 Esta semana he necesitado instalar una máquina virtual de VirtualBox en un servidor Scaleway (de 2.9€/mes) sin entorno gráfico. La primera duda ha sido… ¿se puede? 🙂 Lo primero que necesitamos es instalar VirtualBox. La particularidad es que Scaleway no tiene un kernel vanilla sino que está bastante personalizado para adaptarlo a esta empresa de cloud hosting. Así que hay que descargar el código del kernel, ajustar su configuración a la misma que usa Scaleway, compilar los módulos necesarios y ahora sí, descargar e instalar VirtualBox. Gracias a $DEITY, alguien se ha pegado el curro de preparar un script al efecto. La última parte de ese script instalar una máquina virtual Windows en VirtualBox (yo no lo necesito, he comentado esas líneas).
Esta semana he necesitado instalar una máquina virtual de VirtualBox en un servidor Scaleway (de 2.9€/mes) sin entorno gráfico. La primera duda ha sido… ¿se puede? 🙂 Lo primero que necesitamos es instalar VirtualBox. La particularidad es que Scaleway no tiene un kernel vanilla sino que está bastante personalizado para adaptarlo a esta empresa de cloud hosting. Así que hay que descargar el código del kernel, ajustar su configuración a la misma que usa Scaleway, compilar los módulos necesarios y ahora sí, descargar e instalar VirtualBox. Gracias a $DEITY, alguien se ha pegado el curro de preparar un script al efecto. La última parte de ese script instalar una máquina virtual Windows en VirtualBox (yo no lo necesito, he comentado esas líneas).
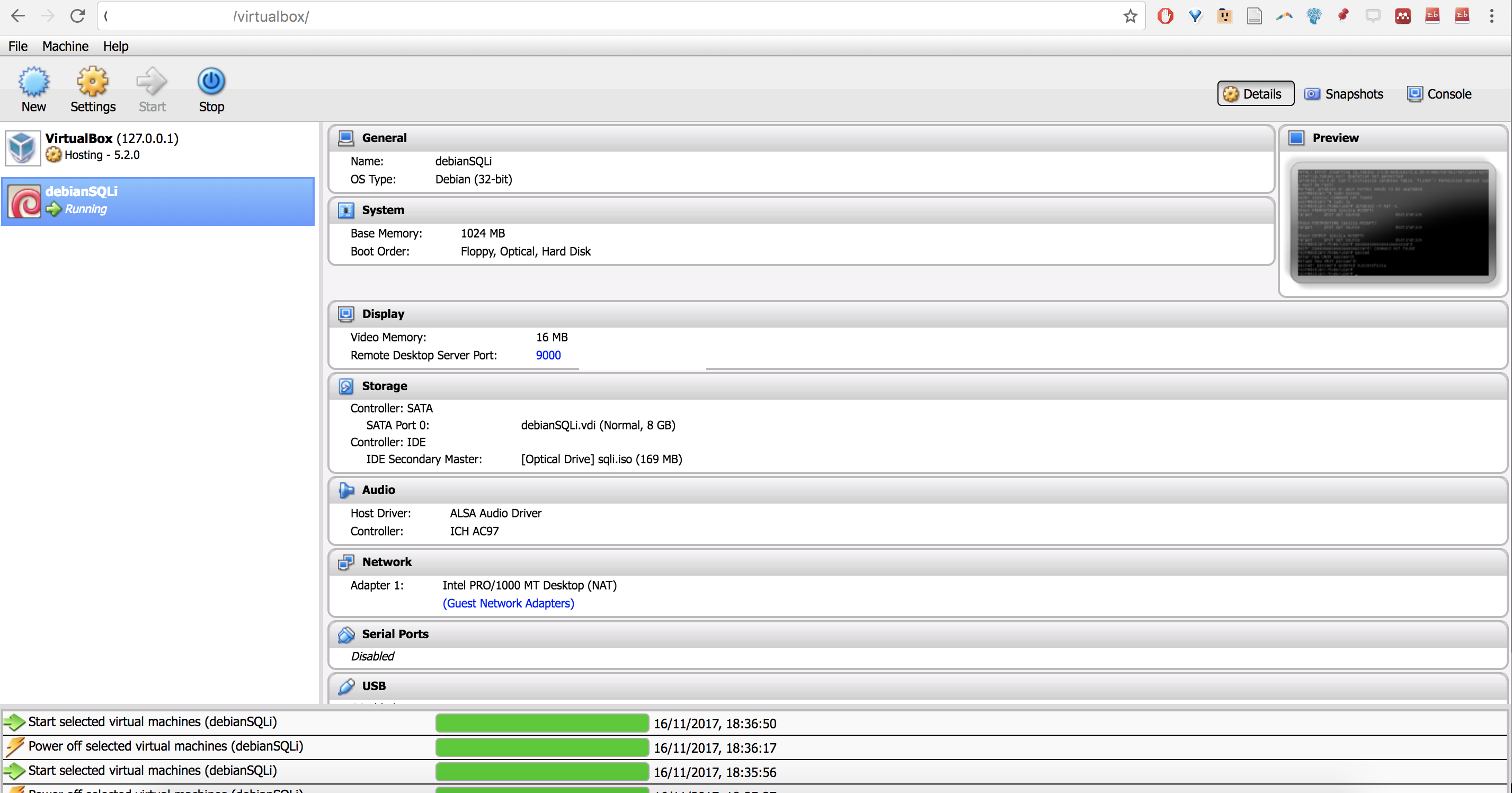
Bien, ya tenemos el kernel preparado y VirtualBox instalado. Ahora, ¿cómo demonios instalo una máquina virtual a partir de una imagen .iso si no tengo entorno gráfico? Bueno, simulando el entorno gráfico a través de phpVirtualBox (sí, existe tal engendro y funciona de lujo). Además, este tutorial te explica cómo instalarlo paso a paso.
Finalmente, si quieres acceder a la consola que VirtualBox abre por defecto cuando lanzas una máquina virtual Linux, podrás hacerlo vía RDP (Remote Desktop Protocol). Tampoco sabía que una VBoxHeadless abría el puerto 9000 para acceso RDP. Desde tu host remoto puedes ver la consola de VirtualBox vía rdesktop (en Linux) o vía Microsoft Remote Desktop en OSX.
También es posible usar la línea de comandos para lanzar la máquina virtualbox desde una shell en Scaleway (sin necesidad de usar phpVirtualBox, pero es mucho menos intuitivo)