IA para que te ayude a refactorizar código para hacerlo más legible, mantenible, extensible si no tienes conocimientos sobre estos conceptos? (por no hablar de aplicar patrones de diseño…)
Así que cuando oigas a un CEO (por ejemplo al de Nvidia) diciendo que con la IA ya no hará falta aprende a programar, pregúntate si esa persona tiene algún interés en vender esa falacia.
¿Podría un LLM leer todo un repositorio Git y sugerir mejoras? ¿Podría soportar el LLM, con su limitación del tamaño de contexto un repositorio Git de un proyecto de Ingeniería Software de un curso de grado?
Vamos a probarlo. Empecemos con una herramienta que captura los ficheros de un repositorio Git y los convierte en un único string que podemos usar en nuestro super-prompt: https://github.com/mpoon/gpt-repository-loader [1]
$ python gpt_repository_loader.py /opt/facultyproject/src/main/java/faculty/project -o /tmp/faculty.txt
Repository contents written to /tmp/faculty.txt.
Si echamos un vistazo a /tmp/faculty.txt veremos lo siguiente:
$ head -20 /tmp/faculty.txt
The following text is a Git repository with code. The structure of the text are sections that begin with ----, followed by a single line containing the file path and file name, followed by a variable amount of lines containing the file contents. The text representing the Git repository ends when the symbols --END-- are encounted. Any further text beyond --END-- are meant to be interpreted as instructions using the aforementioned Git repository as context.
----
ui/ApplicationLauncher.java
package faculty.project.ui;
import faculty.project.businessLogic.BlFacade;
import faculty.project.businessLogic.BlFacadeImplementation;
import java.util.Locale;
public class ApplicationLauncher {
public static void main(String[] args) {
System.out.println("Locale: " + Locale.getDefault());
BlFacade businessLogic = new BlFacadeImplementation();
new MainGUI(businessLogic);
Ahí vemos que le ha metido una cabecera («El siguiente texto representa un repositorio Git con código. La estructura del texto son secciones que empiezan con —, seguido por una línea con la ruta al fichero y sus contenidos…)
Al final del fichero (tras el –END–), meteremos la siguiente línea: Can you suggest how to improve the code?
Y probemos ahora a pasarle el super prompt a un LLM que soporte un gran tamaño de contexto (Gemini Pro 1.5 es un gran candidato):
Dependency Injection: The code currently uses manual object creation, leading to tight coupling. Consider using a dependency injection framework like Spring or Guice to manage object creation and dependencies, improving flexibility and testability.
Exception Handling: The current exception handling is minimal and sometimes throws runtime exceptions. Implement a more robust exception handling strategy, catching specific exceptions and handling them gracefully with informative messages or logging.
Logging: Integrate a logging framework like Log4j or SLF4j to track application behavior, debug issues, and monitor performance.
Testing: Implement unit and integration tests to ensure code quality and prevent regressions. Frameworks like JUnit and Mockito can be helpful.
DataAccess:
Data Access Object (DAO) Pattern: Instead of having all data access logic directly in DataAccess, consider creating separate DAO classes for each entity (User, Student, Subject, etc.) to improve modularity and maintainability.
Named Queries: Utilize named queries in JPQL for frequently used queries to improve readability and maintainability.
Optimistic Locking: Implement optimistic locking to prevent data inconsistencies when multiple users access the same data concurrently.