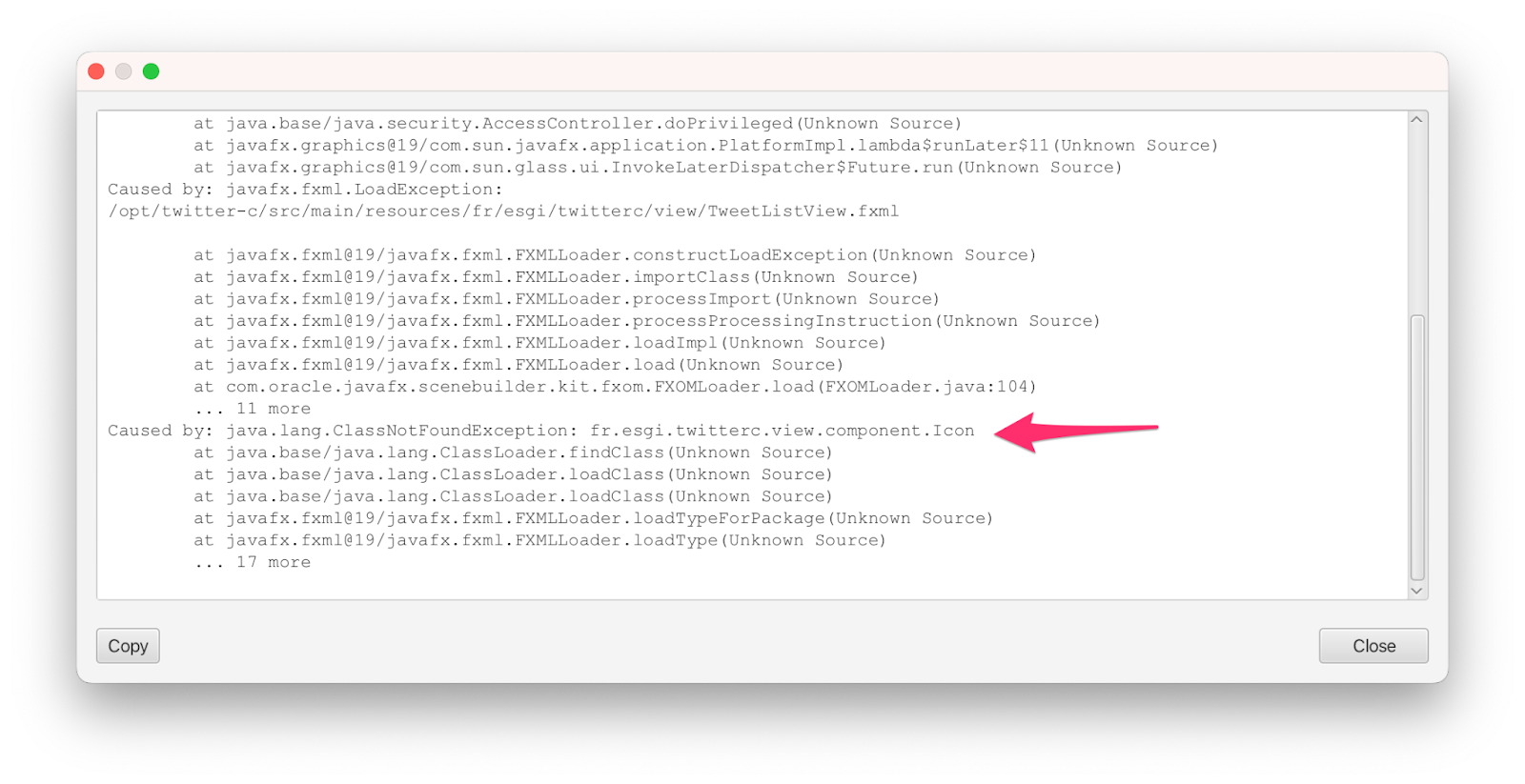
Pipelines es la nueva creación del equipo de Open WebUI, encabezado por @timothyjbaek (https://github.com/tjbck) y @justinh-rahb (https://github.com/justinh-rahb)
Pipelines se define como a UI-Agnostic OpenAI API Plugin Framework. En resumidas cuentas permite inyectar plugins que interceptan el prompt del usuario antes de enviarlo al LLM final, lo procesan y se lo envían, ya procesado, al LLM. ¿Y para qué puede servir esto? Por ejemplo para ejecutar funciones en base a lo que requiera un prompt antes de enviarlo al LLM (ejemplo sencillo: ¿qué hora es? ¿qué tiempo hace ahora en Donostia?…), para consultar bases de datos externas e inyectar las respuestas como contexto del prompt (RAG), para ejecutar código…
Pipelines es agnóstico del cliente UI, basta con que éste cliente soporte el API de OpenAI. Al ser una creación del equipo de OpenWebUI el primer UI que soporta Pipelines es, por supuest, OpenWebUI.
Hay dos tipos de pipelines: filtros y pipes.
Filtros: da igual el modelo que elijas (aunque se puede determinar para qué modelos quieres aplicarlo, por defecto es para todos), el prompt del usuario – Form Data – pasará por el filtro (entrando por una función de inlet), si es necesario se procesará y saldrá por el filtro ya procesado (outlet). Podría ser que no fuera necesario ser procesado, en tal caso, el modelo responderá como siempre.

Pipes: el usuario debe elegir el pipe que quiere aplicar a su prompt – Form Data. Este pasará por el pipe y será devuelto como respuesta (contexto) que luego podrá ser usado para otras preguntas. Por ejemplo, podemos seleccionar Wikipedia como un pipe, pedirle que inyecte los primeros párrafos de una entrada de wikipedia en el contexto y luego seguir preguntando.

Veamos cómo ponerlo en marcha Pipelines con OpenWebUI 0.2.2.
Probando Pipelines
Asumiré que ya tienes OpenWebUI 0.2.2 lanzado y lo único que necesitas es saber cómo lanzar y usar Pipelines. Lo más sencillo será hacerlo vía Docker. Lanzamos Pipelines así:
$ docker run -p 9099:9099 --add-host=host.docker.internal:host-gateway -v pipelines:/app/pipelines --name pipelines --restart always ghcr.io/open-webui/pipelines:main
Podemos ver los logs que nos vaya dejando con este comando:
$ docker logs -f pipelines
Uniendo OpenWebUI con Pipelines
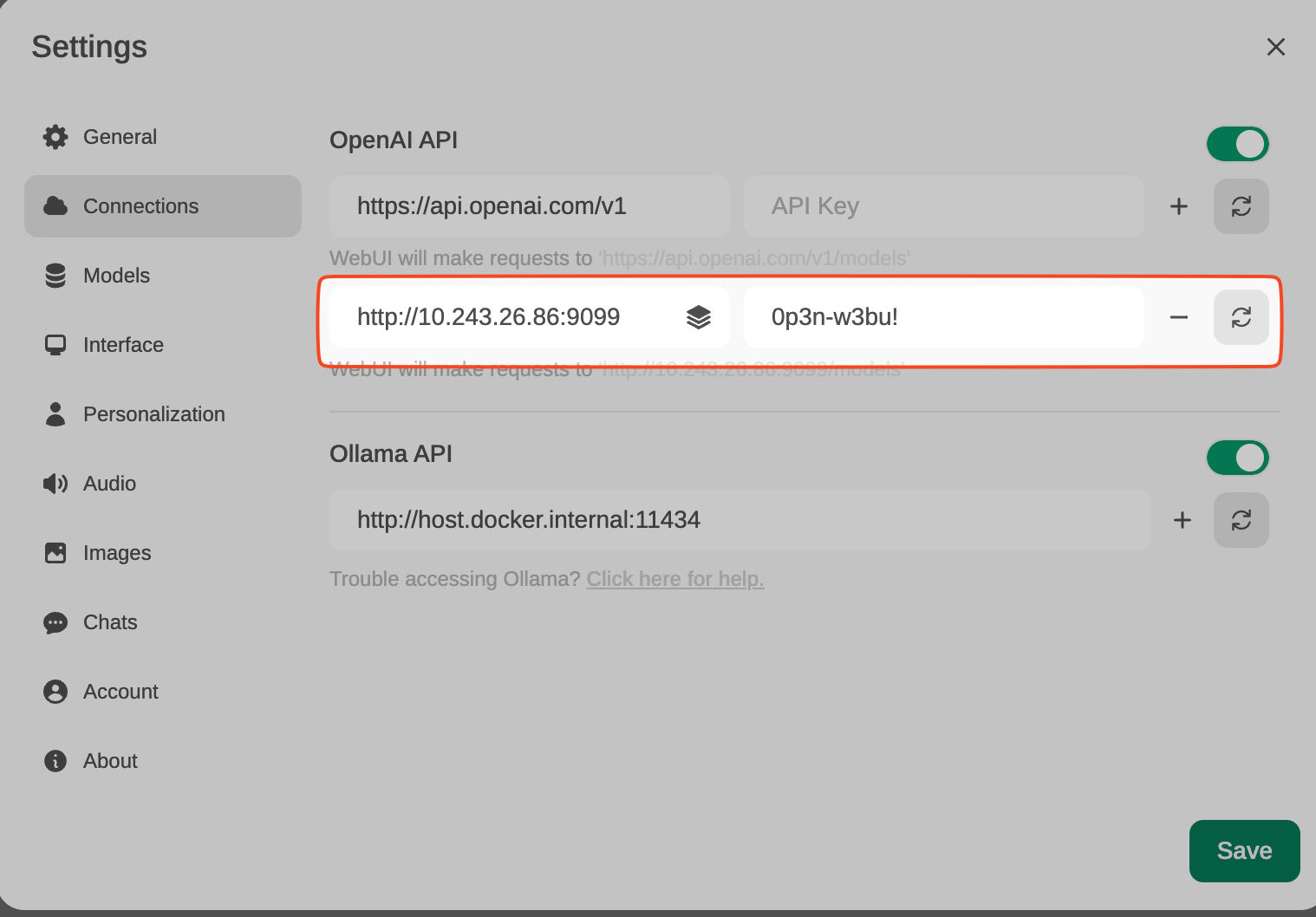
Desde Settings, creamos y guardamos una nueva conexión tipo OpenAI API, con estos datos:
URL: http://TU_DIRECCION_IP:9099 (el docker anterior se ha lanzado aquí). Pass: 0p3n-w3bu!
Cómo añadir un Function Calling Pipeline
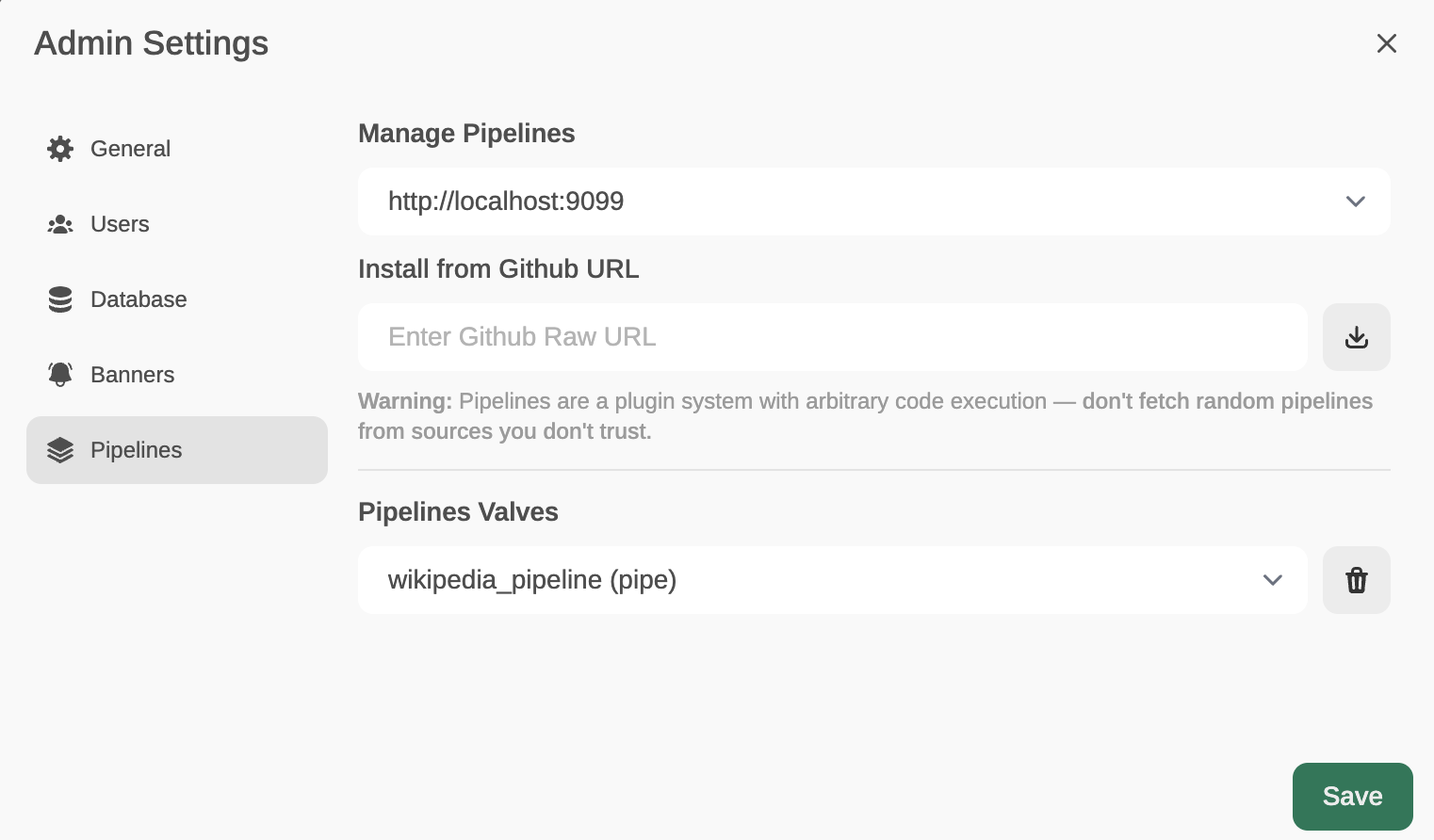
Ahora, desde Admin Settings / Pipelines, añadiremos nuestro primer filtro: Function Calling.Lo haremos indicando que Pipelines está a la escucha en http://localhost:9099 (donde lo hemos configurado antes) y que queremos instalar el siguiente filtro de Function Calling desde GitHub: https://github.com/open-webui/pipelines/blob/main/examples/function_calling/function_calling_filter_pipeline.py
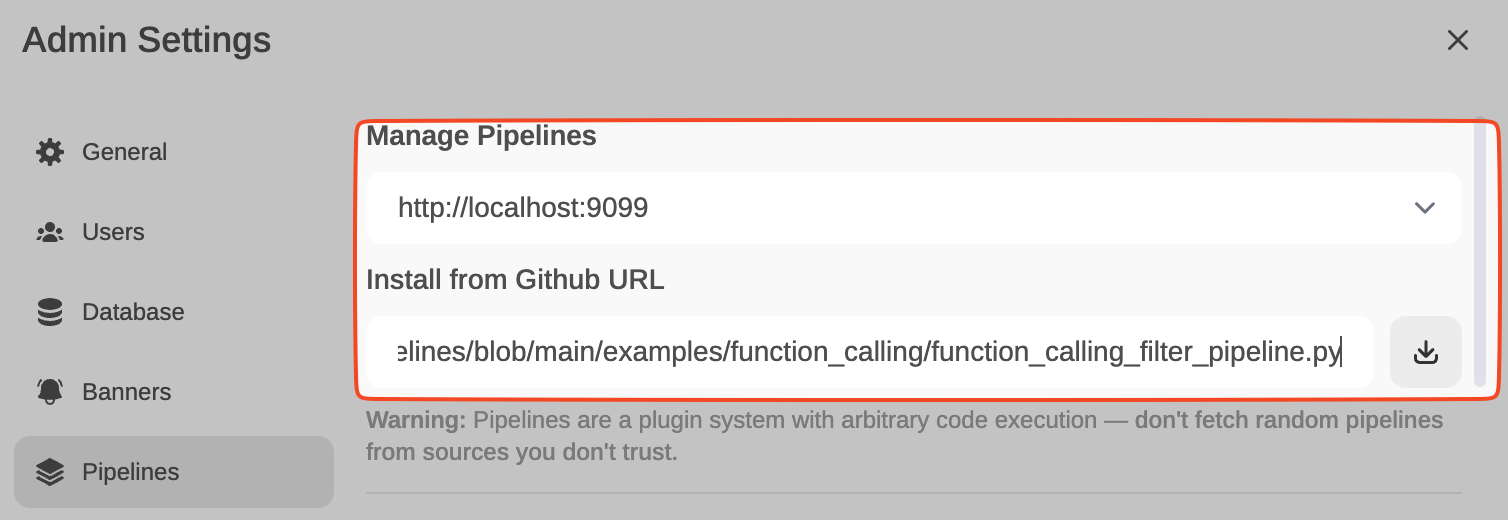
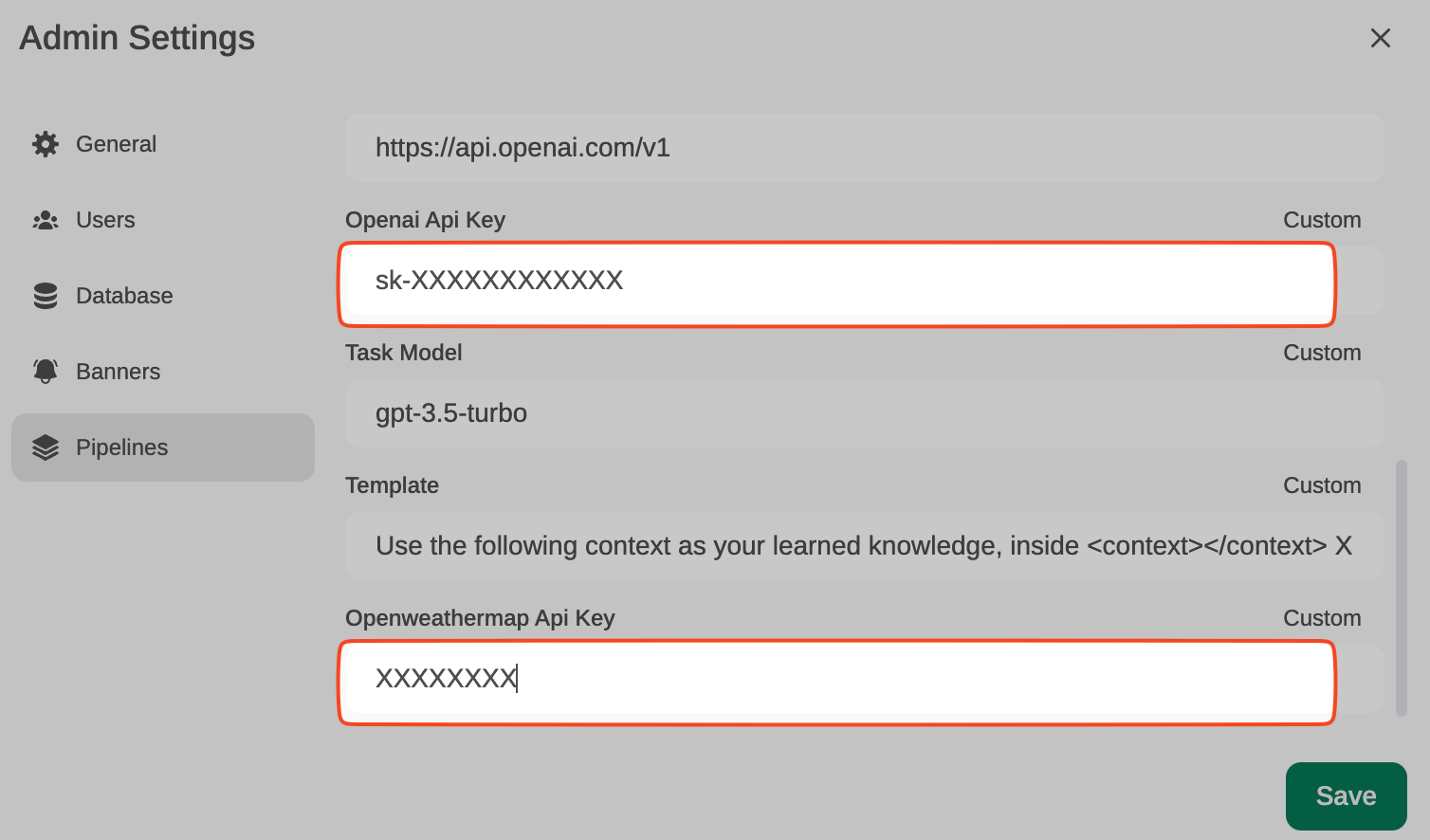
Podemos especificar a qué modelos afecta el pipeline (por defecto, a todos *), la prioridad (es posible encadenar pipes, el que tenga un número menor será el más prioritario) y en este caso, también el OpenAI API Base URL, su key y el modelo. Por ejemplo, GPT-3.5-Turbo. Este LLM será usado para decidir si el prompt del usuario necesita ser respondido a través de una función o no, y en caso afirmativo, el modelo decidirá qué función usar (algo com function calling, pero a través de prompts-respuestas con GPT-3.5 normales, internamente he visto que no usa function calling).
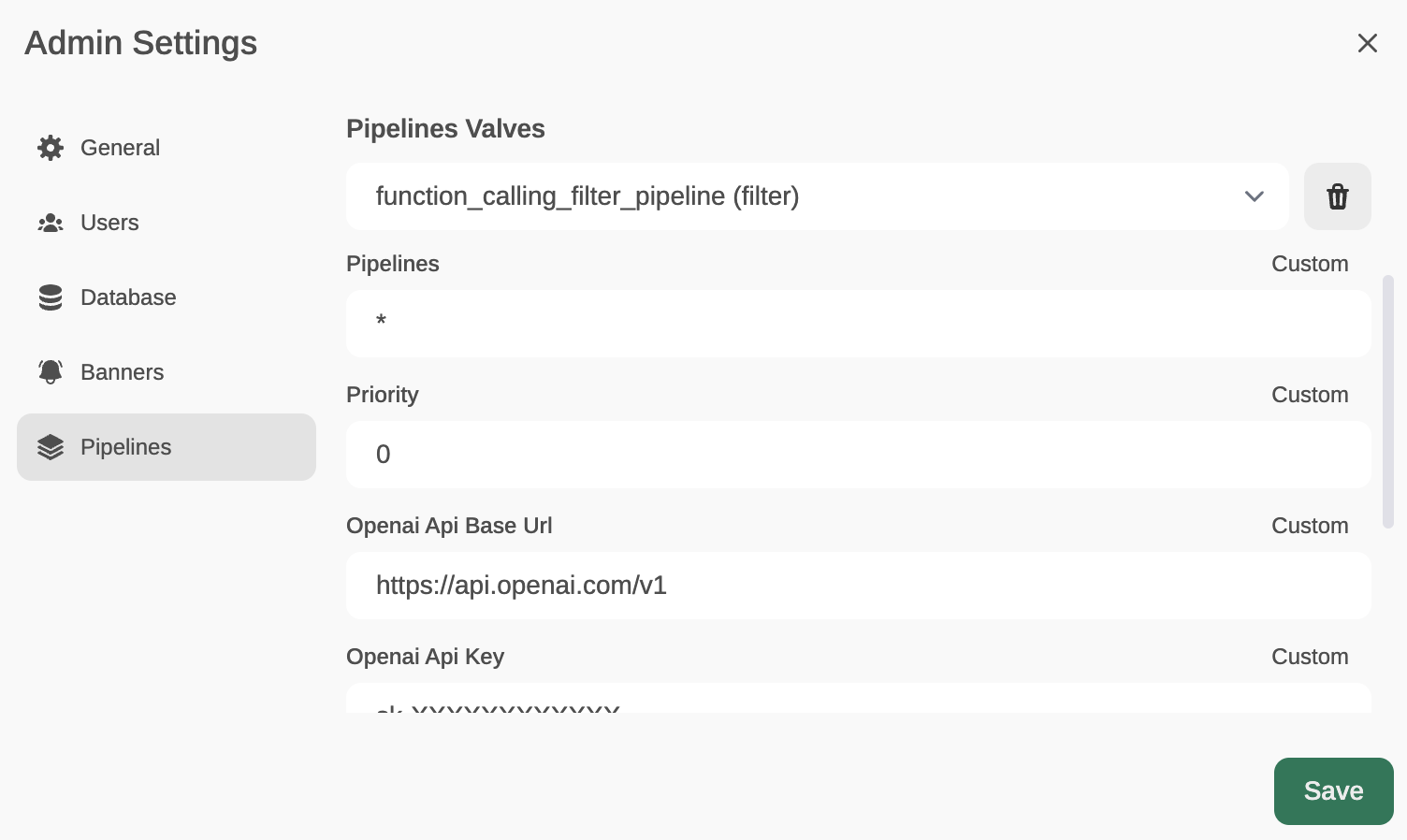
En el template se puede especificar el prompt que recibirá GPT 3.5-Turbo para decidir si es necesario ejecutar una función (y cuál) o deja pasar el prompt sin necesidad de ejecutar ninguna función (en cuyo caso respondería con el nombre de función vacío)
El último parámetro, OpenWeatherMap API Key servirá para responder (si es necesario) al prompt del usuario que esté solicitando conocer el tiempo que hace en una localidad.
Vamos a probarlo. Elegimos un modelo en OpenWebUI (en mi caso, mistral:latest) y preguntamos por la hora actual (lo hice ayer a la noche 🙂
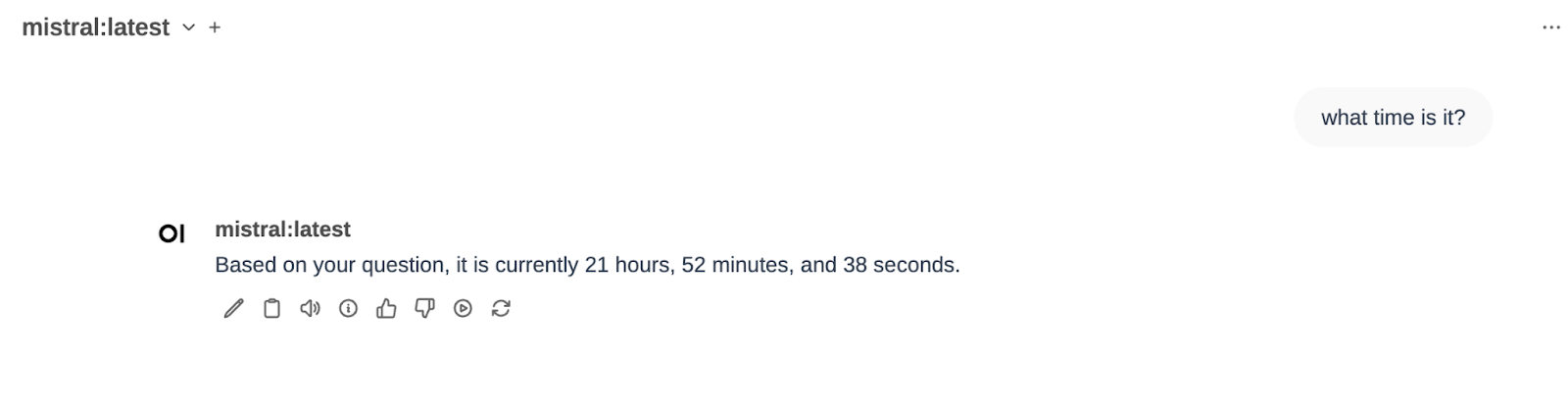
¡Funciona!
En el mismo filtro de Function Calling tenemos también definidas otras dos tools, Weather y Calculator. Probemos la de weather…
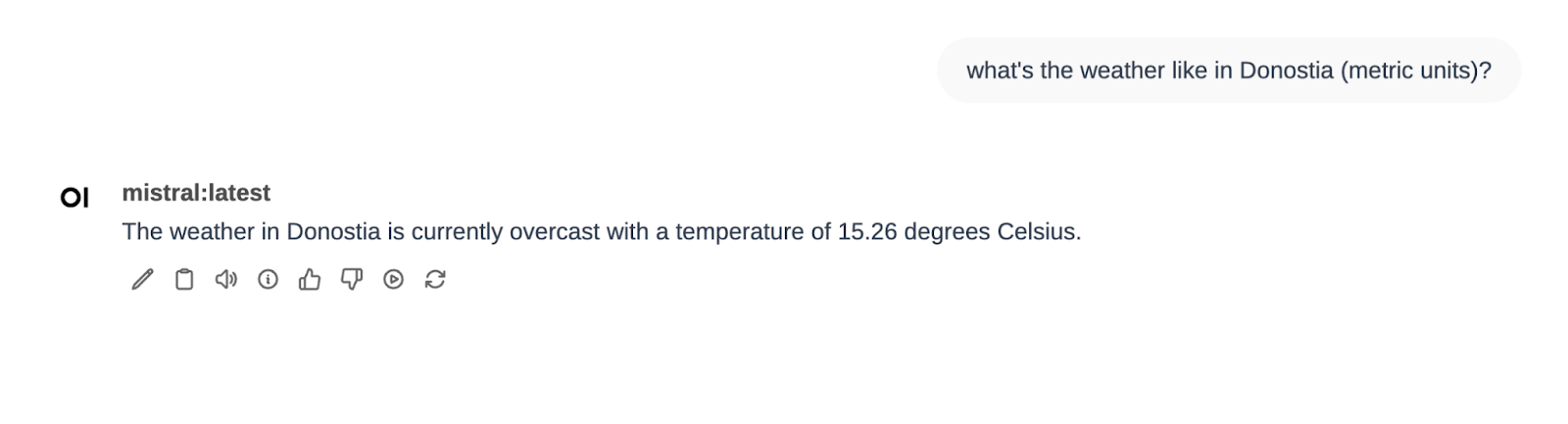
Perfecto 🙂
Añadiendo un Pipe: Wikipedia Pipe
Tal y como hemos comentado, también se pueden usar Pipes en lugar de Filters. Un ejemplo sería el uso de Wikipedia.
Igual que antes, desde los settings de Admin, añadimos este pipeline: https://github.com/open-webui/pipelines/blob/main/examples/pipelines/integrations/wikipedia_pipeline.py
Veremos ahora que tenemos un nuevo modelo disponible en OpenWebUI:
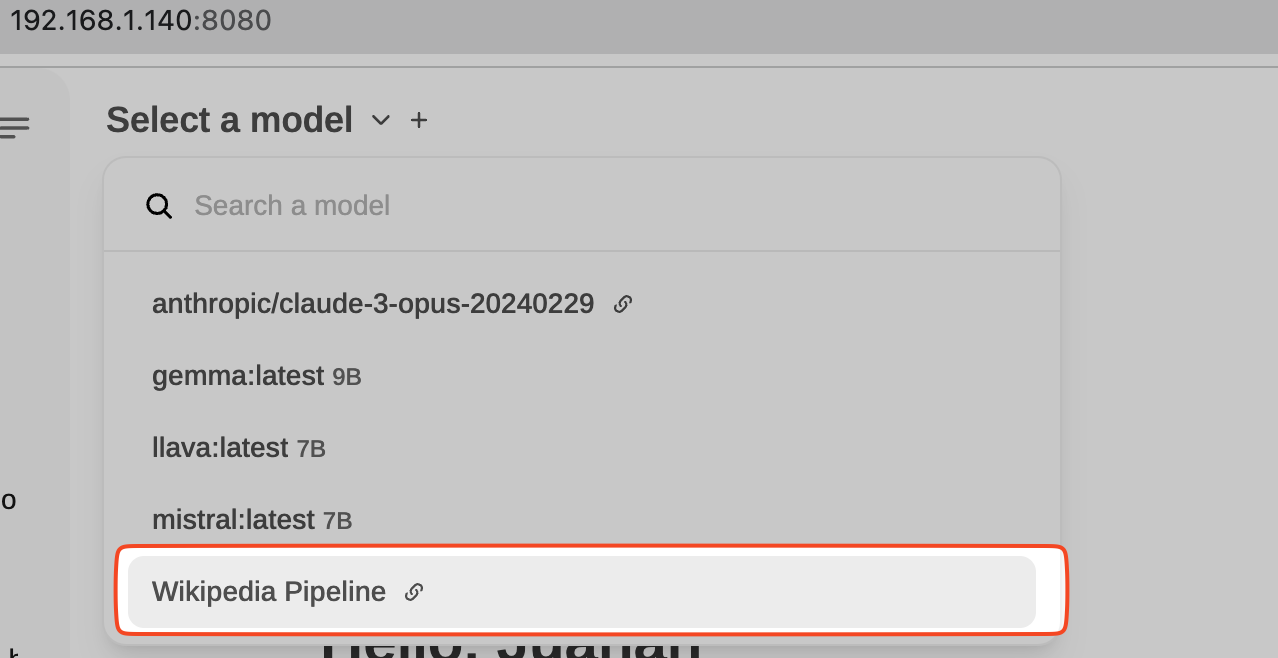
Vamos a probarlo. Seleccionamos el modelo Wikipedia Pipeline y buscamos ‘Mistral AI’:
¡Funciona!
Y una última prueba con todo a la vez:
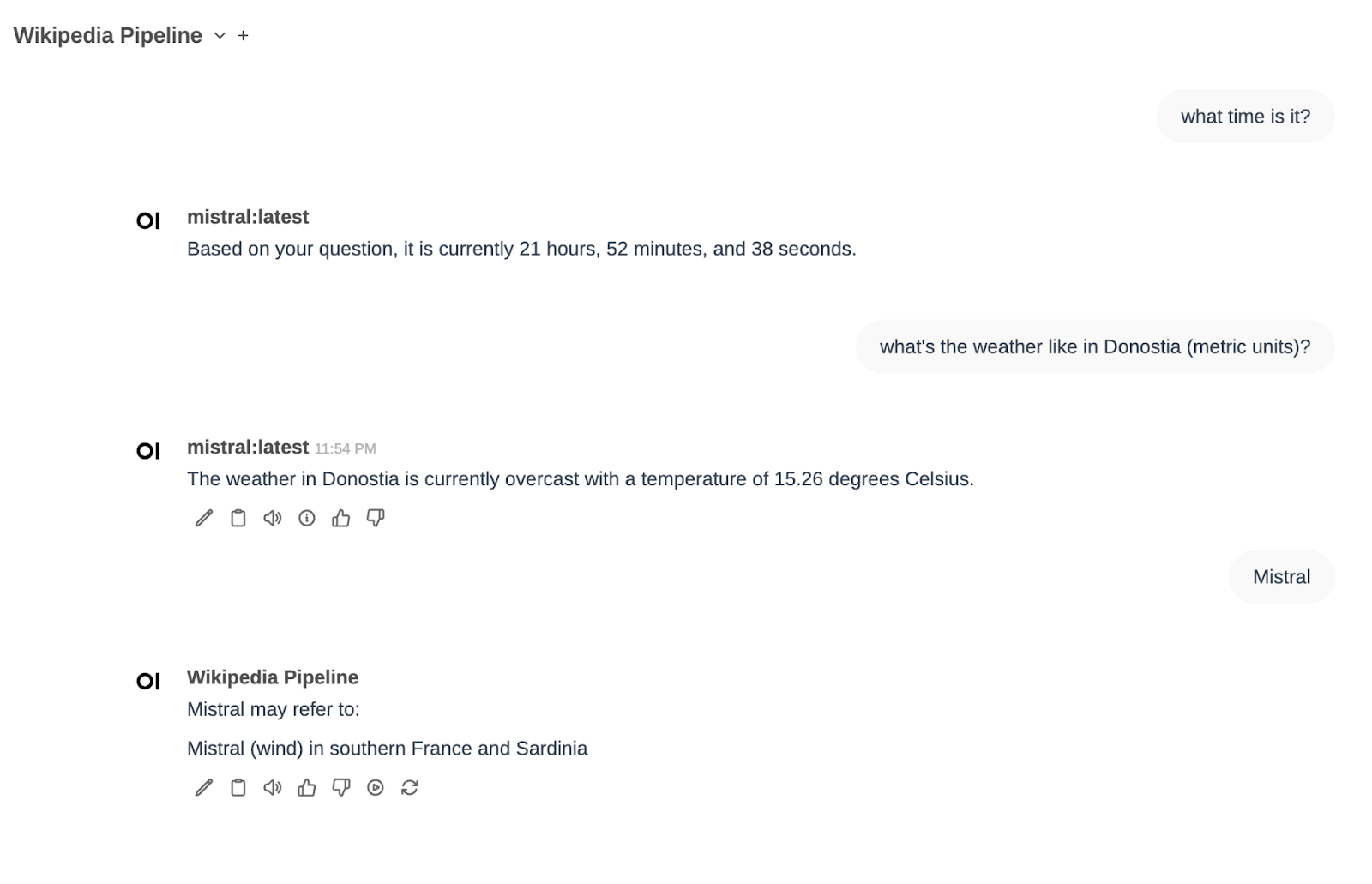
He elegido mistral como modelo, y he preguntado por la hora («What time is it»). El pipeline de function calling ha determinado que es algo que se puede responder ejecutando la función de obtener la hora del sistema y me ha devuleto la hora actual.
Después he pedido el tiempo en Donostia y me ha dicho la temperatura. Finalmente he seleccionado el Pipe de Wikipedia y he preguntado por Mistral. Ahí he visto que no he sido lo suficientemente explícito (Mistral puede ser varias cosas…)
En un segundo intento, he solicitado información sobre Mistral AI. En esta ocasión he encontrado la información que quería, como hemos visto antes.