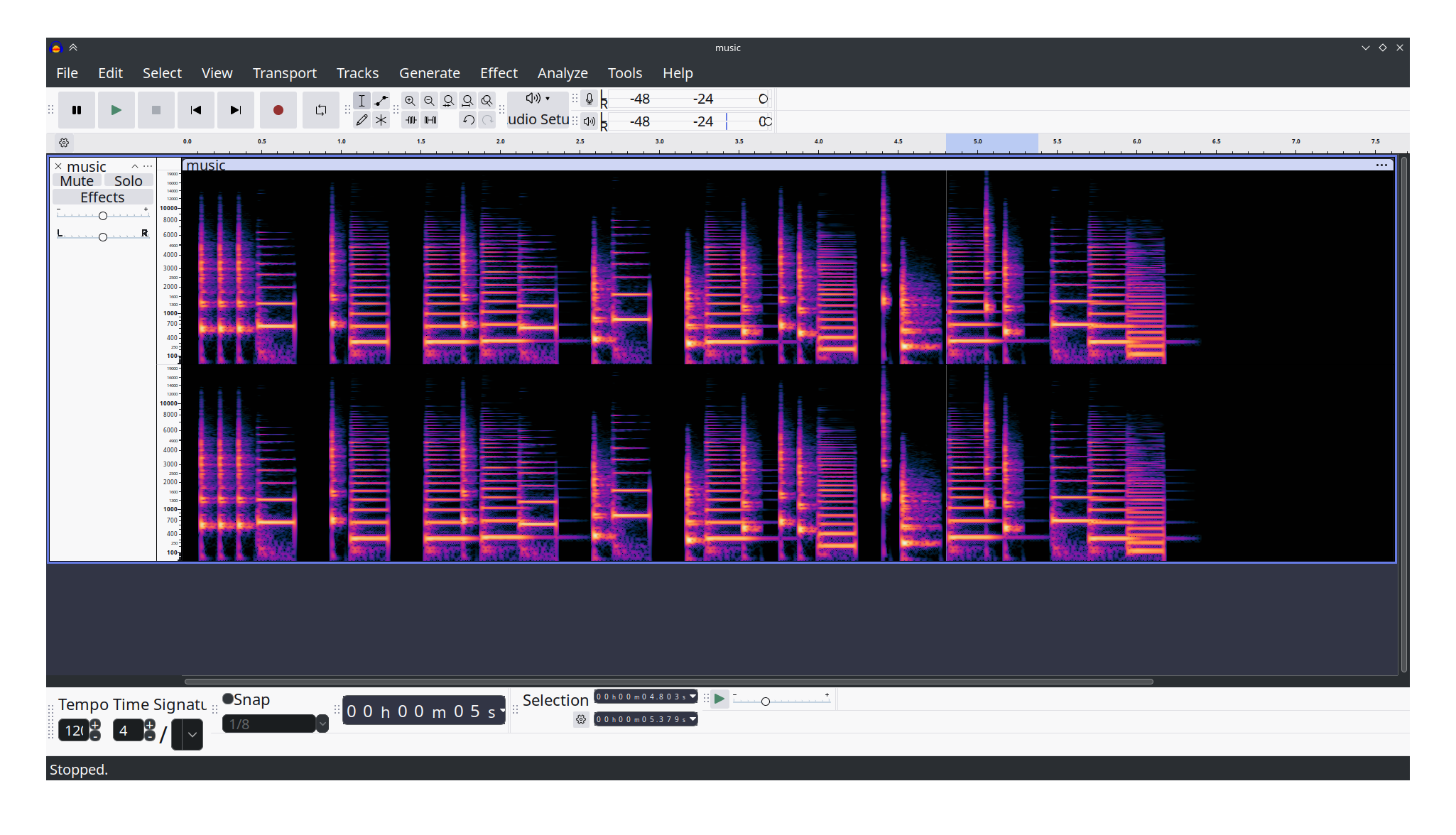
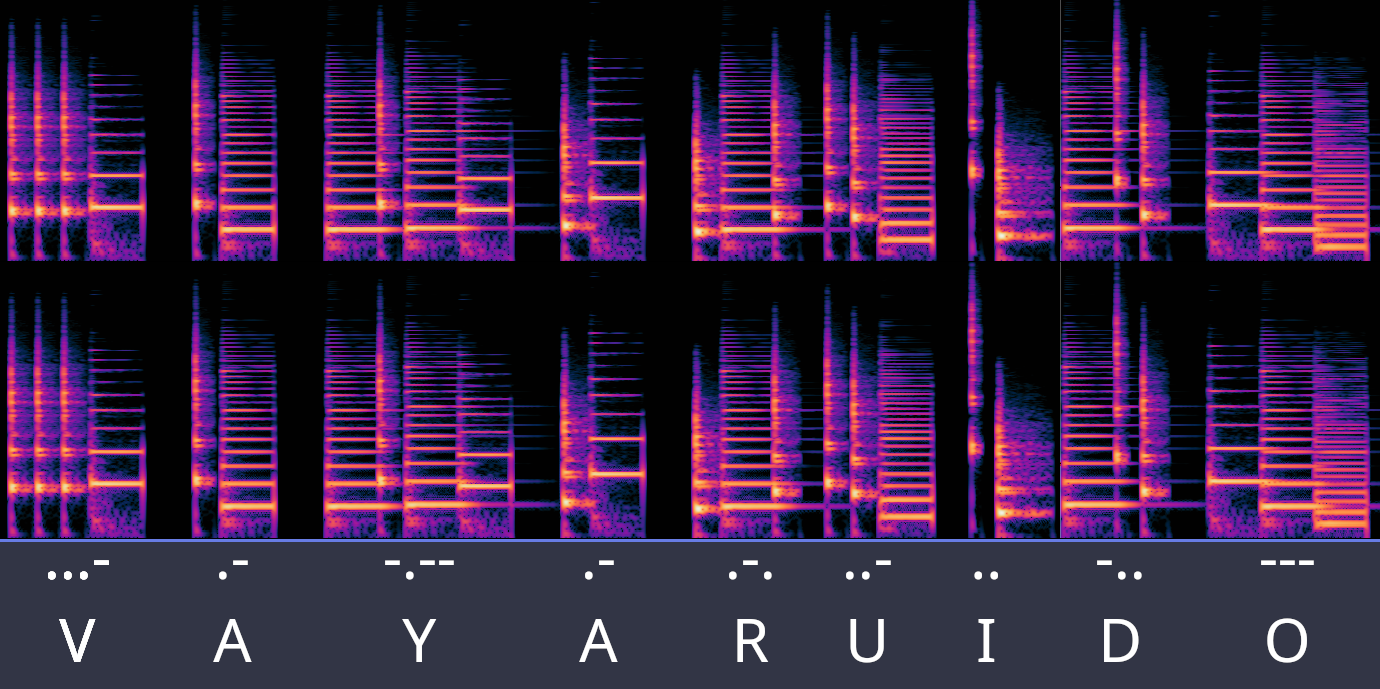
Nota: Este WriteUp ha sido desarrollado por Owen, del equipo basados. ¡Muchas gracias por la colaboración! (y si alguien más quiere participar, será bienvenido 🙂
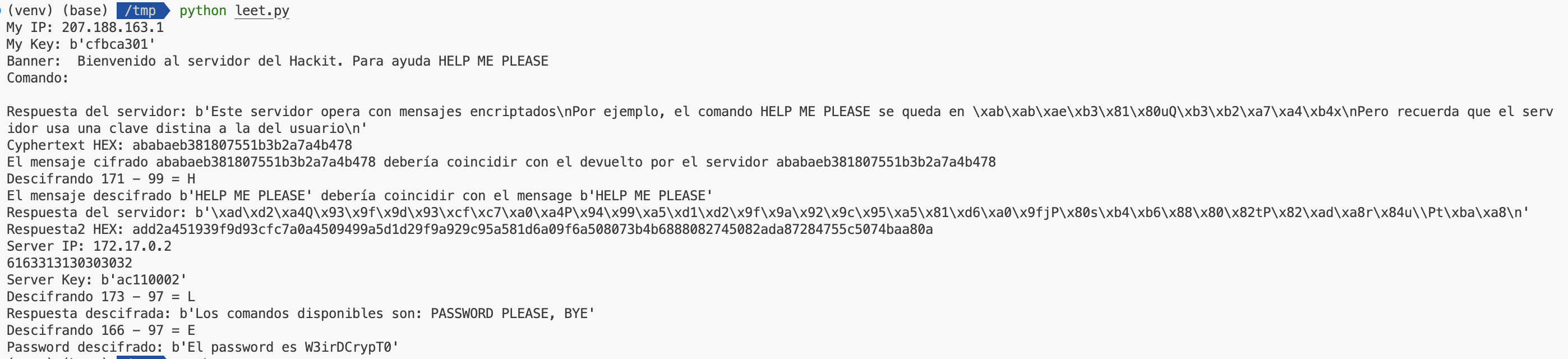
Este tercer nivel, aunque era relativamente sencillo, quizá más que el anterior, no lo han resuelto tantos equipos.

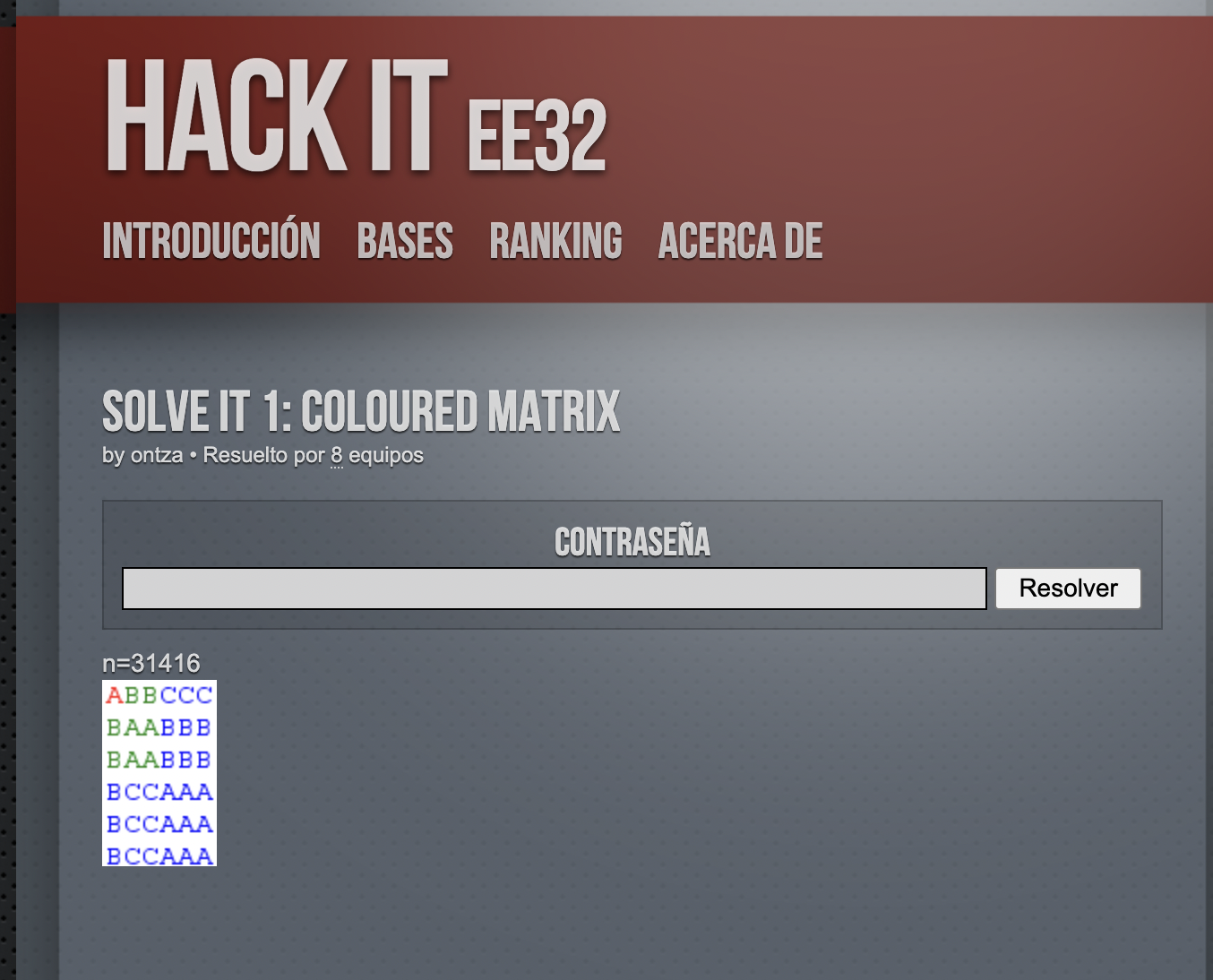
“1111111111111111111 tres primos son y juntos les gusta ir”.
La primera pregunta que nos hicimos: ¿este número, interpretado como decimal, es primo? Sí, lo es.
La segunda: ¿este número, interpretado como binario, es también primo? Si lo pasamos de binario a decimal, obtenemos 524287, que también es primo.
Tenemos dos primos, nos falta el tercero. Si contamos el número de unos, observamos que son 19, así que parece que lo tenemos.
Recapitulando, tenemos 3 primos:
- 1111111111111111111
- 524287
- 19
También sabemos que les gusta ir juntos, pero no sabemos en qué orden. Podemos ir problando, aunque, por ser ordenados, podría tener sentido que fueran de menor a mayor, tal que así:
195242871111111111111111111
Ahí está la respuesta que buscábamos; los tres primos, juntos, en familia.