La locura del Level2 nos llegó a amargar. Aunque cuando la resolvimos nos llevamos una alegría del copón, todo hay que decirlo. Empezamos sin pistas y con una mala espina considerable al ver tantas URLs de YouTube a vídeos con frases de Arnold Schwarzenegger…con timestamps a frases concretas. No teníamos nada claro qué demonios había que hacer. La primera (mala) idea fue ir apuntando la palabra que oíamos en ese segundo exacto. Vimos que las URLs se reducían a 4 vídeos…pero con 189 timestamps.
Podéis ver lo que luchamos aquí:
https://docs.google.com/spreadsheets/d/1FcJSehUeCfPu7-DF-bVn1zpOntTm2PFkTCGMuhhx3dA/edit?usp=sharing
Como en todos los niveles, en este también tuvimos ayuda de la IA: en concreto Gemini Flash Pro 2.5 tiene soporte de transcripción de audios, con timestamps incluidos. Hace poco publiqué una extensión que hace uso de esta funcionalidad:
https://x.com/juanan/status/1947976791211282737
… pero bueno, perdonadme, me estoy desviando.
Aquí tengo que descubrirme ante el excelente trabajo de Andrea, Servida, Paul, Owen y Urtzi. Esta generación tiene un nivel técnico excelente. Hats off 🎩Consiguieron transcribir TODO lo que se dice en los timestamps de cada vídeo. La pista que publicó Ontza nos hizo ir al detalle.
Y aquí, en este fichero de texto, hay muuuuuchas horas de curro de Servida:
https://gist.github.com/juananpe/26c3a41b5d6b9b97e16cc94be6c1acf6#file-frasesvideosarnold-txt
OK. Pero… ¿y ahora qué? Pues ahora estuvimos horas intentando descifrar qué demonios querían decir esas frases. Os ahorraré nuestras locuras, pero llegamos a interpretar esas palabras cogidas de frases de Arnold en segundos exactos de distintos vídeos como declaración de variables, llamadas a funciones… Sí, una locura… Se la explicamos a Ontza e Immobilis que pasaban por los puestos de los jugadores cada X tiempo y literalmente se rieron a carcajada limpia de nuestras locuras. En ese momento no me sentó muy bien, la verdad 🤡pero tras finalizar el level… hasta yo mismo me reía de nuestro intento de interpretar como código esas frases…. Pero no porque no se pudiera, no, sino porque… YA EXISTïA UN F*CK*NG intérprete para ello. Exacto, lo que oyes, hay un maldito lenguaje de programación esotérico que permite programar en ArnoldC (lenguaje que interpreta frases de Arnold como si fueran programas, con su propio parser de ArnoldC a bytecode Java, que luego podemos ejecutar)
Ejemplo de «Hello world» en ArnoldC:
IT'S SHOWTIME
TALK TO THE HAND "hello world"
YOU HAVE BEEN TERMINATED
Hay gente para todo, amigos.
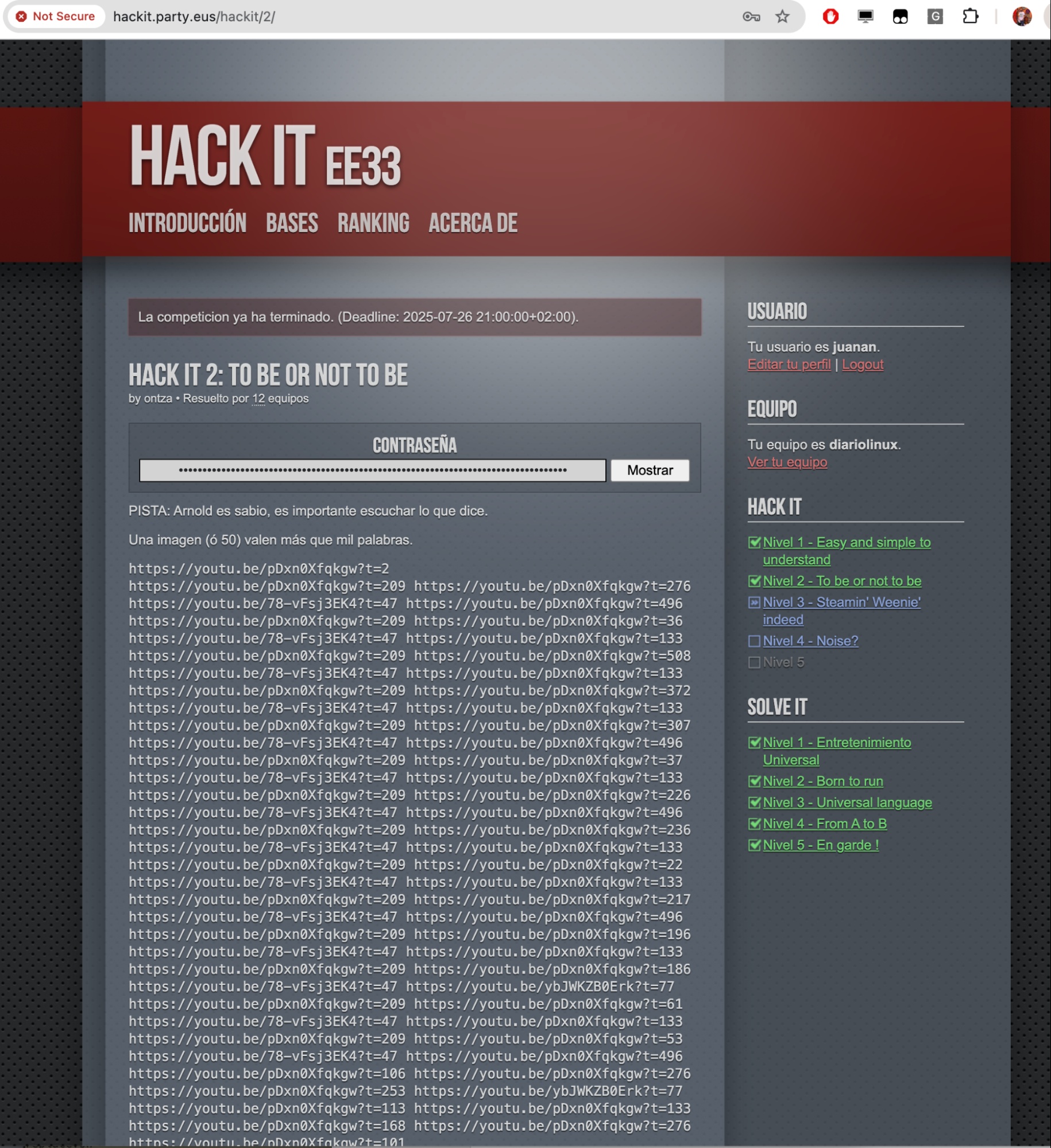
Hack It 2: To be or not to be (resuelto por 12 equipos).
La PISTA se publicó cuando llevábamos bastante tiempo de HackIt sin que ningún equipo consiguiera superarla: «Arnold es sabio, es importante escuchar lo que dice.»
Os podéis imaginar nuestra cara de panolis cuando nos enteramos de esto 🤡
En fin… Pero esto no acababa aquí, claro. Tuvimos que pasar por otro proceso de convertir las frases que habíamos transcrito a código ArnoldC válido:
https://gist.github.com/juananpe/26c3a41b5d6b9b97e16cc94be6c1acf6#file-instructions-arnoldc
Tras ello, para entenderlo, usando la especificación del lenguaje (decir «especificación» es ser muy generoso con esta 💩de documentación)
https://github.com/lhartikk/ArnoldC/wiki/ArnoldC
como base, decidimos convertir el código ArnoldC a Python.
Aquí, como curiosidad: Gemini Flash Pro 2.5 + Cursor en modo agente encontró que teníamos clonado el repo de Arnold, donde tienen el parser implementado en Scala:
https://github.com/lhartikk/ArnoldC/blob/master/src/main/scala/org/arnoldc/ArnoldParser.scala
Así que decidió por su cuenta que pasaba de la especificación y que iba a usar el parser como base para entender cómo traducir el programa a Python 🤯
Y lo hizo (alguna vuelta tuvimos que darle, pero básicamente lo hizo casi perfecto):
https://gist.github.com/juananpe/26c3a41b5d6b9b97e16cc94be6c1acf6#file-arnold-py
¡Y llegó la hora de la verdad!
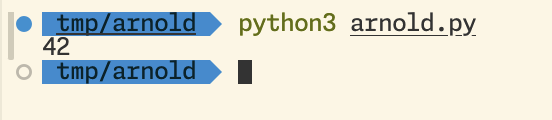
Oh shit… no puede ser… 42? seriously? Pero… no llevaba ayer el sr. Ontza una camiseta bien chula con ese 42 estampado?

Y sí, para los viejos del lugar:
What is the Answer to the Ultimate Question of Life, the Universe, and Everything?
42
«The Hitchhiker’s Guide to the Galaxy» (Douglas Adams)
Addendum
Me gustó el script sed de transformación de URLs+timestamp a frases de Arnold:
Muy old school: rápido, efectivo, sencillo.
Me gustó también la limpieza del script decodificado en pseudo código que se curró Jon de Navarparty.
Kudos to Jon, Mattin, tatai and all the Navarparty crew.
Hay intérpretes online para arnoldC.




{kind=link}
{kind=link}
{kind=link}