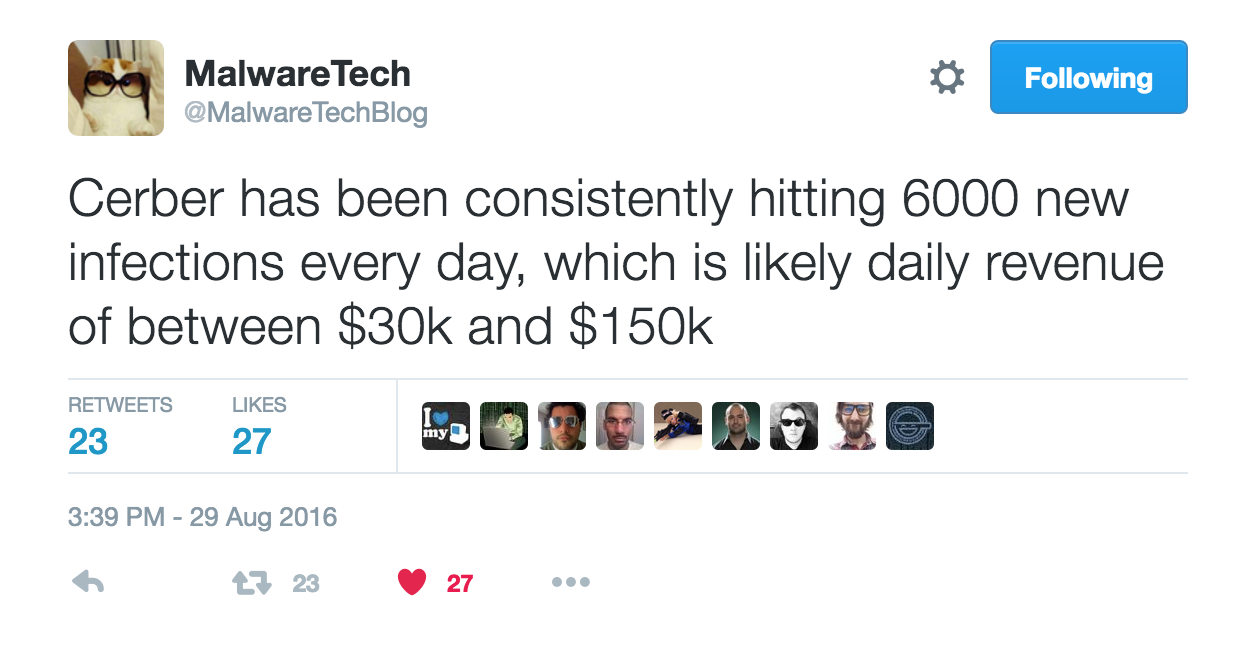
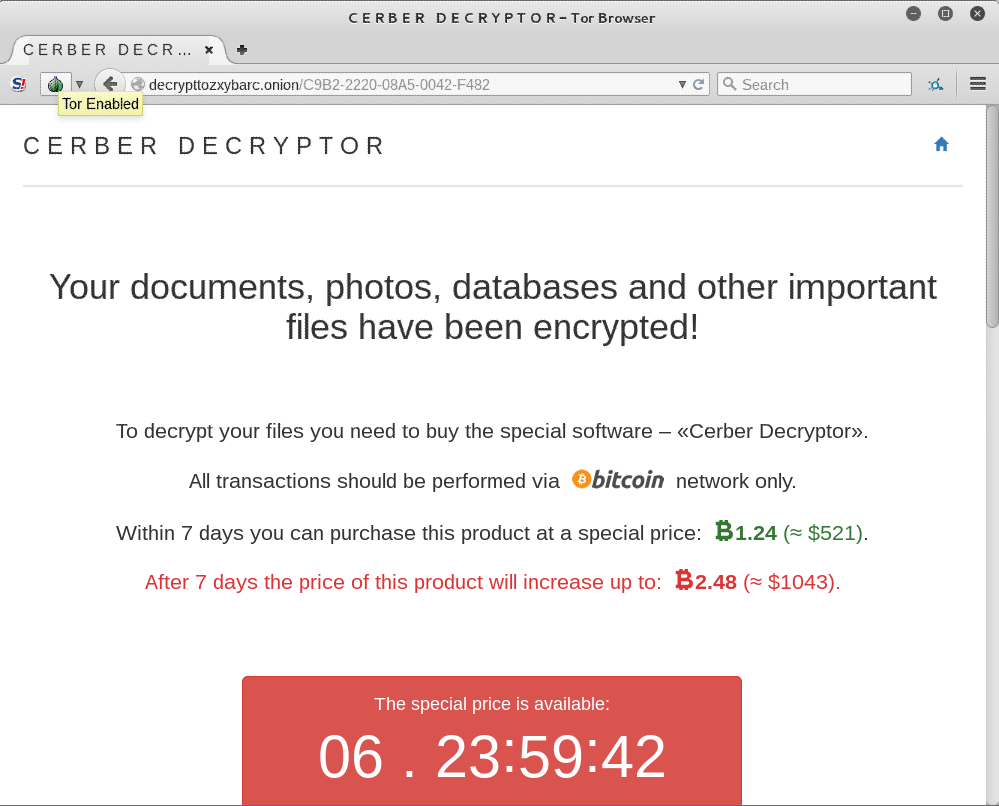
El 30 de marzo saltaba la noticia: las llamadas al sistema de Linux se podrán ejecutar en Windows 10 de forma «nativa» (se podrán traducir en tiempo real a llamadas al sistema de Windows, algo así como un WINE a la inversa):
Intenté probarlo en su día, pero no encontraba tiempo. Tampoco creo que estuviera disponible para todos los usuarios… Hoy he recordado la noticia y le he dedicado un rato porque necesito ejecutar algunas funcionalidades de Linux en una máquina Windows (y la opción de Cygwin me parece demasiado «heavy»… y problemática, la he sufrido en alguno de mis cursos, donde he recibido numerosas peticiones de auxilio 😉
Para probar el subsistema Windows para Linux (Windows Subsystem for Linux o WSL) hay que tener la actualización Windows 10 Anniversary Update (se publicó en Agosto de este año). La forma más sencilla es a través de este enlace oficial a la web de Microsoft. Tras la instalación/upgrade, hay que activar el modo programador entrando en Configuración / Para programadores
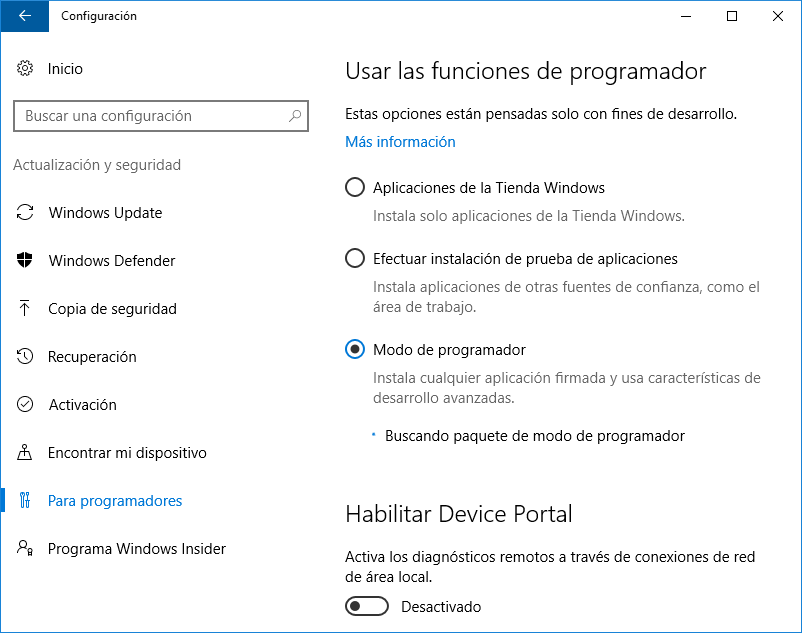
A continuación, entramos en Panel de Control / Programas / Activar o desactivar las características de Windows . Activamos el Subsistema de Windows para Linux (beta) y reiniciamos las veces que haga falta 😛
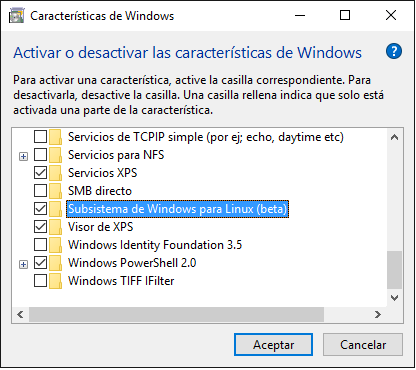
Ahora viene lo bueno. Ejecutamos bash desde el menú de inicio (tecleamos bash y pulsamos intro) y al ser la primera vez se lanzará la instalación:
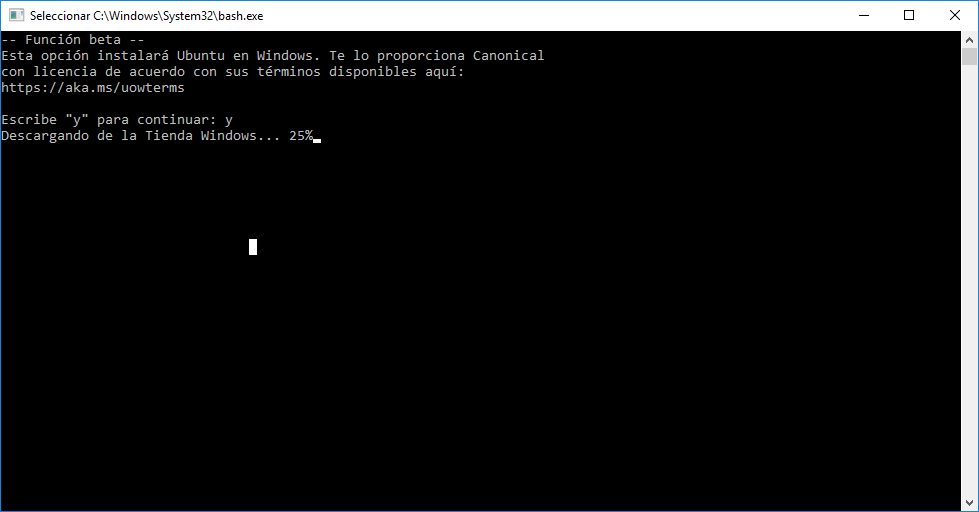
Le costará un rato descargar WSL (al final está descargando una especie de versión de Ubuntu Server) y activarlo. Cuando lo haga, nos pedirá crear un usuario (que por defecto estará en la lista de sudoers)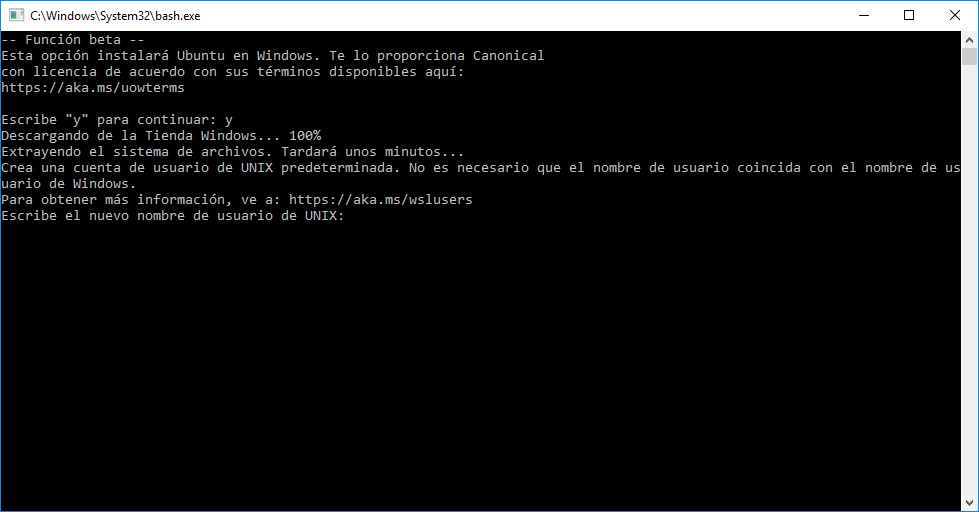
Le asignamos un pass al nuevo user y tachán, ya estamos en Bash 🙂
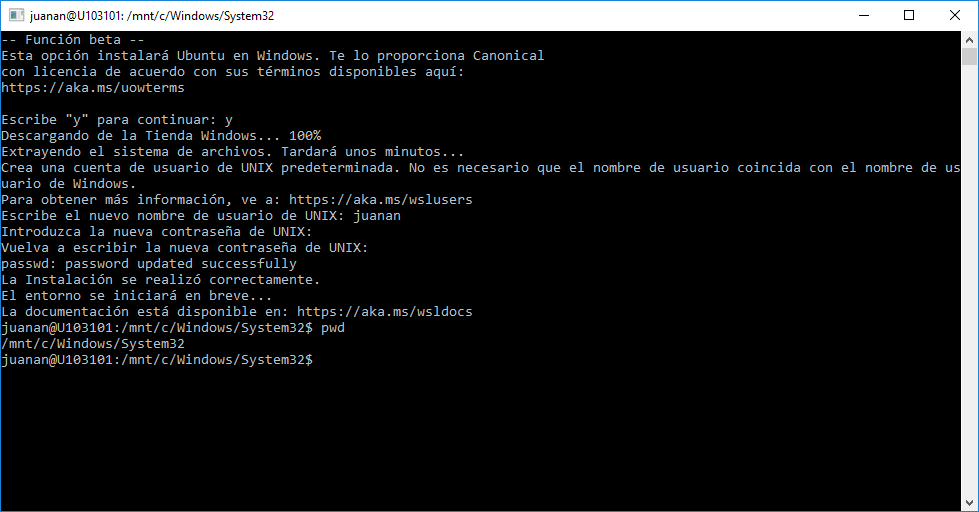
Se hace raro poder ejecutar ls, id, pwd, cat, vi ! , apt (sí apt-get!) en Windows sin recibir mensajes de error…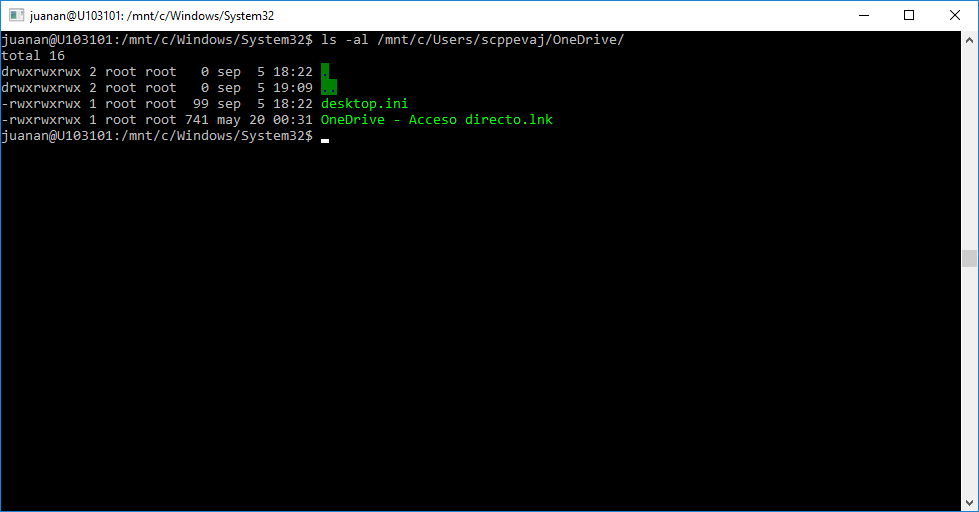
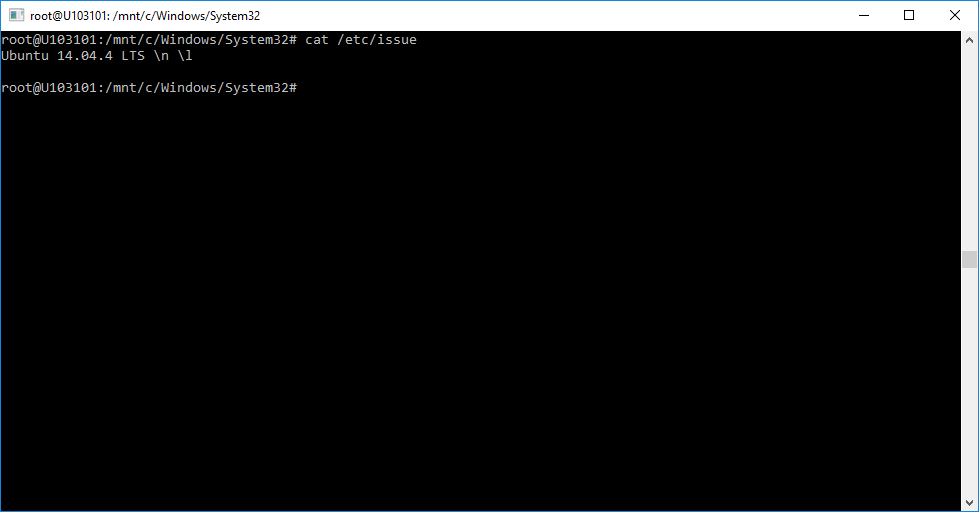
Realmente estamos en Bash dentro de un Ubuntu 14.04 ejecutándose sobre Windows 10. Buf… si me lo llegan a decir hace un tiempo hubiera puesto cara de incrédulo.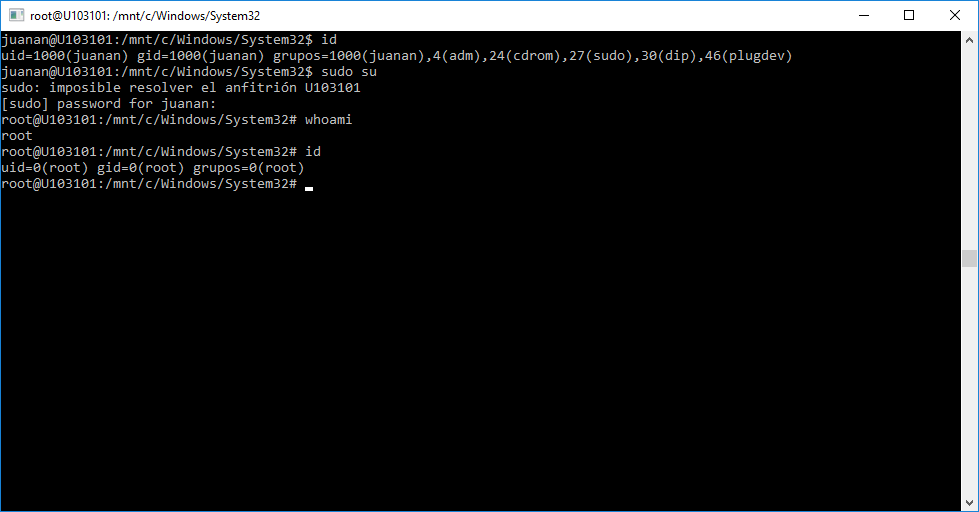
Los archivos están donde deben (en un sistema que siga el LSB) y tienen el contenido esperado.
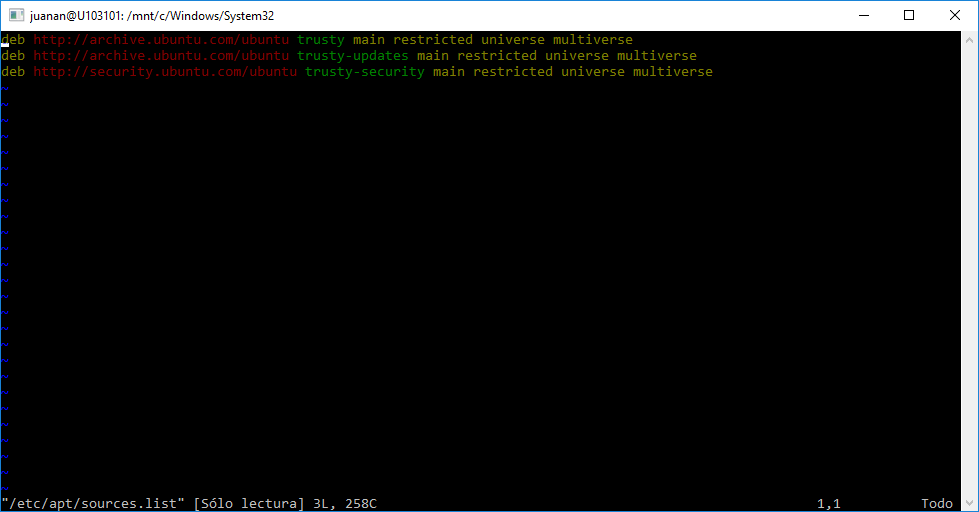
El sistema de archivos del anfitrión Windows está montado en /mnt . Tenemos los repos apt de Ubuntu a nuestra disposición para instalar las aplicaciones que necesitemos.
Otro puntazo a favor es que tenemos un intérprete python y un intéprete perl instalados de serie (los mismos que instala Ubuntu 14.04, claro)
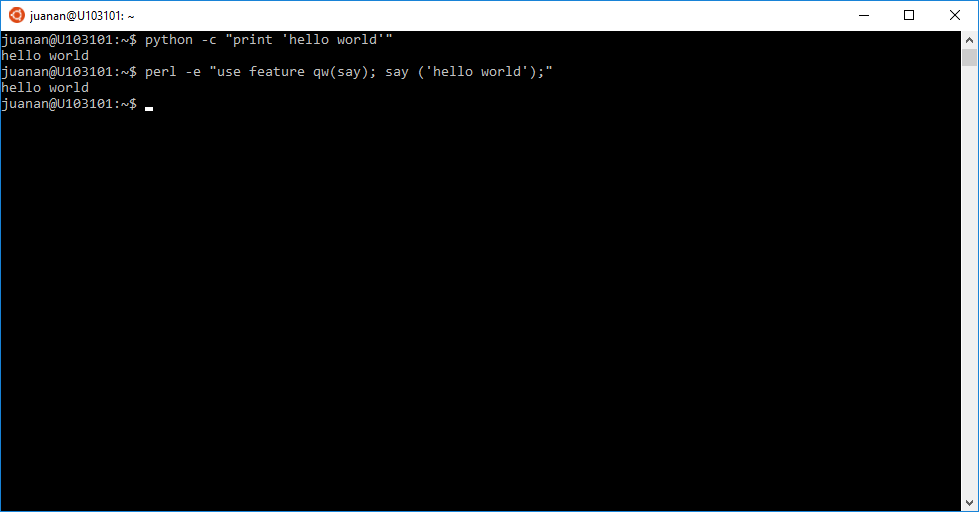
También he visto que hay un servicio ssh lanzado en el puerto 22, pero por lo que he probado NO es openssh (se puede ver el fingerprint del servidor mediante un simple telnet – sí, telnet, para ver el banner del server – al puerto 22), sino un servidor SSH de Windows (yo diría que en alfa, porque aún no he conseguido autenticarme y creedme que he probado de todo). ¿Tal vez sea una implementación en desarrollo del port openssh de Microsoft ?
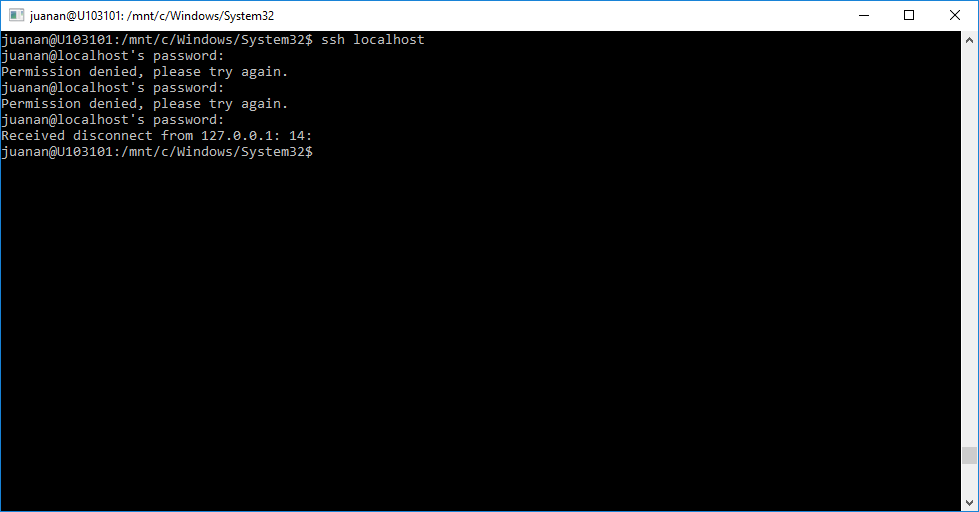
Leyendo algunos foros comentaban que openssh se puede configurar para que escuche en un puerto distinto al 22 (el 60022, por ejemplo), abrir una regla en el firewall de Windows para ese nuevo puerto y listo. Si no lo tenemos instalado por defecto (en mi caso sí lo estaba) siempre podremos instalarlo con sudo apt-get update && sudo apt-get install openssh 🙂
A continuación, modificamos /etc/ssh/sshd_config y lo dejamos así:
Port 60022
ListenAddress 0.0.0.0
Protocol 2
HostKey /etc/ssh/ssh_host_rsa_key
HostKey /etc/ssh/ssh_host_dsa_key
HostKey /etc/ssh/ssh_host_ecdsa_key
HostKey /etc/ssh/ssh_host_ed25519_key
UsePrivilegeSeparation no
KeyRegenerationInterval 3600
ServerKeyBits 1024
SyslogFacility AUTH
LogLevel INFO
LoginGraceTime 120
PermitRootLogin without-password
StrictModes yes
RSAAuthentication yes
PubkeyAuthentication no
IgnoreRhosts yes
RhostsRSAAuthentication no
HostbasedAuthentication no
PermitEmptyPasswords no
ChallengeResponseAuthentication no
PasswordAuthentication yes
X11Forwarding yes
X11DisplayOffset 10
PrintMotd no
PrintLastLog yes
TCPKeepAlive yes
AcceptEnv LANG LC_*
Subsystem sftp /usr/lib/openssh/sftp-server
UsePAM yes
Si openssh ya estaba instalado, antes de reiniciar el server openssh lo reconfiguramos (si no lo hacemos, arrancará, pero no conseguiremos conectar porque no habrá generado los ficheros necesarios):
$ sudo dpkg-reconfigure openssh-server
Ahora sí, reiniciamos el server openssh:
sudo service ssh restart
Y conectamos desde localhost para probar:
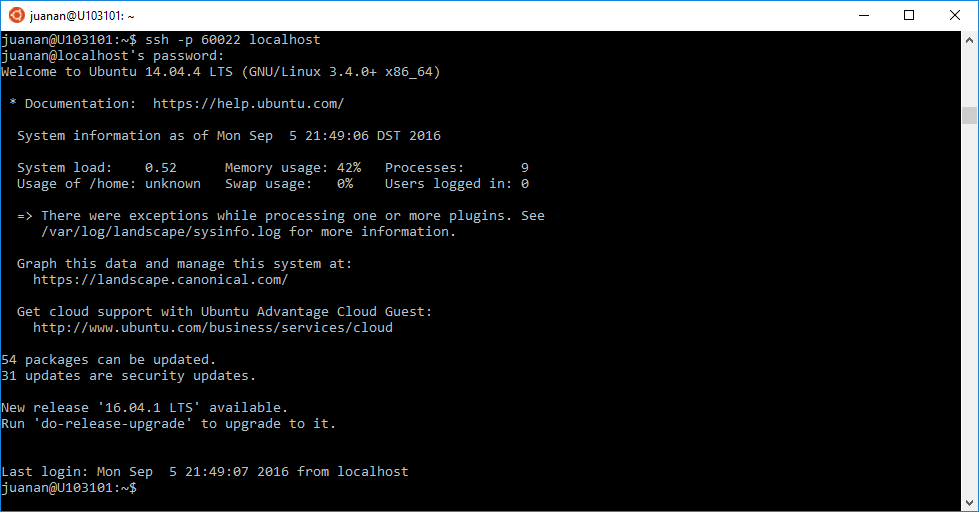
¡Funciona! 🙂
UPDATE (5/09/2016): si en algún momento la liamos parda con la configuración del WSL, siempre podremos desinstalar y volver a instalar con dos sencillos comandos:
C:\> lxrun.exe /uninstall /full
C:\> lxrun.exe /install
UPDATE (6/09/2016): es posible iniciar el servidor openssh de WSL al arrancar el equipo. Para ello, basta con parar el Server SSH de Microsoft (el que viene por defecto) y lanzar OpenSSH con la configuración indicada, salvo que ahora podremos lanzarlo en su puerto natural, el 22. Además, si queremos lanzar el servidor cada vez que iniciemos el equipo, podremos crear un script de arranque.
 DailyMotion bideoak online partekatzeko plataforma bat da, YouTube edo Vimeo bezalakoa. Astelehenean bertan jakinarazi zutenez urriaren 20an eraso bat jaso ostean DailyMotion-eko erabiltzaileen 85 miloi kontuen kredentzialak agerian utzi zituzten (hacker batek informazio hori lortu eta enpresatik atera zuen). Dirudienez datuen artean email helbidea, erabiltzailearen izena eta kasu batzuetan (18 miloi kontuetan) pasahitzen hashak (bcrypt hash funtzioaz lortutakoak, nahiko sendoak beraz, eta krakeatzeko latzak).
DailyMotion bideoak online partekatzeko plataforma bat da, YouTube edo Vimeo bezalakoa. Astelehenean bertan jakinarazi zutenez urriaren 20an eraso bat jaso ostean DailyMotion-eko erabiltzaileen 85 miloi kontuen kredentzialak agerian utzi zituzten (hacker batek informazio hori lortu eta enpresatik atera zuen). Dirudienez datuen artean email helbidea, erabiltzailearen izena eta kasu batzuetan (18 miloi kontuetan) pasahitzen hashak (bcrypt hash funtzioaz lortutakoak, nahiko sendoak beraz, eta krakeatzeko latzak).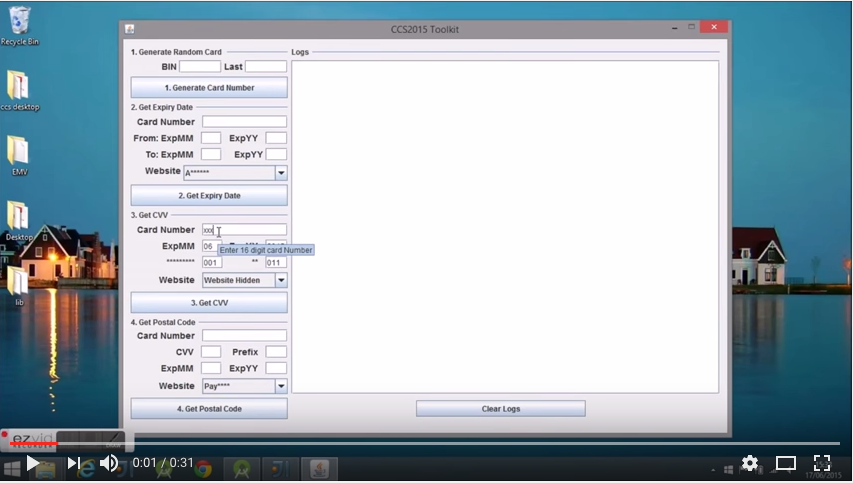 New Castle Unibertsitateko ikerlari talde batek demostratu du VISA txartelen datuak lortzeko 6 segundu baino gehiago ez dituztela behar. Horretarako tresna berezi bat prestatu dute. Tresna horrek hainbat webgune ezberdinetan probatzen ditu txartel baten zenbakien konbinazioak eta txarto (edo ondo) daudenak apuntatzen ditu. Probak webgune ezberdinetan egiten dituenez, VISA enpresak ez du ezer arrarorik somatzen (normalean txartelearen datuak sartzerakoan akats batzuk jarraian egiten badituzu webgune bakar batean bankuetxeak alertak jasotzen ditu). Diruenez MASTERCAD-eko txartelak eraso mota honi aurre egiteko prestatuta daude (erasoak ez du eraginik bertan). Bideo bat ere argitaratu dute, tresna nola erabiltzen den erakutsiz.
New Castle Unibertsitateko ikerlari talde batek demostratu du VISA txartelen datuak lortzeko 6 segundu baino gehiago ez dituztela behar. Horretarako tresna berezi bat prestatu dute. Tresna horrek hainbat webgune ezberdinetan probatzen ditu txartel baten zenbakien konbinazioak eta txarto (edo ondo) daudenak apuntatzen ditu. Probak webgune ezberdinetan egiten dituenez, VISA enpresak ez du ezer arrarorik somatzen (normalean txartelearen datuak sartzerakoan akats batzuk jarraian egiten badituzu webgune bakar batean bankuetxeak alertak jasotzen ditu). Diruenez MASTERCAD-eko txartelak eraso mota honi aurre egiteko prestatuta daude (erasoak ez du eraginik bertan). Bideo bat ere argitaratu dute, tresna nola erabiltzen den erakutsiz.