I had been thinking for a while that I would take advantage of Christmas to install Kodi on my LG TV (webOS). So yesterday I got to work on it.
The installation is straightforward by following this mini-tutorial: https://kodi.wiki/view/HOW-TO:Install_Kodi_for_webOS. The problem arose when trying to install the IPTV Simple Client. This client has several dependencies, including inputstream.ffmpegdirect and inputstream.rtmp, which are not available in the Kodi repository for LG. It is necessary to download and install the pre-compiled binaries.
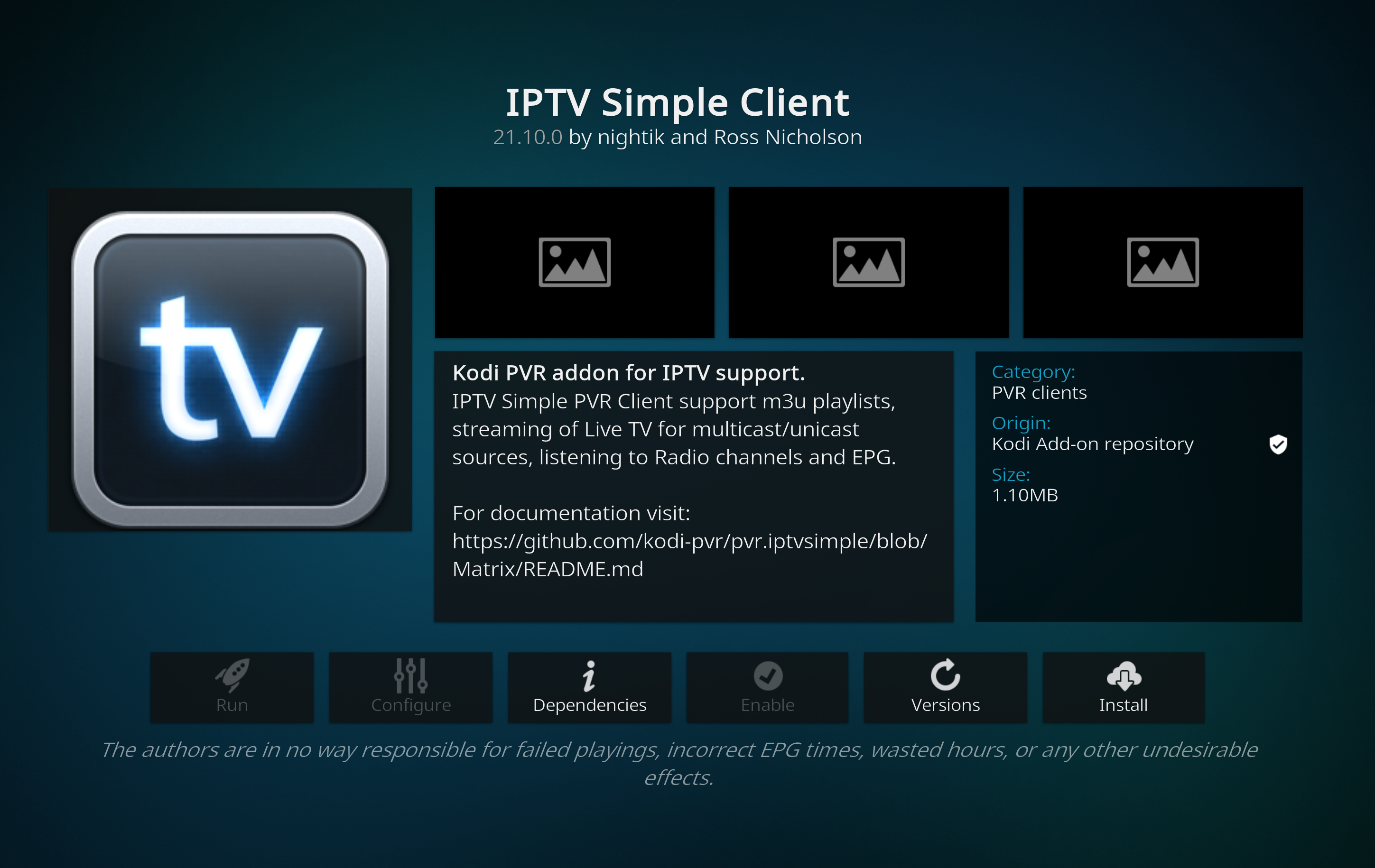
Reboot Kodi. Accept the messages that Kodi will display indicating that it has discovered two new add-ons. Open the settings of IPTV Simple Client.
When this add-on is enabled, it displays all channels it can make available from the M3U file you specified during the configuration step, under the menu option ‘PVR & Live TV’ (you can’t «run» the add-on like you do with the others). Since it starts automatically when Kodi starts, there is no ‘run’ option. When the add-on is configured with a working channel list (*.m3u), it will scan that list and display all available channels in the main window.
Bonus: TIL: you can use CanI.RootMy.TV to find an exploit for your TV.
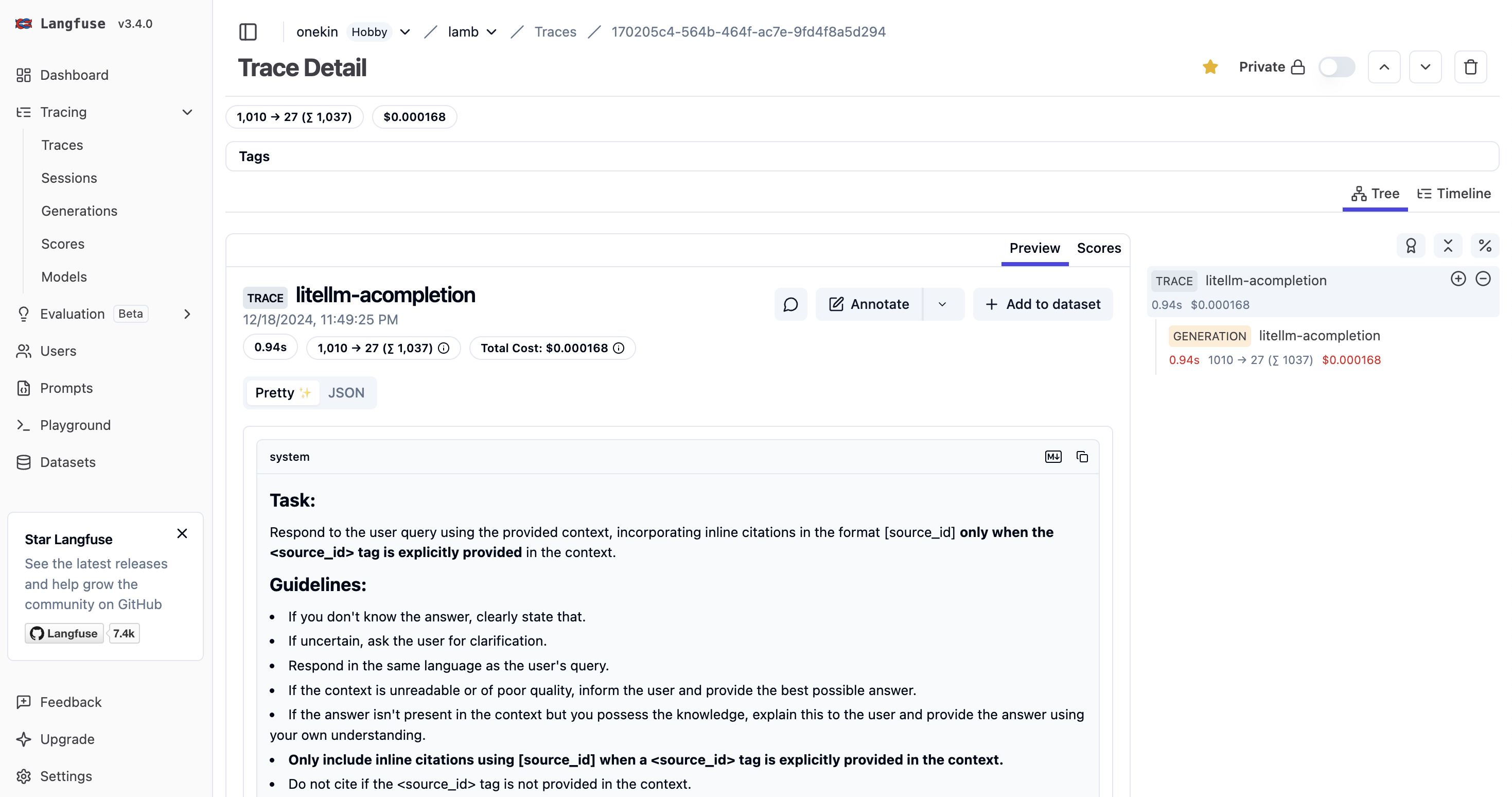
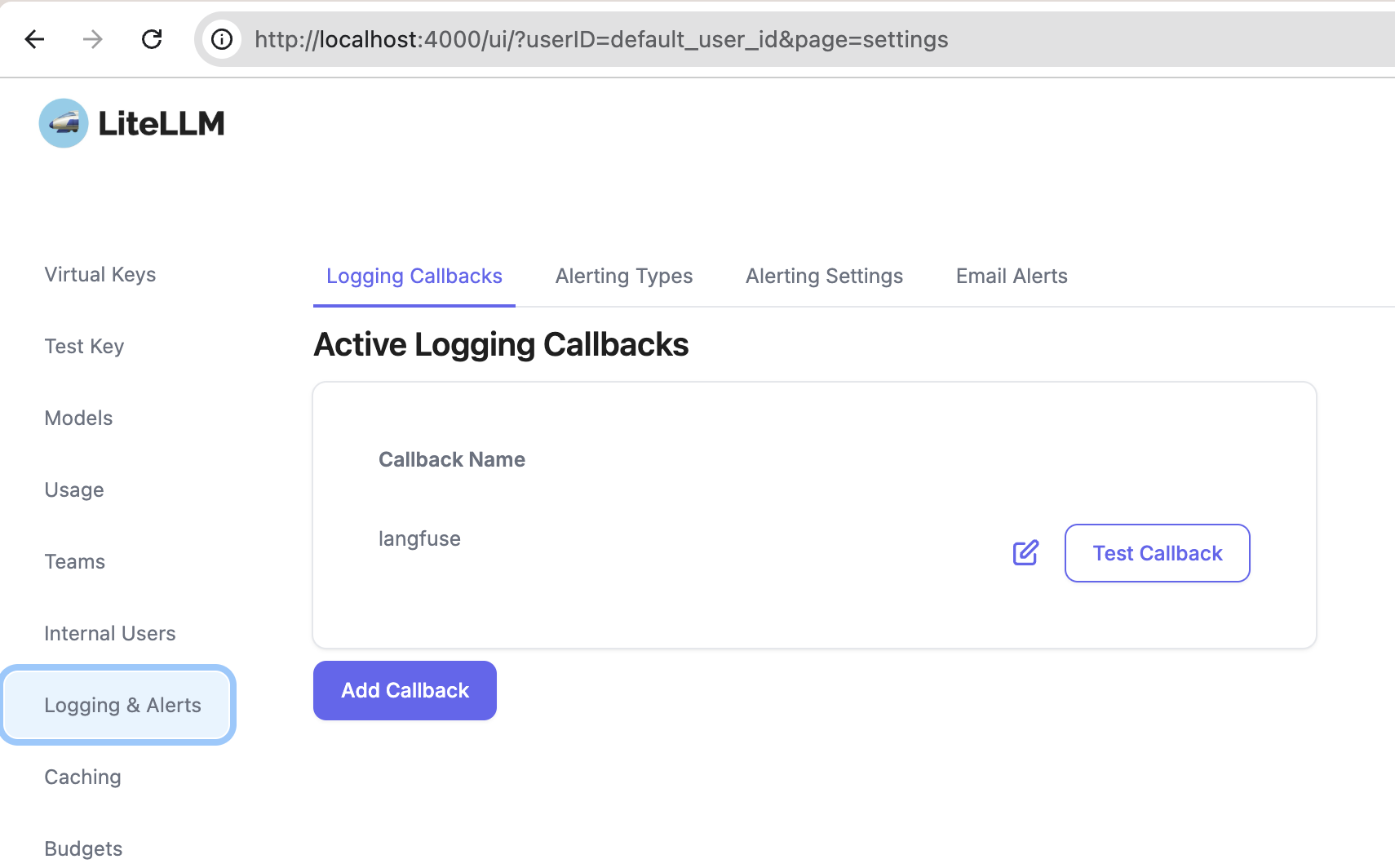
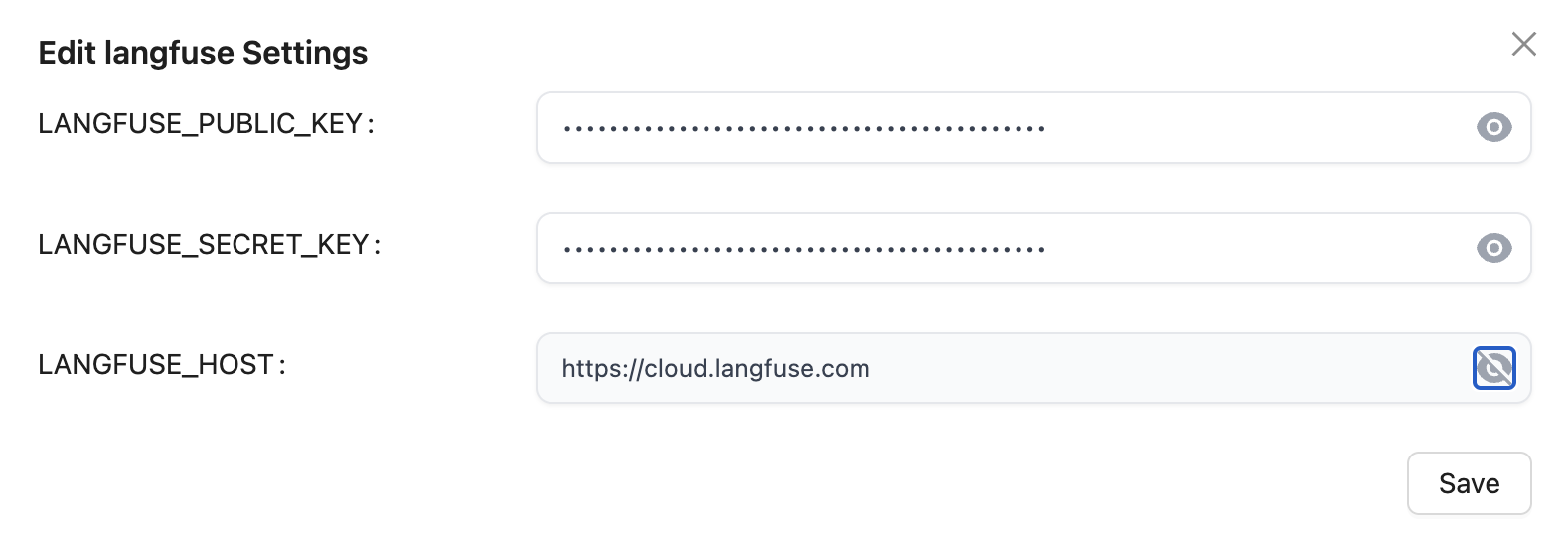
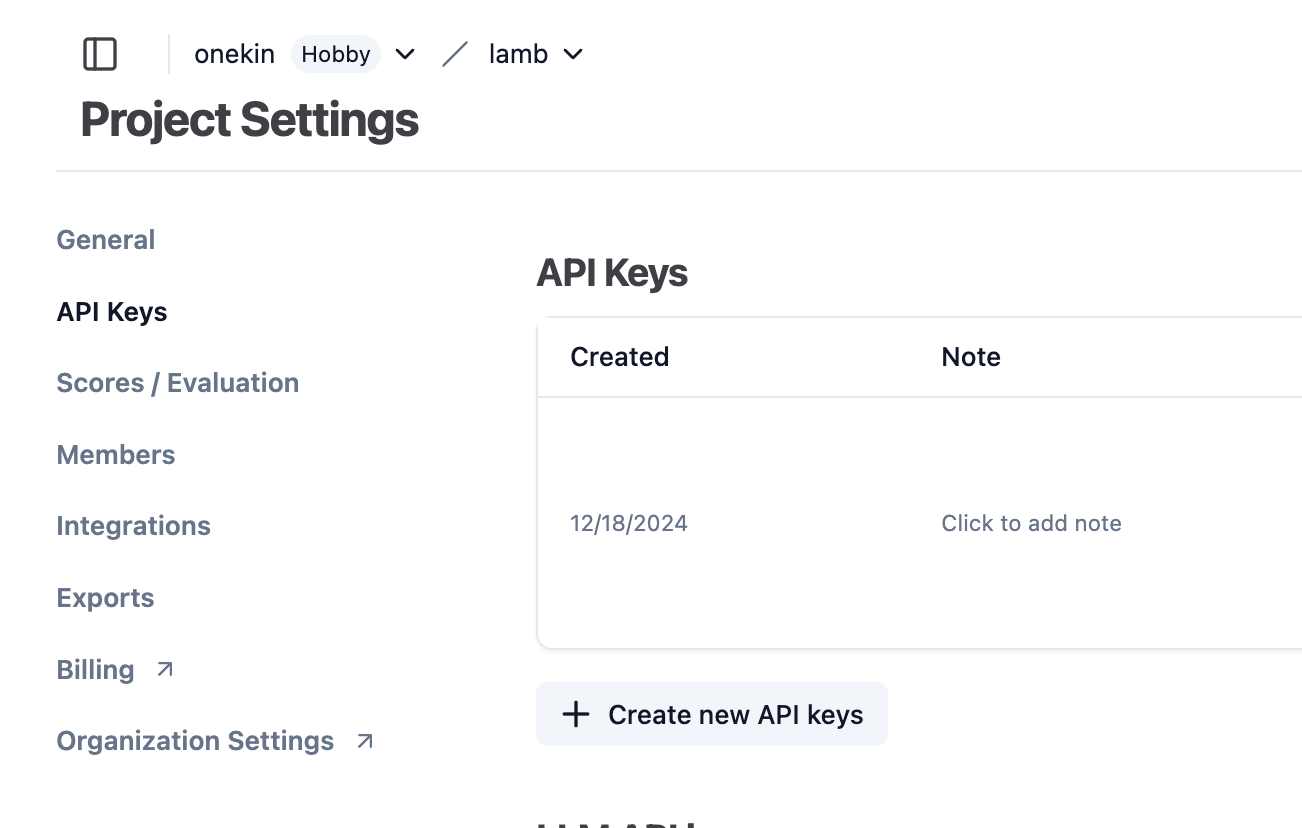
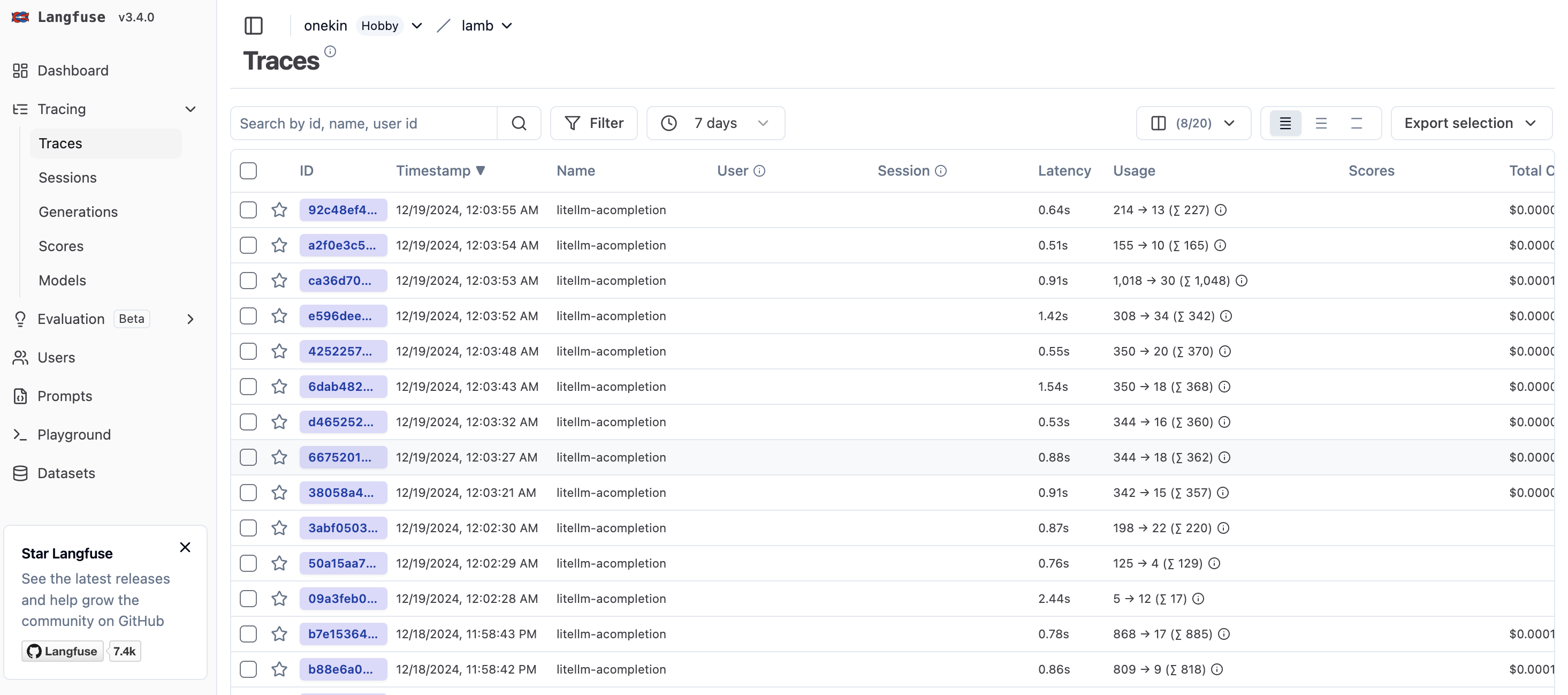
Contexto: has implementado o estás usando una aplicación web que internamente hace llamadas vía API a un LLM (GPT, Claude, LLama, whatever). Quieres analizar cuáles son los prompts que dicha aplicación está enviando. Necesitarás litellm (para que haga de proxy entre tu aplicación y el LLM) y langfuse, que recibirá un callback y te mostrará gráficamente todos los prompts. La idea es que litellm enviará automáticamente a langfuse una copia de cada lllamada al LLM (y de su respuesta) para que luego las puedas visualizar cómodamente.
(cambia el password dbpassword9090 como quieras). Postgresql es necesario para que litellm guarde información de los modelos. Necesitarás también crear un schema para postgresql a través de Prisma.
Copia el fichero schema.prisma del repositorio GitHub de litellm:
llm es una utilidad imprescindible en tu arsenal de comandos. Permite acceder desde la terminal a cualquier LLM, integrándose como un comando Unix más.
groq es una empresa que ofrece acceso a llama3 a través de su API, ejecutándose en sus veloces LPUs, de forma gratuita. Uno de los modelos más potentes que ofrece es llama-3-3-70b
Para poder usar llama3.3-70b desde el comando llm a través de groq, es necesario instalar el plugin llm-groq, por el momento a través del HEAD en su repo GitHub
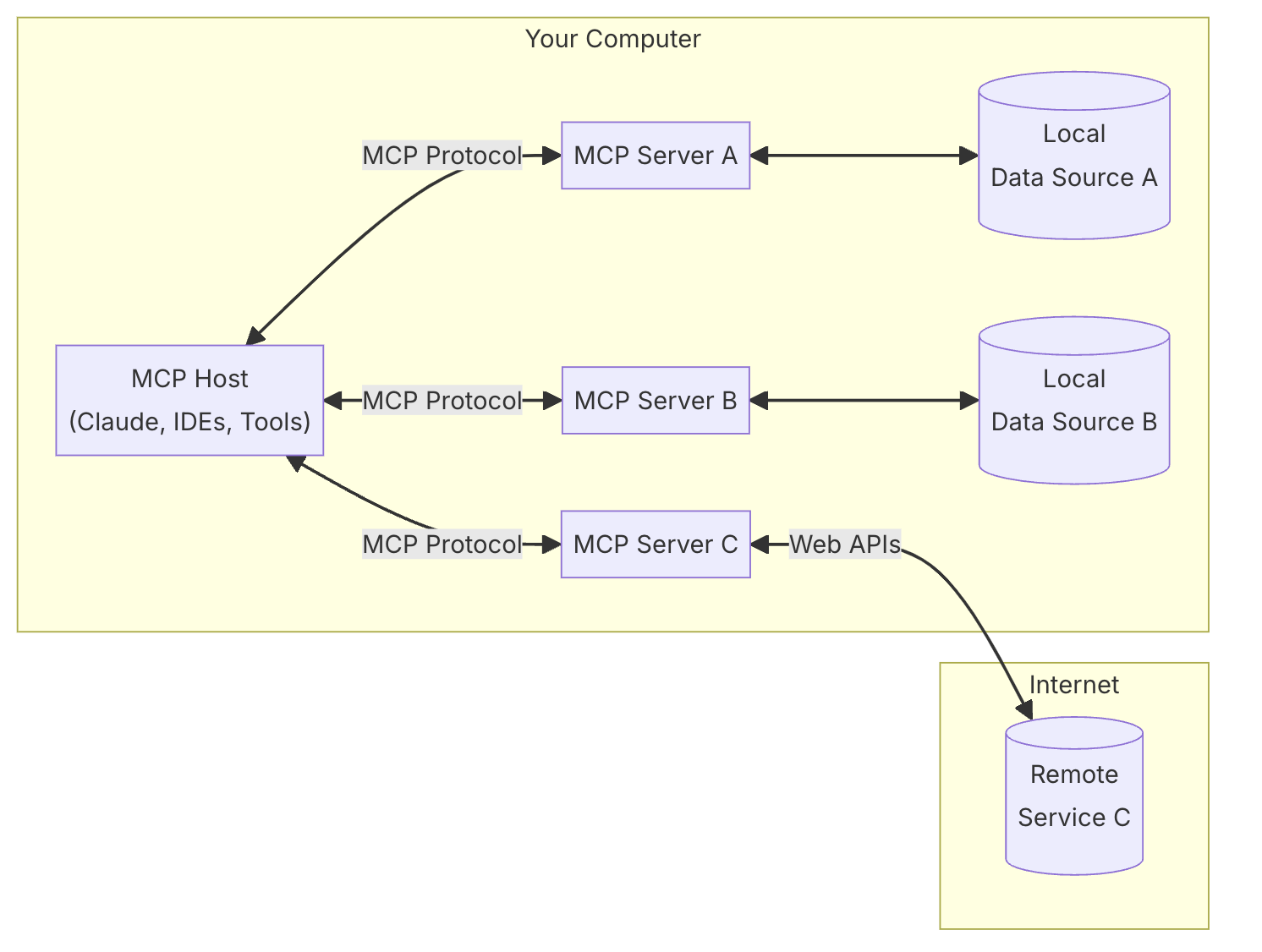
El Model Context Protocol (MCP) es un estándar abierto, ideado por Anthropic, que busca hacer más sencillo y práctico conectar tus aplicaciones con los LLM. Imagina que tienes un asistente inteligente y quieres que pueda hablar con todas las herramientas y bases de datos que usas sin volverte loco configurando cada cosa; eso es lo que MCP hace por ti.
En la siguiente figura vemos que podemos tener distintos servicios MCP (ofreciendo por ejemplo conexión con una base de datos sqlite, con el sistema de archivos, con GitHub, etc.) y un cliente (host) que hace uso de dichos servicios (por ejemplo, Claude, a través de Claude Desktop, por ahora uno de los pocos clientes compatibles). Durante la preview, los servicios MCP deben estar ejecutándose en local, aunque Anthropic está trabajando para que en breve podamos usar servicios MCP remotos.
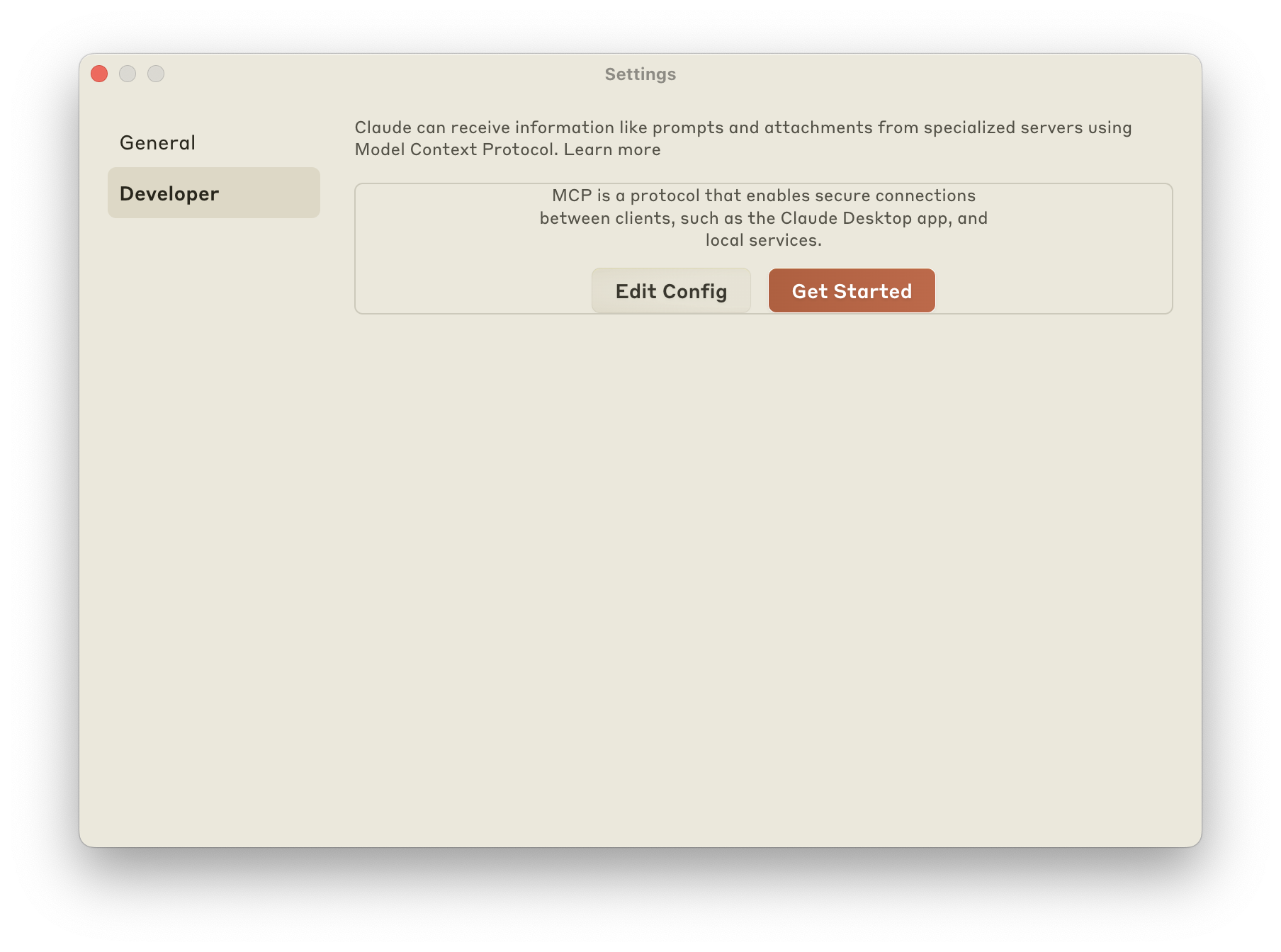
Veamos cómo configurar Claude Desktop (un cliente MCP) para que sepa hablar con una base de datos Sqlite.
Lo primero, desde Claude / Settings / Developer, pulsa en «Edit Config»
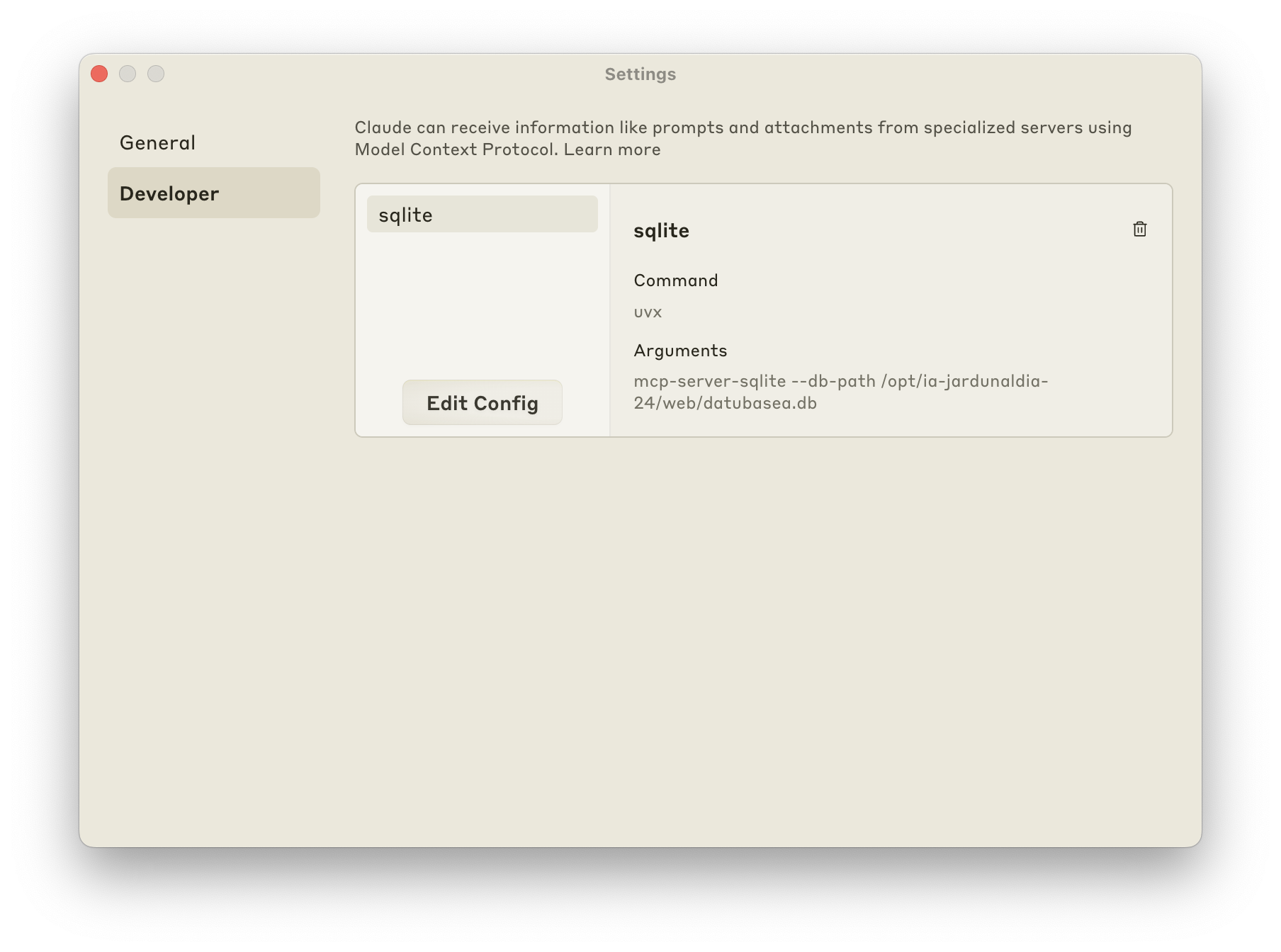
Cierra Claude Desktop y vuélvelo a abrir. Entra de nuevo en Settings / Developer. Deberías ver lo siguiente:
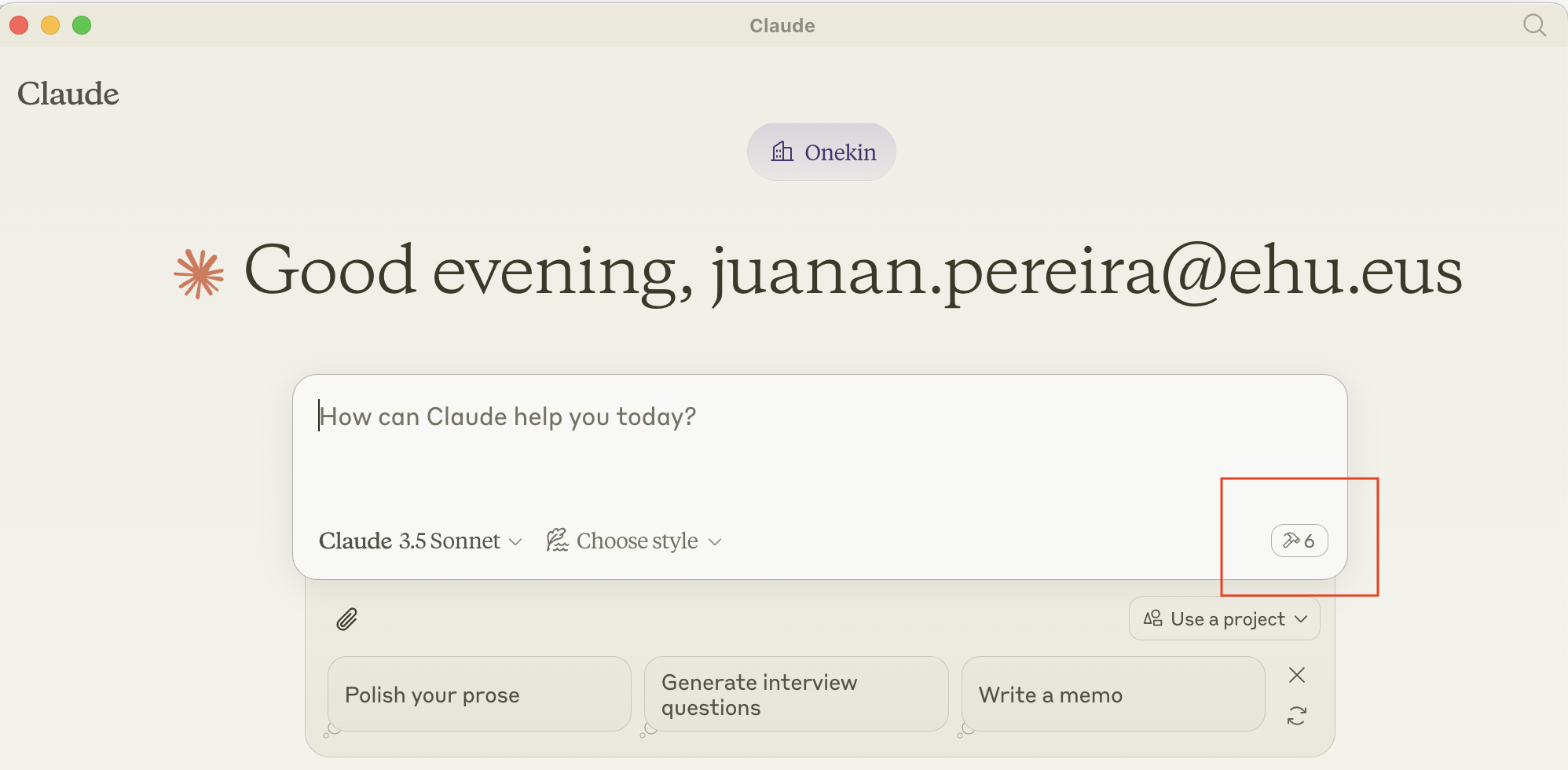
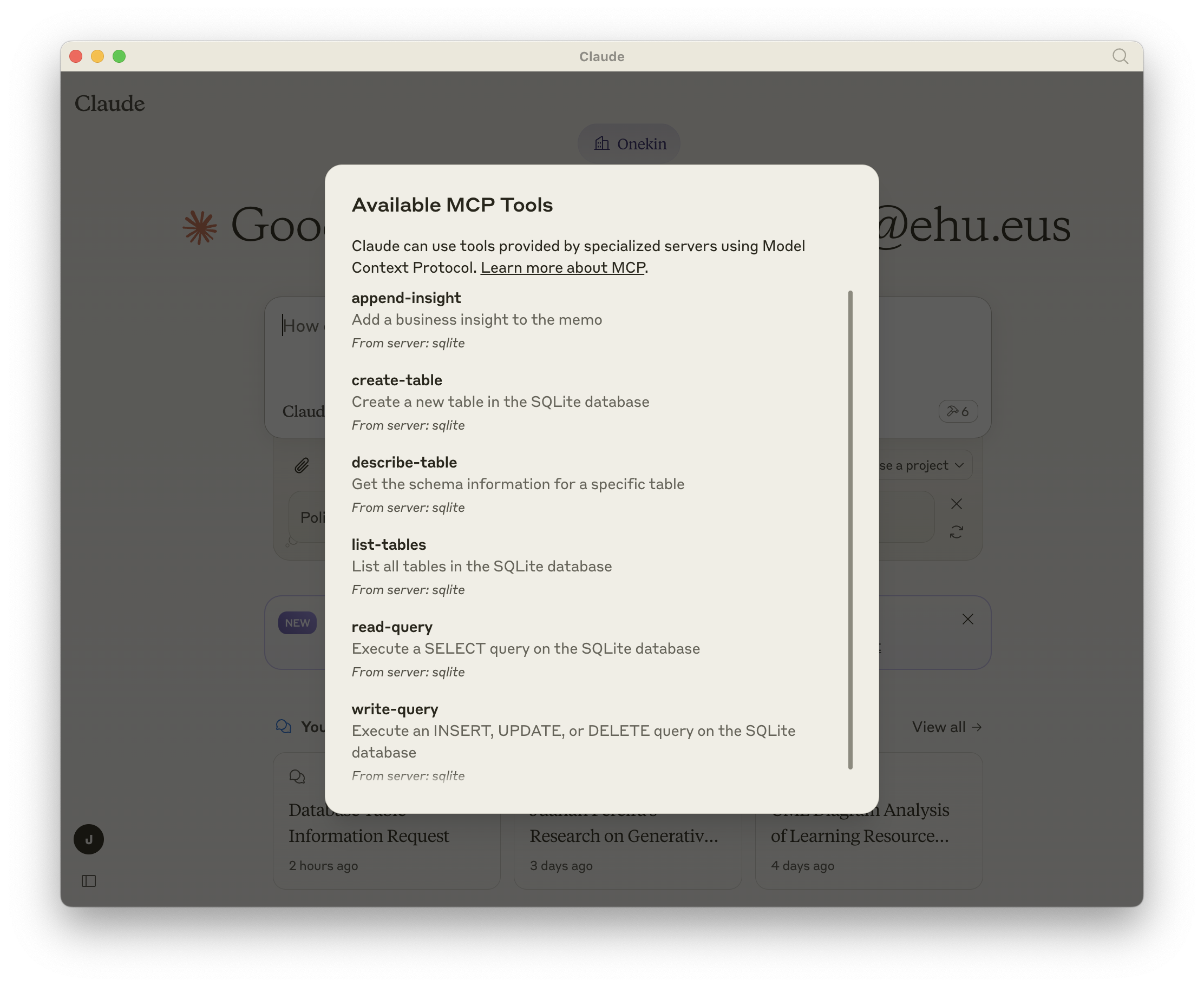
Y si abres un nuevo chat, tendrías que ver 6 tools disponibles:
Ahora podemos hacerle preguntas a Claude al respecto de la BBDD sqlite, por ejemplo:
¿Cuántas tablas hay en la base de datos? ¿Puedes listarlas?
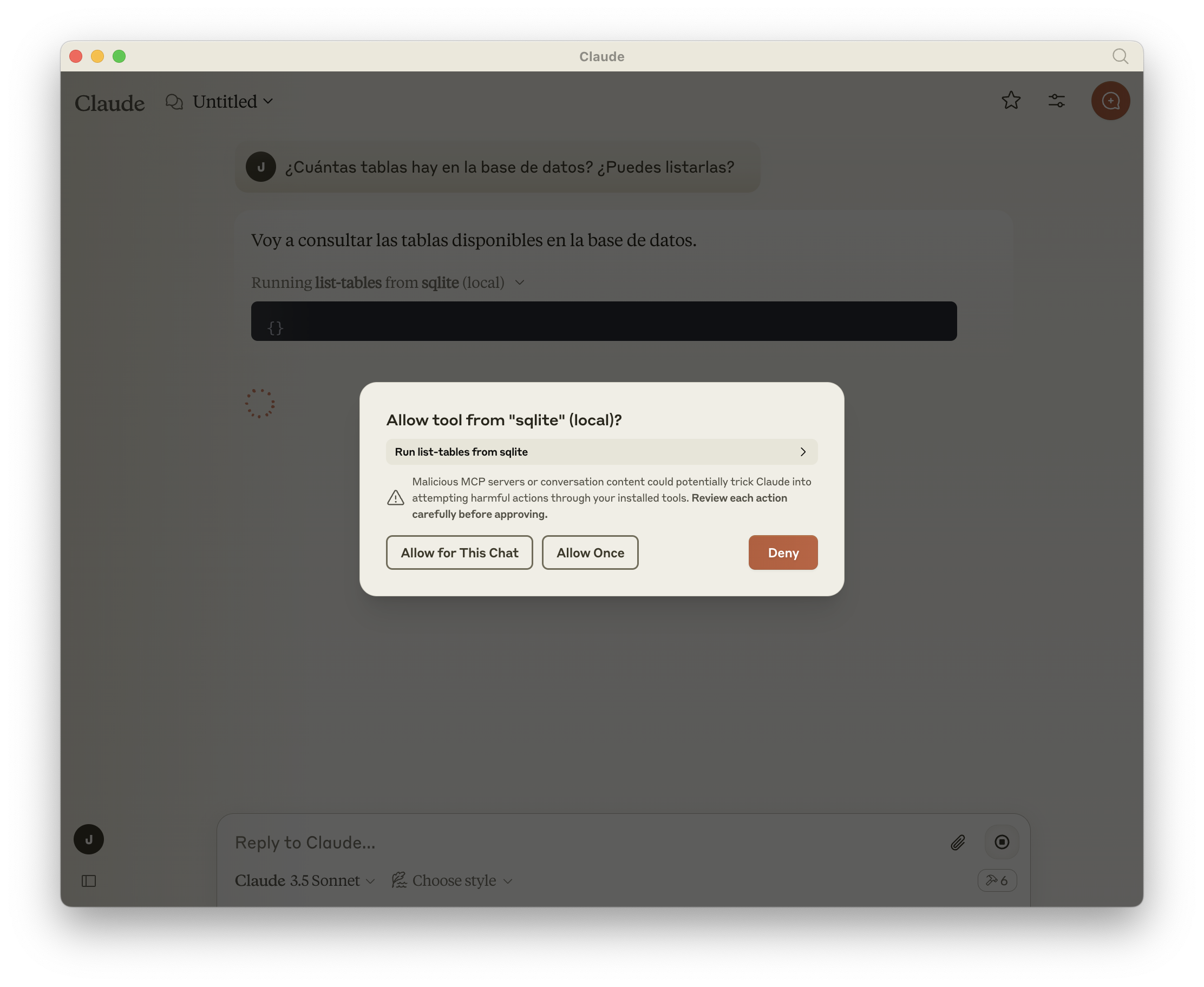
La primera vez Claude te pedirá permiso de ejecución:
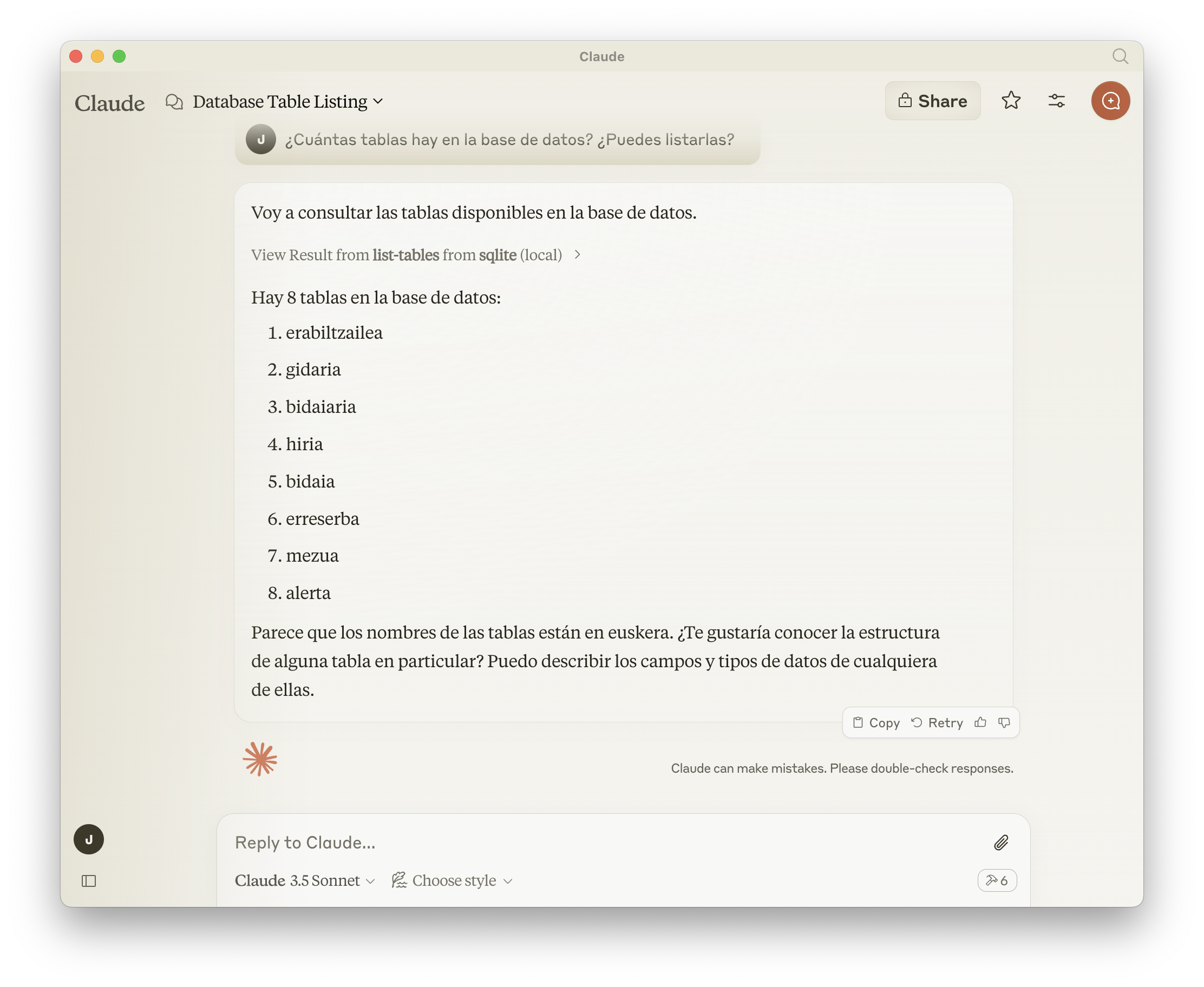
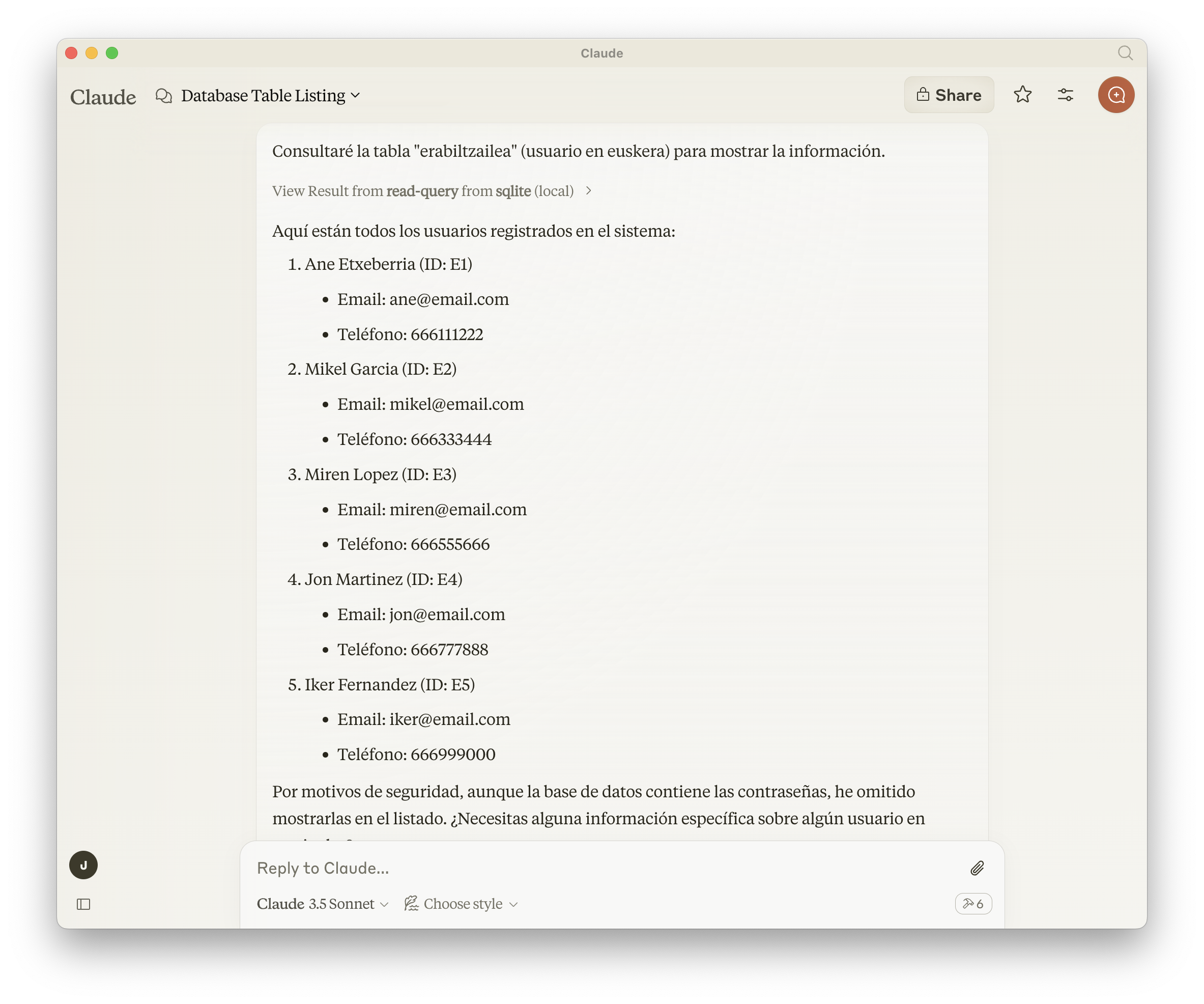
Y a continuación ejecutará el comando list-tables disponible a través de MCP: (y efectivamente, las tablas que le he pasado están en un sqlite de un proyecto en Euskera 🙂
Podemos pedir que nos liste los usuarios (tabla erabiltzailea):
Es curioso el último párrafo, donde se niega a mostrar el contenido de la columna de passwords por motivos de seguridad.
Debugging
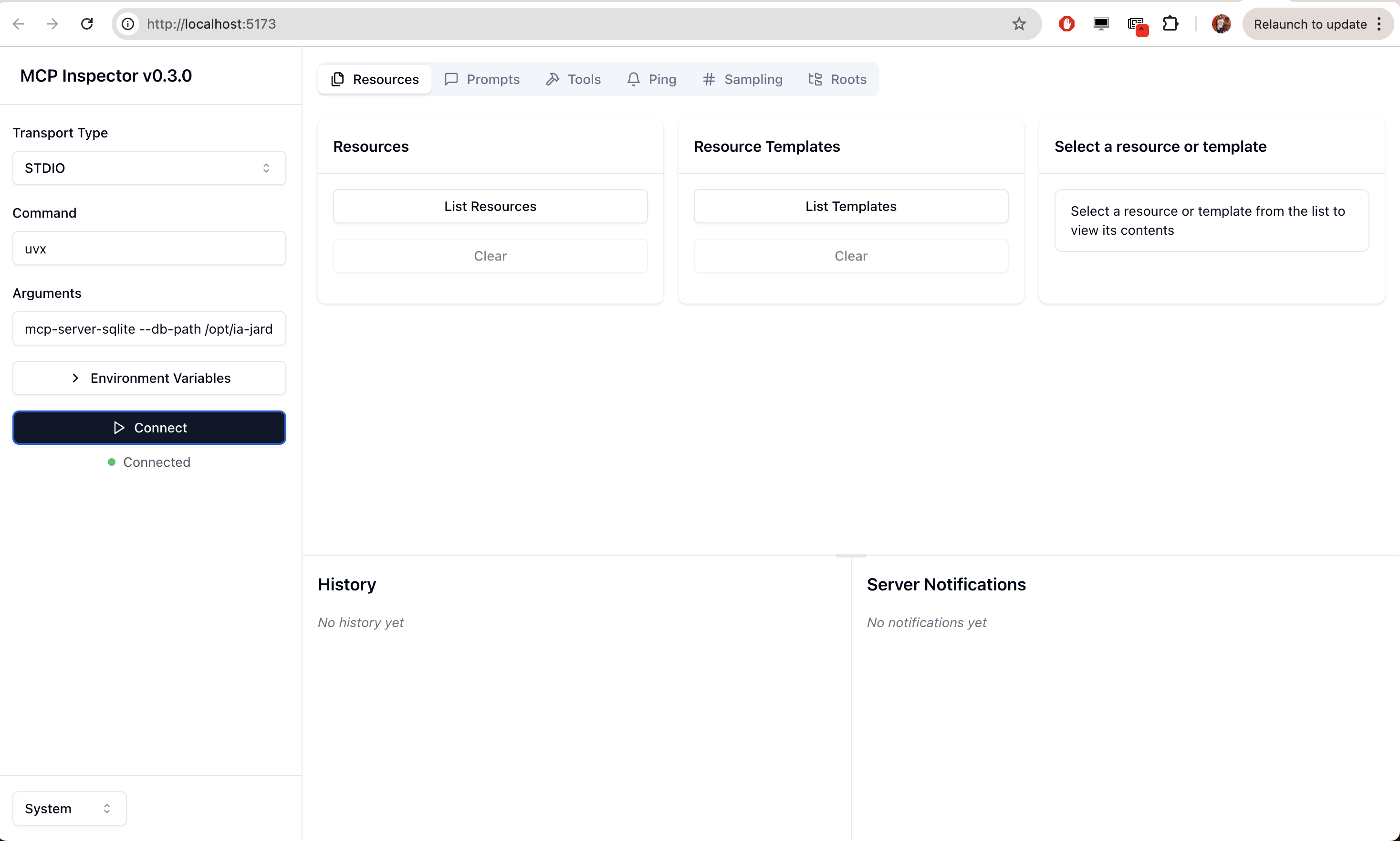
MCP ofrece una herramienta web llamada mcp-inspector que nos permite depurar un servicio MCP desde el navegador. Por ejemplo, si quisiéramos ver qué ofrece el servidor mcp-server-sqlite, podríamos lanzar el siguiente comando:
Desde donde podríamos ver los recursos ofrecidor por ese servidor:
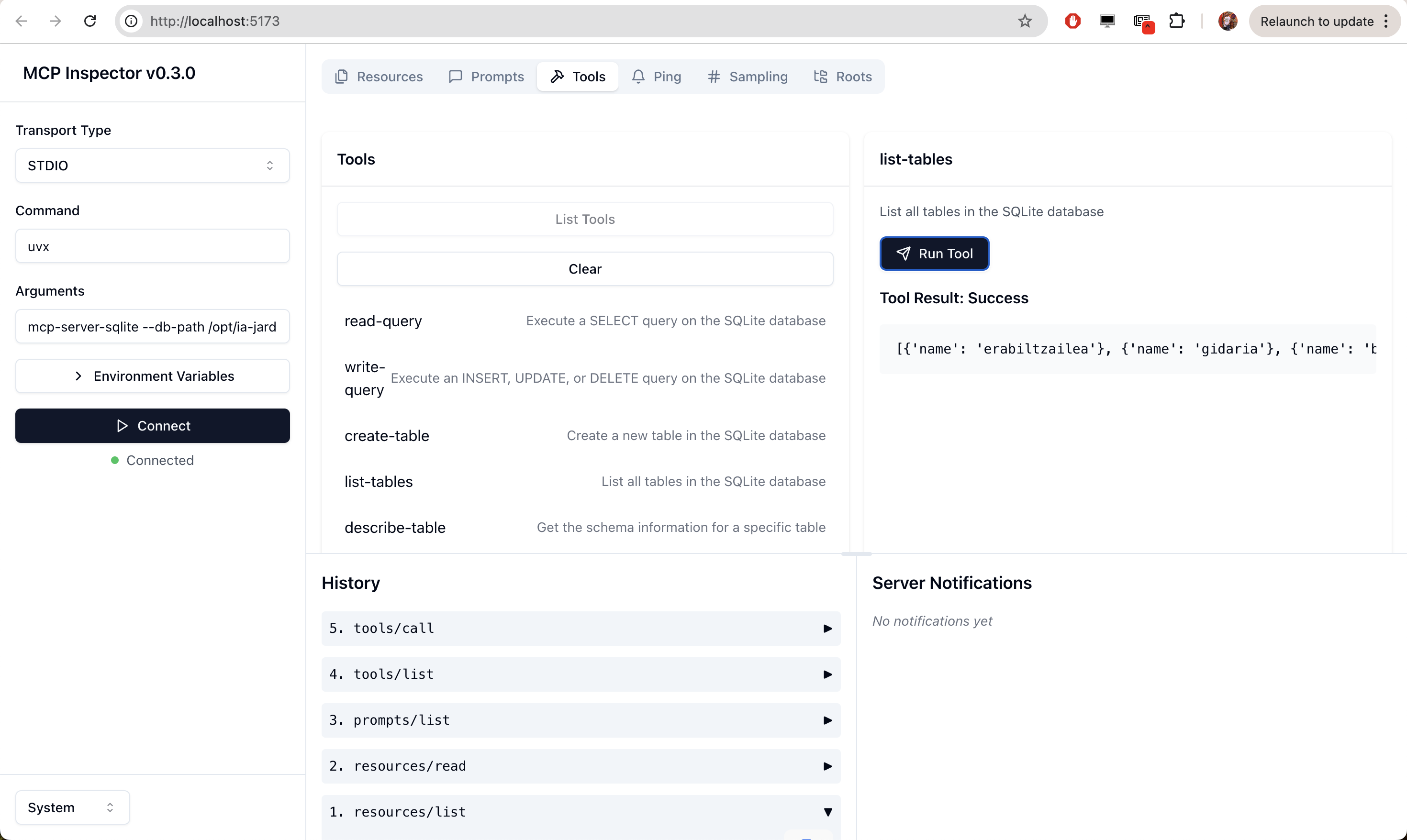
Por ejemplo, probar las herramientas desde el navegador, así:
Troubleshooting
Si no te sale el icono de MCP en el chat, prueba lo siguiente.
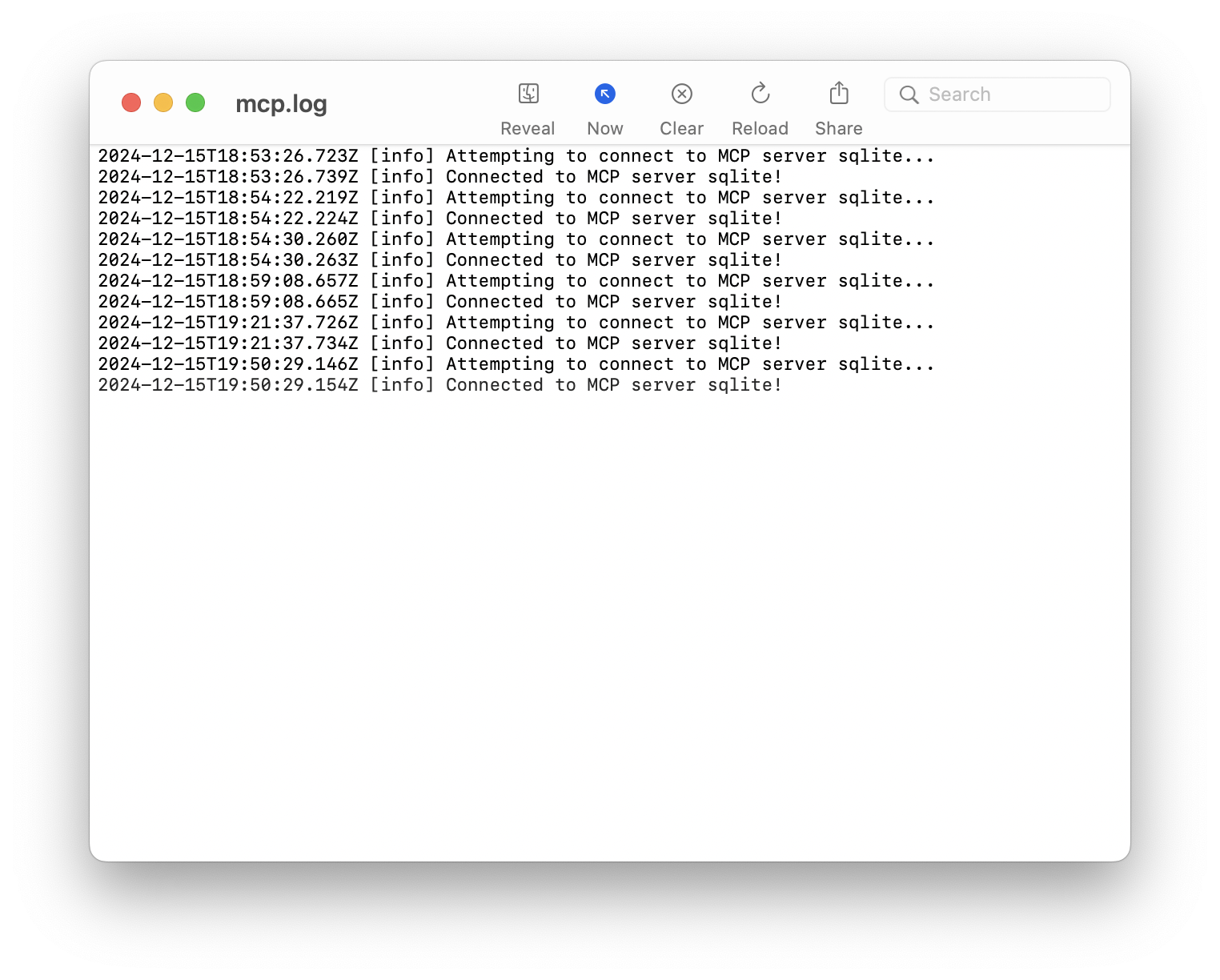
Activa el Developer Mode para ver los logs de MCP:
Te mostrará por defecto el mcp.log. Pero si pulsas sobre el nombre con Cmd+Click izq. verás la ruta a ese log:
Y en ~/Library/Logs/Claude, verás también el fichero mcp-server-sqlite.log
En mi caso, tuve el siguiente problema:
Dado que mcp-server-sqlite requiere una versión de Python superior a la 3.9.13 (la que tengo por defecto en un equipo) es necesario especificar la ruta a un Python más moderno (3.12.14 en mi caso) en el JSON de configuración, así:
Quería ejecutar la siguiente instrucción en SQLite
ALTER TABLE staff
ADD COLUMN IF NOT EXISTS username TEXT NOT NULL DEFAULT "";
pero SQLite no soporta la claúsula IF NOT EXISTS en ADD COLUMN.
Así que le pedí sugerencias a Claude 3.5 Sonnet y GPT-4o.
Ambos estaban de acuerdo en que esto funcionaría:
BEGIN TRANSACTION;
-- Check if the username column exists, if not, add it
SELECT CASE
WHEN COUNT(*) = 0 THEN
'ALTER TABLE staff ADD COLUMN username TEXT NOT NULL DEFAULT ""'
ELSE
'SELECT 1' -- Do nothing
END
FROM pragma_table_info('staff')
WHERE name = 'username';
Parece un buen truco: se comprueba en los metadatos de SQLite a ver si existe una columna username (se cuenta cuántas veces existe) y si el conteo es 0, entonces hay que ejecutar el ADD COLUMN.
Pero, hemos sido engañados.
El SQL es sintácticamente correcto pero la orden dentro del THEN es simplemente para mostrar un string, no para ejecutar el ALTER TABLE.
Cuando te digan que los ingenieros software no existirán en 5 años, acuérdate de esto. O de esto otro:
Great illustration of how much depth there is to what we do as engineers behind just “writing code” – understanding why localhost:3000 isn’t something you can share involves understanding URLs, clients, servers, networking, DNS… https://t.co/bPbjJ5zO0N